标签:
写在前面的话
查询容易,优化不易,且写且珍惜
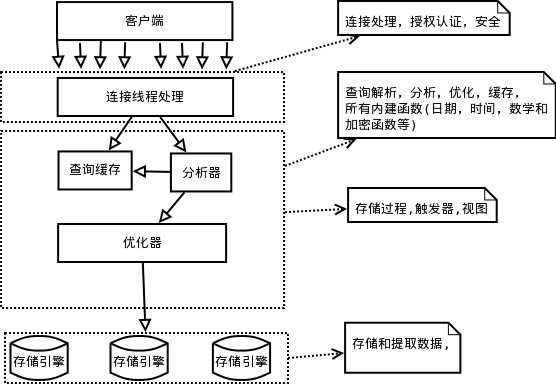
从MySQL逻辑架构来看,MySQL有三层架构,第一层连接,第二层查询解析、分析、优化、视图、缓存,第三层,存储引擎
从数据结构角度
1、B+树索引(O(log(n))):关于B+树索引,可以参考 MySQL索引背后的数据结构及算法原理
2、hash索引:
a 仅仅能满足"=","IN"和"<=>"查询,不能使用范围查询
b 其检索效率非常高,索引的检索可以一次定位,不像B-Tree 索引需要从根节点到枝节点,最后才能访问到页节点这样多次的IO访问,所以 Hash 索引的查询效率要远高于 B-Tree 索引
c 只有Memory存储引擎显示支持hash索引
3、FULLTEXT索引(现在MyISAM和InnoDB引擎都支持了)
4、R-Tree索引(用于对GIS数据类型创建SPATIAL索引)
从物理存储角度
1、聚集索引(clustered index)
2、非聚集索引(non-clustered index)
从逻辑角度
1、主键索引:主键索引是一种特殊的唯一索引,不允许有空值
2、普通索引或者单列索引
3、多列索引(复合索引):复合索引指多个字段上创建的索引,只有在查询条件中使用了创建索引时的第一个字段,索引才会被使用。使用复合索引时遵循最左前缀集合
4、唯一索引或者非唯一索引
5、空间索引:空间索引是对空间数据类型的字段建立的索引,MYSQL中的空间数据类型有4种,分别是GEOMETRY、POINT、LINESTRING、POLYGON。
MYSQL使用SPATIAL关键字进行扩展,使得能够用于创建正规索引类型的语法创建空间索引。创建空间索引的列,必须将其声明为NOT NULL,空间索引只能在存储引擎为MYISAM的表中创建
CREATE TABLE table_name[col_name data type] [unique|fulltext|spatial][index|key][index_name](col_name[length])[asc|desc] 1、unique|fulltext|spatial为可选参数,分别表示唯一索引、全文索引和空间索引; 2、index和key为同义词,两者作用相同,用来指定创建索引 3、col_name为需要创建索引的字段列,该列必须从数据表中该定义的多个列中选择; 4、index_name指定索引的名称,为可选参数,如果不指定,MYSQL默认col_name为索引值; 5、length为可选参数,表示索引的长度,只有字符串类型的字段才能指定索引长度; 6、asc或desc指定升序或降序的索引值存储
1、基数很低的字段不创建索引,更新非常频繁的字段不适合创建索引
2、MySQL不支持bitmap索引
3、采用第三方系统实现 Text/Blob 的全文索引(Sphinx、Coreseek、Lucene、ElashSearch)
4、常用的 where、ORDER BY 、GROUP BY 、DISTINCT 字段要建立索引
5、索引不能太多,会有负作用
6、多使用联合索引、少使用独立索引
7、字符型可创建前缀索引(如 username 字段 80% 的数据都小于18个字符,那么可以创建18个字符的前缀索引
8、字段的顺序对组合索引效率有至关重要的作用,过滤效果越好的字段需要更靠前
最左前缀匹配原则,非常重要的原则,mysql会一直向右匹配直到遇到范围查询(>、<、between、like)就停止匹配,比如a = 1 and b = 2 and c > 3 and d = 4 如果建立(a,b,c,d)顺序的索引,d是用不到索引的,如果建立(a,b,d,c)的索引则都可以用到,a,b,d的顺序可以任意调整尽量的扩展索引,不要新建索引。比如表中已经有a的索引,现在要加(a,b)的索引,那么只需要修改原来的索引即可=和in可以乱序,比如a = 1 and b = 2 and c = 3 建立(a,b,c)索引可以任意顺序,mysql的查询优化器会帮你优化成索引可以识别的形式
9、MySQL只对以下操作符才使用索引
<,<=,=,>,>=,between,like(不以通配符%或_开头的情形)10、不要过度索引,只保持所需的索引。每个额外的索引都要占用额外的磁盘空间,并降低写操作的性能。 在修改表的内容时,索引必须进行更新,有时可能需要重构,因此,索引越多,所花的时间越长。
1、通过索引扫描的记录数超过30%会进行全表扫描
2、第一个索引列使用范围查询不能使用索引
3、内存表使用Hash进行全表扫描
4、ORDER BY 、GROUP BY Hash索引只能进行等于/不等于的检索
5、SELECT … WHERE key1 = ? ORDER BY key2 ASC 对于key1和key2上的索引,查询优化器会自己判断用哪个(只能用到一个)
6、表关联字段类型要一样(包括长度),否则会有类型转换
7、使用函数时不能用到索引( WHERE func(key1) = ? 不能用到)( WHERE key1 + 1 = ? 不能用到)(WHERE key1 = ? + ? 可以用到)
1、增,删,改都需要修订索引,索引存在额外的维护成本
2、查找翻阅索引系统需要消耗时间,索引存在额外的访问成本
3、索引系统需要一个地方来存放,索引存在额外的空间成本
mysqlidxchx/pt-index-usage/userstat/check-unused-keys
1、mysqlidxchx工具很长时间没有更新,但主要用来分析general log、slow.log,来判断实例中那个索引是可以删除,但这个工具没有经过实战,风险很大。
2、pt-index-usage原理来类似mysqlidxchx,执行过程中性能消耗比较严重,如果要在生产库上部署,最好在凌晨业务低锋时使用,pt-index-usage只支持slow.log格式的文件,如果要全面分析整个实例索引使用情况,需要long_query_time设置成0,才能把所以的sql记录下来,但同时会对磁盘空间造成压力,同时pt-index-usage对大文件分析就是件痛苦的事。当然pt-index-usage可以考虑部分表索引使用情况的确认。
3、最看好的userstat,收集信息性能优越,成本低。这个patch是google贡献的(userstat_running),percona把它改名成userstat,默认是不开启的,开启是会收集客户端、索引、表、线程信息存储在CLIENT_STATISTICS、INDEX_STATISTICS、TABLE_STATISTICS、THREAD_STATISTICS。Userstat的bug导致的问题太严重,直接导致mysql crash,到目前淘宝生产环境还没有使用。
4、Ryan Lowe的check-unused-keys脚本基于userstat,能够比较方便输出需要删除的索引。
参考地址
http://www.mysqlperformanceblog.com/2012/06/30/find-unused-indexes/
http://www.mysqlperformanceblog.com/2012/12/05/quickly-finding-unused-indexes-and-estimating-their-size/
http://www.mysqlperformanceblog.com/2009/06/26/check-unused-keys-a-tool-to-interact-with-index_statistics/
标签:
原文地址:http://www.cnblogs.com/chenpingzhao/p/4950943.html