标签:
本系列文章着重学习和研究OpenStack Swift,包括环境搭建、原理、架构、监控和性能等。
(1)OpenStack + 三节点Swift 集群+ HAProxy + UCARP 安装和配置
(2)原理、架构和性能
(3)监控
Swift 的总体架构非常的清晰和独立:
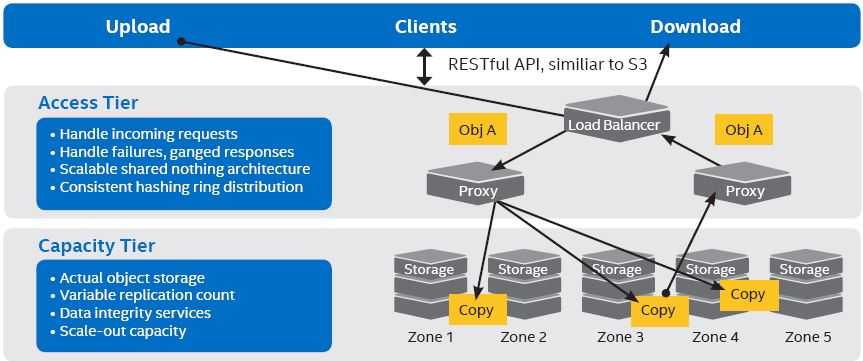
| # | 分层(Tier) | 组件(Service) | 功能(Function) | 特性 | 部署考量 |
| 1 | 访问层(Access Tier) | Load Balancer | 硬件(比如F5)或者软件(比如HAProxy)负载均衡器,将客户端的请求按照配置的策略分配到无状态的 proxy service。 | 按照实际需求选择硬件还是软件LB | |
| 2 | Proxy Server |
|
是 CPU 和网络带宽敏感的 |
|
|
| 3 | 存储层 (Capactity Tier) |
Account Server |
提供 Account 操作 REST API | 是磁盘性能和网络带敏感的 |
|
| 4 | Container Server | 提供 Container 操作 REST API | |||
| 5 | Object Server | 提供 Object 操作 REST API | |||
| 6 | Consistency Servers | 包括 Replicators, Updaters 和 Auditors 等后台服务,用于保证 object 的一致性 |
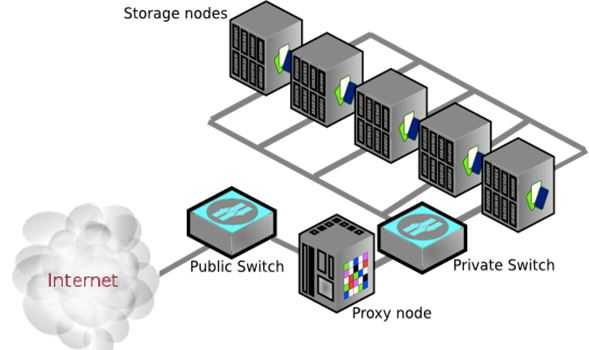
这是一张比较经典的 Swift 物理部署图:
以一个对外提供对象存储服务的集群为例,其网络架构可以为:
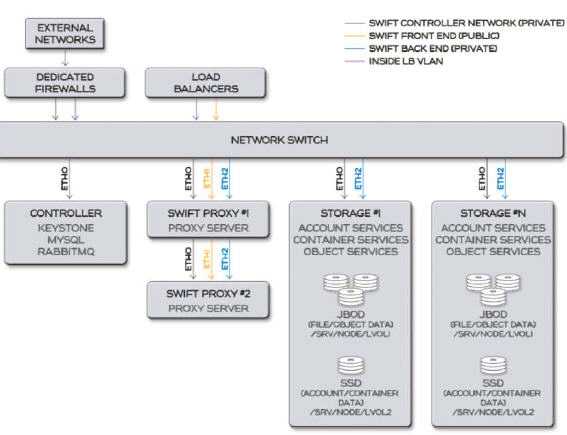
在网络带宽选择上,
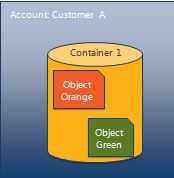
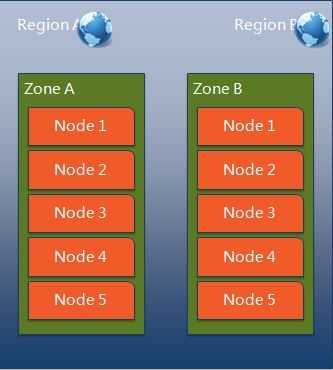
Swift 的数据模型使用了以下三个概念来(见下图1):
(图1) (图2)
Swift 保存每个对象为多分拷贝,它按照物理位置的特点,尽量将这些拷贝放在不同的物理位置上,来保证数据的地理位置上的可靠性。它主要考虑以下几种位置属性:
Swift 在确定对象的放置位置时,会尽量将对象及其拷贝放在不会同时损失的物理位置上。见上图2.
对象及其拷贝放置在某个磁盘上后,Swift 会使用Replicators, Updaters 和 Auditors 等后台服务来保证其数据的最终一致性。
其中,Replicator 服务以可配置的间隔来周期性启动,默认是 30s,它以 replication 为最小单位,以 node 为范围,周期性地执行数据拷贝。详细过程请参考文末的参考文档。考虑到Swift 实现的是最终一致性而非强一致性,它不合适于需要数据强一致性的应用,比如银行存款和订票系统等。需要做 replication 的情形包括但不限于:
Swift 根据由管理员配置的 Ring 使用相对简单直接的算法来确定对象的存放位置。对象会以文件的形式保存在本地文件系统中,使用文件的扩展属性来保存对象的元数据,因此,Swift 需要支持扩展属性的文件系统,目前官方推荐是 XFS。
简单来说,Swift 的 Proxy Server 根据account,container 和 object 各自的 Ring 来确定各自数据的存放位置,其中 account 和 container 数据库文件也是被当作对象来处理的。
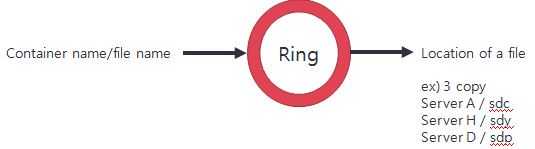
因此,Swift 需要 Ring 的配置文件分布在所有 Proxy节点上。同时,Consistency Servers 需要它来确定后台对象拷贝的位置,因此也需要部署在所有存储节点上。Ring 以文件的形式保存:
在分析 Ring 是如何工作的之前,先来看看 Ring 的几个关键配置:
管理员使用 Swift 提供的 ring 生成工具(swift-ring-builder,位于源码的bin目录下,是swift最基本的命令,它与swift/common/ring/下的文件一起实现ring文件创建,添加,平衡,等操作),加上各种配置参数,得出该ring的内容。以 Object ring 为例,
root@swift1:/etc/swift# swift-ring-builder object.builder
object.builder, build version 6
1024 partitions, 3.000000 replicas, 1 regions, 3 zones, 6 devices, 0.00 balance, 0.00 dispersion
The minimum number of hours before a partition can be reassigned is 1
The overload factor is 0.00% (0.000000)
Devices: id region zone ip address port replication ip replication port name weight partitions balance meta
0 1 1 9.115.251.235 6000 9.115.251.235 6000 sdb1 100.00 512 0.00
1 1 1 9.115.251.235 6000 9.115.251.235 6000 sdc1 100.00 512 0.00
2 1 2 9.115.251.234 6000 9.115.251.234 6000 sdb1 100.00 512 0.00
3 1 2 9.115.251.234 6000 9.115.251.234 6000 sdc1 100.00 512 0.00
4 1 3 9.115.251.233 6000 9.115.251.233 6000 sdb1 100.00 512 0.00
5 1 3 9.115.251.233 6000 9.115.251.233 6000 sdc1 100.00 512 0.00
该 Ring 的配置为:1 个 region,3 个 zone,3 个 node,6 个磁盘,每个磁盘上 512 个分区。
内部实现上,Swift 将该 Ring 的配置保存在其 _replica2part2dev 数据结构中:

其读法是:
因此,Swift 通过该数据结构可以方便地查到某个 replica 应该通过哪些节点上的存储服务放在哪个 disk 上。
除了生成 Ring 外,对 Ring 的另一个重要操作是 rebalance(再平衡)。在你修改builder文件后(例如增减设备),该操作会重新生成ring文件,使系统中的partition分布平衡。当然,在 rebalance 后,需要重新启动系统的各个服务。 详情可以参考 OpenStack Swift源码分析(二)ring文件的生成。
当收到一个需要保存的 object 的 PUT 请求时,Proxy server 会:
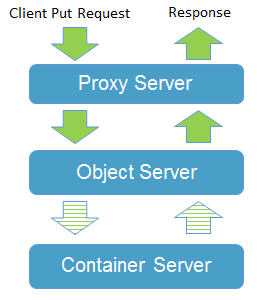
当 Proxy server 收到一个获取对象的 GET 请求时,它:
(1)(2)(3)(4)同前面的 PUT 请求,确定存放所有 replica 的 所有磁盘
(5)排序这些 nodes,尝试连接第一个,如果成功,则将二进制数据返回客户端;如果不成功,则尝试下一个。直到成功或者都失败。
应该说该过程蛮简单直接,这也符合Swift的总体设计风格。至于具体的哈希算法实现,有兴趣可以看相关论文。大致来说,它实现的是 “unique-as-possible” 即 “尽量唯一” 的算法,按照 Zone,Node 和 Disk 的顺序。对于一个 replica,Swift 首先会去选择一个没有该对象 replica 的 zone,如果没有这样的 zone,选择一个已使用 zone 中的没用过的 node,如果没有这样的 node,就选择已使用的 node 上的一个没使用过的 disk。
Swift 对于小的文件,是不分段直接存放的;对于大的文件(大小阈值可以配置,默认是 5G),系统会自动将其分段存放。用户也可以指定分段的大小来存放文件。比如对于 590M 的文件,设置分段大小为 100M,则会被分为 6 段被并行的(in parallel)上传到集群之中:
root@controller:~/s1# swift upload container1 -S 100000000 tmpubuntu tmpubuntu segment 5 tmpubuntu segment 2 tmpubuntu segment 4 tmpubuntu segment 1 tmpubuntu segment 3 tmpubuntu segment 0 tmpubuntu root@controller:~/s1# swift list container1 1 admin-openrc.sh cirros-0.3.4-x86_64-disk.raw tmpubuntu
从 stat 中可以看出它使用一个 manifest 文件来保存分段信息:
root@controller:~/s1# swift stat container1 tmpubuntu Account: AUTH_dea8b51d28bf41599e63464828102759 Container: container1 Object: tmpubuntu Content Type: application/octet-stream Content Length: 591396864 Last Modified: Fri, 13 Nov 2015 18:31:53 GMT ETag: "fa561512dcd31b21841fbc9dbace118f" Manifest: container1_segments/tmpubuntu/1446907333.484258/591396864/100000000/ Meta Mtime: 1446907333.484258 Accept-Ranges: bytes Connection: keep-alive X-Timestamp: 1447439512.09744 X-Trans-Id: txae548b4b35184c71aa396-0056462d72
但是 list 的时候依然只看到一个文件,原因是因为 manifest 文件被保存到一个独立的 container (container1_segments)中。这里可以看到 6 个对象:
root@controller:~/s1# swift list container1_segments tmpubuntu/1446907333.484258/591396864/100000000/00000000 tmpubuntu/1446907333.484258/591396864/100000000/00000001 tmpubuntu/1446907333.484258/591396864/100000000/00000002 tmpubuntu/1446907333.484258/591396864/100000000/00000003 tmpubuntu/1446907333.484258/591396864/100000000/00000004 tmpubuntu/1446907333.484258/591396864/100000000/00000005
每个对象大小是100M(考虑到存储效率,不建议每个对象大小小于100M):
root@controller:~/s1# swift stat container1_segments tmpubuntu/1446907333.484258/591396864/100000000/00000000 Account: AUTH_dea8b51d28bf41599e63464828102759 Container: container1_segments Object: tmpubuntu/1446907333.484258/591396864/100000000/00000000 Content Type: application/octet-stream Content Length: 100000000
而且用户可以单独操作比如修改某一段。Swift 只会负责将所有段连接为用户所见的大的对象。
关于大文件支持的更多细节,可以参考 官方文档 和 Rackspace 的文档。从上面的描述可以看出,Swift 对文件分段的支持是比较初级的(固定,不灵活),因此,已经有人提出 Object stripping (对象条带化)方案,比如下面的方案,不知道是否已经支持还是将要支持。

通过将对象存放在不同物理位置上的 Region 内,可以进一步增强数据的可用性。其基本原则是:对于 N 份 replica 和 M 个 region,每个 region 中的 replica 数目为 N/M 的整数,剩余的 replica 在 M 个region 中随机选择。以 N = 3, M = 2 为例,一个 region 中有 1 个 replica,另一个 region 中有两个 replica,如下图所示:
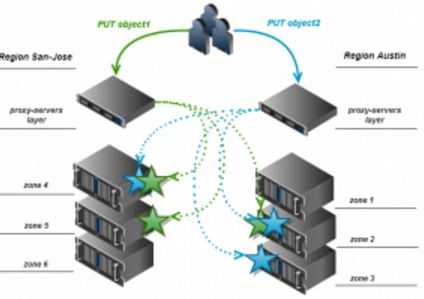
对于一个 PUT 操作来说,Proxy server 只会将 replica 写入它所在的 region 中的 node,远端 region 中的 replica 由 replicator 写入。因此,Swift 的算法应该尽量保证 proxy server 所在的 region 中的 replica 份数相对多一些,这也称为 replica 的 proxy server 亲和性。
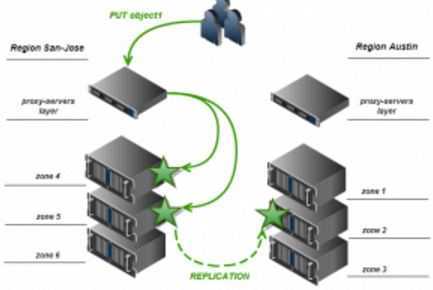
显然,跨 region 的数据复制加重了对网络带宽的要求。
两种形式的 Region:
(1)远端 region 实时写入 replica
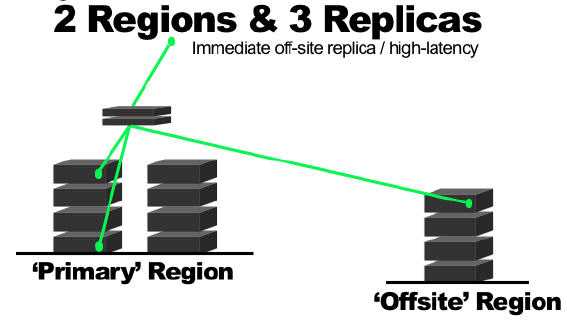
(2)远端 region 的 replica 异步写入
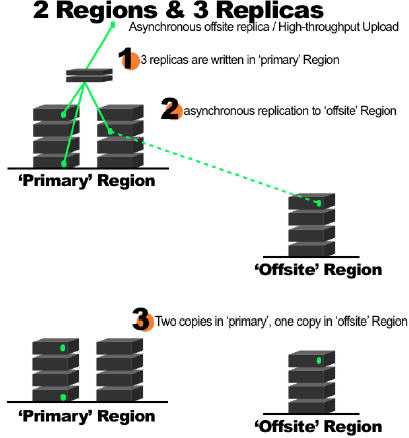
上面的描述中,一个Swift 集群只支持一套 Ring 配置,这意味着整个机器的配置是唯一的。类似 Ceph 中 pool 的定义,Swift 在 2.0 版本(包含在 OpenStack Juno 版本中)中,添加了一个非常大的功能:Storage policy。在新的实现中,一个 Swift 可以由多套 Ring 配置,每套 Ring 的配置可以不相同。比如,Ring 1 保存 3 份对象拷贝,Ring 2 保存 2 份对象拷贝。几个特点:
通过应用该新的功能,Swift 用户可以制定不同的存储策略,来适应不同应用的存储需求。比如对关键应用的数据,制定一个存储策略使得数据被保存到 SSD 上;对于一般关键性的数据,指定存储策略使得数据只保存2份来节约磁盘空间。比如说:
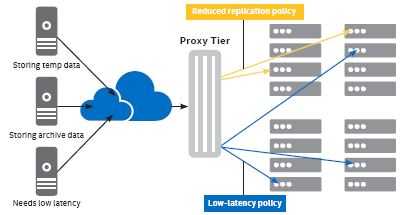
详细信息,请参考 OpenStack 官方文档 和 SwiftStack 官方文档。
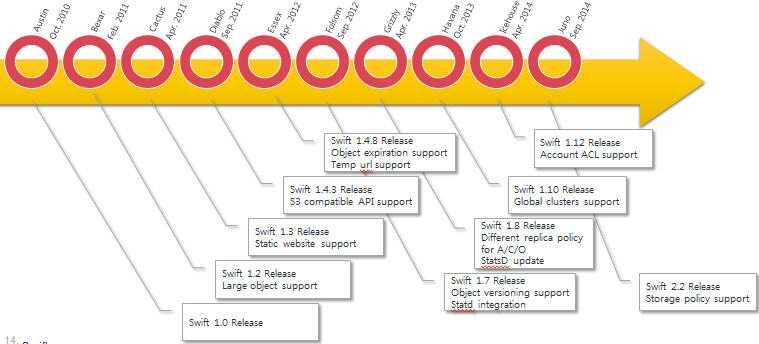
(1)Large object support
(2)Static web hosting
(3) S3 compatible API
(4) Object expiration
(5) Temp url
(6) Global cluster
(7) Storage policy
Swift现在支持纠删码(EC)存储策略类型。这样部署人员、以极少的RAW容量达到极高的可用性,如同在副本存储中一样。然而,EC需要更多的CPU和网络资源,所以并不适合所有应用场景。EC非常适合在一个独立的区域内极少访问的、大容量数据。
Swift纠删码的实现对于用户是透明的。对于副本存储和纠删码存储的类型,在API上没有任何区别。
为了支持纠删码,Swift现在需要依赖PyECLib和liberasurecode。liberasurecode是一个可插件式的库,允许在你选择的库中实现EC算法。
更详细文档请参阅 http://swift.openstack.org/overview_erasure_code.html
复合型令牌允许其他OpenStack服务以客户端名义将数据存储于Swift中,所以无论是客户端还是服务在更新数据时,都不需要双方彼此的授权。
一个典型的例子就是一个用户请求Nova存放一个VM的快照。Nova将请求传递给Glance,Glance将镜像写入Swift容器中的一组对象中。在这种场景下,用户没有来自服务的合法令牌时,无法直接修改快照数据。同样,服务自身也无法在没有用户合法令牌的情况下更新数据。但是数据的确存在于用户的Swift账户中,这样使得账户管理更简单。
更详细的文档请参阅http://swift.openstack.org/overview_backing_store.html
Swift数据的存放位置现在根据硬件权重决定。当前,允许运维人员逐渐的添加新的区域(zones)和地域(regions),而不需要立即触发大规模数据迁移。同时,如果一个集群是非平衡的(例如,在一个区域(zones)的集群中,其中一个的容量是另外一的两倍),Swift会更有效的使用现有空间并且当副本在集群空间不足时发出警告。
区域(regions)之间复制时,每次复制只迁移一个副本。这样远程的区域(region)可以在内部复制,避免更多的数据在广域网(WAN)拷贝。
像往常一样,你能在不影响最终用户体验的前提下,升级到这个版本的Swift。
L版本中Swift 没有加入大的新功能,详细情况可以参考 官方文档。
其它参考文档:
http://www.florentflament.com/blog/openstack-swift-ring-made-understandable.html
https://www.mirantis.com/blog/configuring-multi-region-cluster-openstack-swift/
理解 OpenStack Swift (2):架构、原理及功能 [Architecture, Implementation and Features]
标签:
原文地址:http://www.cnblogs.com/sammyliu/p/4955241.html