标签:
接上文
找到接口之后连续查看了几个图片,结果发现图片都很小,于是用手机下载了一个用wireshark查看了一下url

之前接口的是
imges_min下载的时候变成了images
soga,知道之后立马试了一下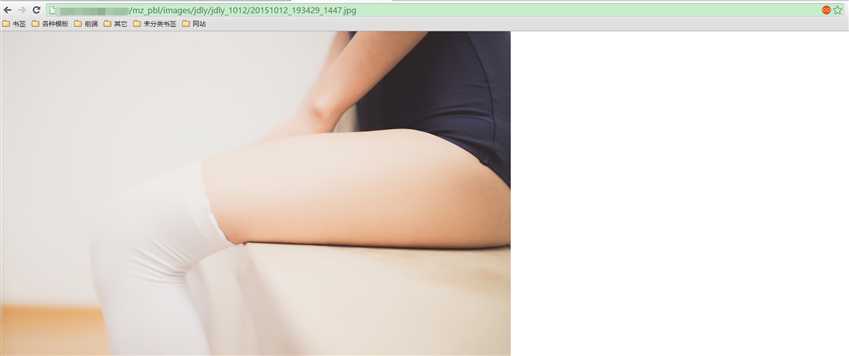
果然有效,
但是总不能一个一个的查看下载吧
于是连夜写了个java爬虫
下面是代码
package com.feng.main; import java.io.File; import java.io.FileOutputStream; import java.io.IOException; import java.io.InputStream; import java.io.InputStreamReader; import java.util.ArrayList; import java.util.Date; import java.util.List; import java.util.regex.Matcher; import java.util.regex.Pattern; import org.apache.http.HttpEntity; import org.apache.http.HttpResponse; import org.apache.http.client.HttpClient; import org.apache.http.client.config.RequestConfig; import org.apache.http.client.methods.HttpGet; import org.apache.http.impl.client.HttpClients; public class DownLoadImg { List<String> imgFormat = new ArrayList<String>(); DownLoadImg(){ imgFormat.add("jpg"); imgFormat.add("jpeg"); imgFormat.add("png"); imgFormat.add("gif"); imgFormat.add("bmp"); } /** * 开启总方法 * @param startUrl */ public void start(String startUrl){ String content = getContent(startUrl); // 获取所有图片链接 List<String> urls = getAllImageUrls(content); for (int i = 0; i < urls.size(); i++) { downloadImage(urls.get(i)); } System.out.println("----------------------------------"); System.out.println("------------下载成功-------------"); System.out.println("----------------------------------"); } /** * 获取HttpEntity * @return HttpEntity网页实体 */ private HttpEntity getHttpEntity(String url){ HttpResponse response = null;//创建请求响应 //创建httpclient对象 HttpClient httpClient = HttpClients.createDefault(); HttpGet get = new HttpGet(url); RequestConfig requestConfig = RequestConfig.custom() .setSocketTimeout(5000) //设置请求超时时间 .setConnectionRequestTimeout(5000) //设置传输超时时间 .build(); get.setConfig(requestConfig);//设置请求的参数 // try { response = httpClient.execute(get); } catch (IOException e) { // TODO Auto-generated catch block e.printStackTrace(); } //获取返回状态 200为响应成功 // StatusLine state = response.getStatusLine(); //获取网页实体 HttpEntity httpEntity = response.getEntity(); return httpEntity; // try { // return httpEntity.getContent(); // } catch (IllegalStateException | IOException e) { // // TODO Auto-generated catch block // e.printStackTrace(); // } // return null; } /** * 获取整个html以String形式输出 * @param url * @return */ private String getContent(String url){ HttpEntity httpEntity = getHttpEntity(url); String content = ""; try { InputStream is = httpEntity.getContent(); InputStreamReader isr = new InputStreamReader(is); char[] c = new char[1024]; int l = 0; while((l = isr.read(c)) != -1){ content += new String(c,0,l); } isr.close(); is.close(); } catch (IllegalStateException | IOException e) { // TODO Auto-generated catch block e.printStackTrace(); } return content; } /** * 通过开始时的content获取所有图片的地址 * @param startUrl * @return */ private List<String> getAllImageUrls(String content){ String regex = "http://([\\w-]+\\.)+[\\w-]+(/[\\w-./?%&=]*)?(.jpg|.mp4|.rmvb|.png|.mkv|.gif|.bmp|.jpeg|.flv|.avi|.asf|.rm|.wmv)+"; // String regex = "http://www.sslingyu.com/mz_pbl/images_min\\S*\\.jpg"; Pattern p = Pattern.compile(regex); Matcher m = p.matcher(content); List<String> urls = new ArrayList<String>(); while(m.find()){ String url = m.group(); //将获取到的url转换成高清 url = getHDImageUrl(url); System.out.println("获取的url:"+url+"\n是否符合标准:"+isTrueUrl(url)); if(isTrueUrl(url)){ urls.add(url); } } System.out.println("----------------------------------"); System.out.println("--------获取所有url成功----------"); System.out.println("----------------------------------"); return urls; } /** * 下载图片 * @param url * @param is */ private int downloadImage(String url){ try{ HttpEntity httpEntity = getHttpEntity(url); long len = httpEntity.getContentLength()/1024; System.out.println("下载的文件大小为:"+len+"k"); if(len < 150){ System.out.println("Warring:文件太小,不予下载--------"); return 0; } String realPath = getRealPath(url); String name = getName(url); System.out.println("文件夹路径:"+realPath); System.out.println("文件名字:"+name); InputStream is = httpEntity.getContent(); //此方法不行 // System.out.println(is.available()/1024+"k"); int l = 0; byte[] b = new byte[1024]; FileOutputStream fos = new FileOutputStream(new File(realPath+"/"+name)); while((l = is.read(b)) != -1){ fos.write(b, 0, l); } fos.flush(); fos.close(); is.close(); System.out.println("下载:"+url+"成功\n"); }catch(Exception e){ System.out.println("下载:"+url+"失败"); e.printStackTrace(); } return 1; } /** * 创建并把存储的位置返回回去 * @param url * @return */ private String getRealPath(String url){ Pattern p = Pattern.compile("images/[a-z]+/[a-z_0-9]+"); Matcher m = p.matcher(url); String format = getName(url).split("\\.")[1]; String path = null; //说明是图片 if(imgFormat.contains(format)){ path = "media/images/"; }else{ path = "media/video/"; } path += url.split("/")[(url.split("/").length-2)]; if(m.find()){ path = m.group(); }; //添加盘符 path = "D:/"+path; File file = new File(path); if(!file.exists()){ file.mkdirs(); } return path; } /** * 获取文件名 * @param url * @return */ private String getName(String url){ // s3.substring(s3.lastIndexOf("/")+1) return url.substring(url.lastIndexOf("/")+1); } /** * 获取高清图片地址 * 就是把images_min换成了Images * @param url * @return */ private String getHDImageUrl(String url){ if(url.contains("images_min")){ return url.replace("images_min", "images"); } return url; } /** * 判断url的格式是否正确,必须以http开头,以.jpg结尾 * @param url * @return */ private boolean isTrueUrl(String url){ return url.matches("^http://([\\w-]+\\.)+[\\w-]+(/[\\w-./?%&=]*)?(.jpg|.mp4|.rmvb|.png|.mkv|.gif|.bmp|.jpeg|.flv|.avi|.asf|.rm|.wmv)+$"); } }
上面是下载部分,下面是主函数
package com.feng.main; public class MainTest { public static void main(String[] args) { DownLoadImg down = new DownLoadImg(); String startUrl = "http://www.example.com"; down.start(startUrl); } }
整个爬虫的功能是爬去整个网页(单个网页)中所有图片与视频,
通过正则获取网页中的url,而且还特地增加了将images_min换成images的方法。
换成接口链接开始运行!!!
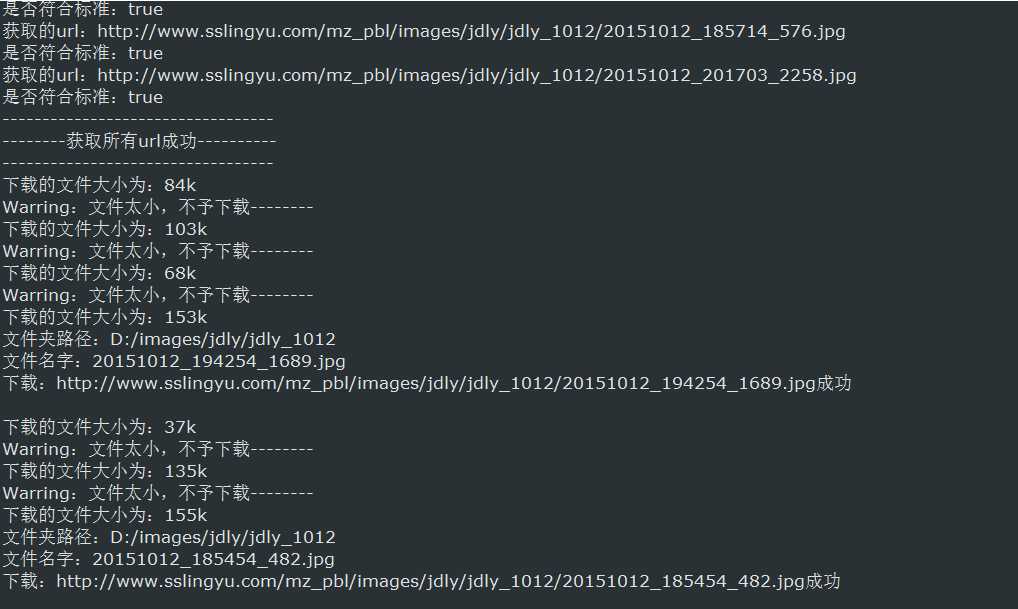
等了几十分钟下完之后打开文件夹
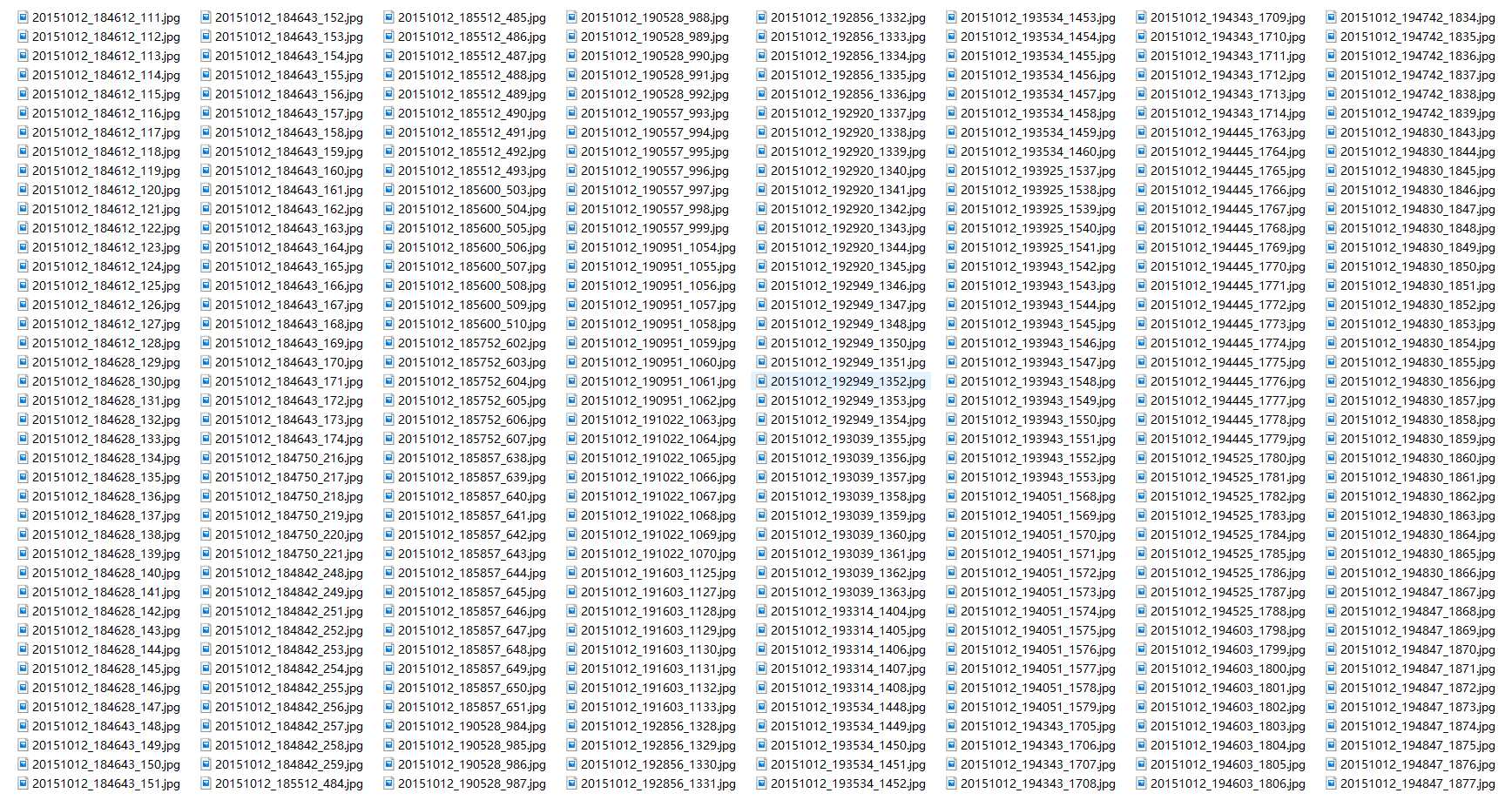
很好很好,下载完成。
《未完待续》
通过wireshark获取应用接口并使用爬虫爬取网站数据(二)
标签:
原文地址:http://www.cnblogs.com/weikongziqu/p/4962946.html