标签:
原文:你真的会玩SQL吗?透视转换透视转换是一种行列互转的技术,在转过程中可能执行聚合操作,应用非常广泛。
本章与 你真的会玩SQL吗?数据聚合 内容比较重要,还涉及到 你真的会玩SQL吗?Case的用法 的内容,都可以一起看。
下面的例子将使用OpenSchema表,运行创建表:
CREATE TABLE OpenSchema( objectid INT NOT NULL, attribute VARCHAR(30) NOT NULL , VALUE SQL_VARIANT NOT NULL, PRIMARY KEY (objectid,attribute) ) GO INSERT INTO OpenSchema(objectid,attribute,VALUE) VALUES (1,N‘attr1‘,CAST(CAST(‘ABC‘ AS VARCHAR(10)) AS SQL_VARIANT)), (1,N‘attr2‘,CAST(CAST(10 AS INT) AS SQL_VARIANT)), (1,N‘attr3‘,CAST(CAST(‘20070101‘ AS SMALLDATETIME) AS SQL_VARIANT)), (2,N‘attr2‘,CAST(CAST(12 AS INT) AS SQL_VARIANT)), (2,N‘attr3‘,CAST(CAST(‘20090101‘ AS SMALLDATETIME) AS SQL_VARIANT)), (2,N‘attr4‘,CAST(CAST(‘Y‘ AS CHAR(1)) AS SQL_VARIANT)), (2,N‘attr5‘,CAST(CAST(13.7 AS NUMERIC(9,3)) AS SQL_VARIANT)), (3,N‘attr1‘,CAST(CAST(‘xyz‘ AS VARCHAR(10)) AS SQL_VARIANT)), (3,N‘attr2‘,CAST(CAST(20 AS INT) AS SQL_VARIANT)), (3,N‘attr3‘,CAST(CAST(‘20080101‘ AS SMALLDATETIME) AS SQL_VARIANT))
将会得到以下输出:
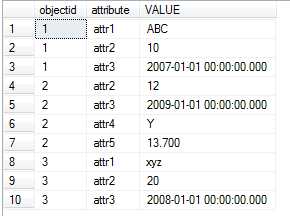
以上VALUE属性保存了多个不同数据类型的值,可以实现要添加新的属性时不用添加列,直接保存。
但是这样查询我们希望把数据旋转为每个属性占一列的传统方式,然后再保存到临时表中处理后续查询称之为透视转换技术。在这里需要回看一下 你真的会玩SQL吗?之逻辑查询处理阶段 对于理解透视转换的步骤是有帮助的。
来看一看经典的行转列实例,如要得到下面的结果怎么做:
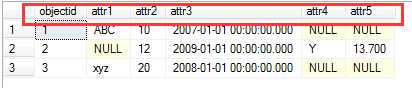
透视转换的步骤:
参考SQL:

SELECT objectid , MAX(CASE WHEN attribute = ‘attr1‘ THEN VALUE END) AS attr1 , MAX(CASE WHEN attribute = ‘attr2‘ THEN VALUE END) AS attr2 , MAX(CASE WHEN attribute = ‘attr3‘ THEN VALUE END) AS attr3 , MAX(CASE WHEN attribute = ‘attr4‘ THEN VALUE END) AS attr4 , MAX(CASE WHEN attribute = ‘attr5‘ THEN VALUE END) AS attr5 FROM OpenSchema GROUP BY objectid
这里也可以用PIVOT,不过PIVOT不支持动态透视转换,除了使代码更短外没有什么显著差异,这里就不演示了。
逆透视转换
即列旋转行,常用于规范化数据,如将上面的结果逆转换。
创建表:
CREATE TABLE PvtOpenSchema( objectid INT NOT NULL, attr1 VARCHAR(10) NULL , attr2 VARCHAR(10) NULL , attr3 VARCHAR(10) NULL , attr4 VARCHAR(10) NULL , attr5 VARCHAR(10) NULL )
将上面的结果插入此表:
INSERT INTO PvtOpenSchema ( objectid,attr1,attr2,attr3,attr4,attr5 ) SELECT objectid , MAX(CASE WHEN attribute = ‘attr1‘ THEN CAST( VALUE AS VARCHAR(10)) END) AS attr1 , MAX(CASE WHEN attribute = ‘attr2‘ THEN CAST( VALUE AS VARCHAR(10)) END) AS attr2 , MAX(CASE WHEN attribute = ‘attr3‘ THEN CAST( VALUE AS VARCHAR(10)) END) AS attr3 , MAX(CASE WHEN attribute = ‘attr4‘ THEN CAST( VALUE AS VARCHAR(10)) END) AS attr4 , MAX(CASE WHEN attribute = ‘attr5‘ THEN CAST( VALUE AS VARCHAR(10)) END) AS attr5 FROM OpenSchema GROUP BY objectid
结果:
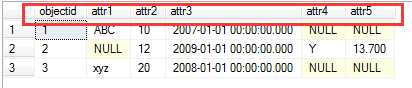
若做到逆转换,将每个objectid 和每个attribute生成结果集中的一行
第一步是为每个甚而行生成5个属性副本,可以通过基础表和每个属性占一行虚拟辅助表执行交叉联接来实现,然后用select 返回objectid和attribute,用case计算值。
可能数据源中会得到与NULL值,如1的attr4,所以还需要对结果进行过滤掉Value为NULL的。
代码如下:
SELECT objectid , attribute , VALUE FROM ( SELECT objectid , attribute , CASE attribute WHEN ‘attr1‘ THEN attr1 WHEN ‘attr2‘ THEN attr2 WHEN ‘attr3‘ THEN attr3 WHEN ‘attr4‘ THEN attr4 WHEN ‘attr5‘ THEN attr5 END AS VALUE FROM PvtOpenSchema CROSS JOIN ( SELECT ‘attr1‘ AS attribute UNION ALL SELECT ‘attr2‘ UNION ALL SELECT ‘attr3‘ UNION ALL SELECT ‘attr4‘ UNION ALL SELECT ‘attr5‘ ) AS attributes ) AS T WHERE VALUE IS NOT NULL
这里可以使用UNPIVOT表运算符,查询将更简单:
SELECT objectid , attribute , VALUE FROM PvtOpenSchema UNPIVOT ( VALUE FOR attribute IN ( attr1, attr2, attr3, attr4, attr5 ) ) AS a
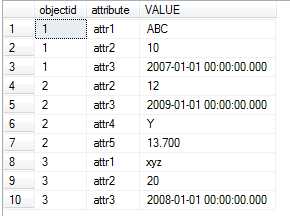
UNPIVOT会在一个逻辑处理中删除NULL行。
以上只是一个简单的示例,即使现在理解了但在多变的实际应用可能就会迷惘,那时再来对比看看此例。
练习:
姓名 科目 成绩 张三 语文 80 张三 数学 90 张三 物理 85 李四 语文 85 李四 物理 82 李四 英语 90 李四 政治 70 王五 英语 90
将上表转换为:
姓名 数学 物理 英语 语文 政治 李四 0 82 90 85 70 王五 0 0 90 0 0 张三 90 85 0 80 0
标签:
原文地址:http://www.cnblogs.com/lonelyxmas/p/4957970.html
