标签:
特征选择的一般过程:
1.生成子集:搜索特征子集,为评价函数提供特征子集
2.评价函数:评价特征子集的好坏
3.停止准则:与评价函数相关,一般是阈值,评价函数达到一定标准后就可停止搜索
4.验证过程:在验证数据集上验证选出来的特征子集的有效性
1.生成子集
搜索算法有 完全搜索、启发式搜索、随机搜索 三大类。
(1)完全搜索
<1>宽搜(Breadth First Search):时间复杂度高,不实用
<2>分支界限搜索(Branch and Bound):其实就是宽搜加上深度的限制
<3>定向搜索(Beam Search):其实算是启发式的一种,对宽搜加上每次展开结点数的限制以节省时间空间,对于展开那几个结点由启发式函数确定
<4>最优优先算法(Best First Search):也是有启发式函数,对宽搜取最优结点进行展开
(2)启发式搜索
<1>序列前向选择(SFS , Sequential Forward Selection)
特征子集X从空集开始,每次选择能使得评价函数J(X)最优的一个特征x加入,其实就是贪心算法,缺点是只加不减
<2>序列后向选择(SBS , Sequential Backward Selection)
和SFS相反,从特征全集开始,每次选择使评价函数J(X)最优的特征x剔除,也是贪心,缺点是只减不增
<3>双向搜索(BDS , Bidirectional Search)
SFS和SBS同时开始,当两者搜索到同一个特征子集时停止。
<4>增L去R选择算法(LRS , Plus-l Minus-R Selection)
形式一:从空集开始,每次加L个特征,去除R个特征,使得J最优
形式二:从全集开始,每次去除R个特征,加入L个特征,使J最优。
<5>序列浮动选择(Sequential Floating Selection)
该算法由增L去R发展,不同之处在于L和R是会变化的,它结合了序列前后向选择、增L去R的特点并弥补了缺点。
①序列浮动前向选择(SFFS , Sequential Floating Forward Selection)
从空集开始,每轮选择子集x加入使得J最优,再选择子集z剔除使得J最优。
②序列浮动后向选择(SFBS , Sequential Floating Backward Selection)
与①相反,从全集开始,先剔除再加入。
<6>决策树(Decision Tree Method , DTM)
一般使用信息增益作为评价函数,待决策树生长后再进行剪枝,最后留下的叶子就是特征子集。
(3)随机算法
<1>随机产生序列选择算法(RGSS, Random Generation plus Sequential Selection)
随机产生特征子集,然后执行SFS或SBS,可作为SFS和SBS的补充,用于跳出局部最优解。
<2>模拟退火算法( SA, Simulated Annealing )
模拟退火可在一定程度上避免陷入局部最优,但是可能难以求解。
<3>遗传算法(GA, Genetic Algorithms)
首先随机产生一批特征子集,并用评价函数给这些特征子集评分,然后通过交叉、突变等操作繁殖出下一代的特征子集,并且评分越高的特征子集被选中参加繁殖的概率越高。这样经过N代的繁殖和优胜劣汰后,种群中就可能产生了评价函数值最高的特征子集。
2.评价函数
用于评价特征子集的好坏,主要分为Filter和Wrapper
(1)Filter
其实就是预处理,利用训练集自身的特点筛选出特征子集后再送入分类器进行学习,与分类器的选择无关。
(2)Wrapper
封装器用选取的特征子集对训练集进行分类,分类的精度作为衡量特征子集好坏的标准。
常见的评价函数有:
(1)相关性
基于假设:好的特征子集所包含的特征应该是与分类的相关度较高,而特征之间相关度较低
线性相关系数
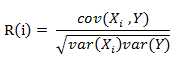
(2)距离/相似度
基于假设:好的特征子集应该使得属于同一类的样本距离尽可能小,属于不同类的样本之间的距离尽可能远
常用相似度计算
(3)信息增益
之前讲过了,信息增益体现特征子集的出现对系统信息量的增加。
(4)一致性
若样本1与样本2属于不同的分类,但在特征A、 B上的取值完全一样,那么特征子集{A,B}不应该选作最终的特征集。
(5)分类器错误率
用分类的精度作为评判标准。
对于文本分类的文本特征提取,大都采用Filter方法进行特征提取,无论是基于词频的VSM方法还是基于语义的方法,大都是通过计算公式对每个特征项进行打分,
最后选择得分最高的k项形成特征子集。Wrapper方法用的很少,我自己认为是文本特征项数量巨大,对于上述不断生成特征子集再去评价实在太慢了,wrapper方法
也是因为效率不高而被舍弃。
注:上述特征选择常用算法综述摘自博客 http://www.cnblogs.com/heaad/archive/2011/01/02/1924088.html
标签:
原文地址:http://www.cnblogs.com/IvanSSSS/p/4951758.html