标签:
我们知道CHAR(M)和VARCHAR(M)的区别就是VARCHAR(M)是变长的字符串,而CHAR(M)是定长的字符串。我们暂时先不考虑变长和定长的问题,我们先来看一看CHAR(M)和VARCHAR(M)中的M代表的是什么意思。
在oracle中CHAR(M)和VARCHAR(M)中的M代表的是字节数就是这个列占用的最大字节数。而在MySQL中CHAR(M)和VARCHAR(M)中的M代表的是这个列占用的最大字符数。这是什么意思呢?下面我们在MySQL中创建一张表来测试一下就明白了。
DROP TABLE IF EXISTS `char_test`; CREATE TABLE `char_test` ( `ch` char(4) DEFAULT NULL ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
char_test表非常简单,只有一个字段ch,他的类型是CAHR(4),用的是utf-8编码,接下来在char_test表中插入三行数据。

图1:正常插入数据
我们用MySQL提供给我们的函数length(str),和char_length(str),来查看表char_test中的ch字段的字节数和字符数如下:

图2:字节数和字符数
因为是用utf-8编码,utf-8编码中一个英文字符占用1个字节,一个汉字占用3个字节。所以我们看到hi占用的是2个字节,2个字符。非常高兴占用了12个字节,4给字符。所以我们可以知道CHAR(M)中的M是表示最大占用的字符数。如下图3面我们来试一试插入多一点字符的情况。
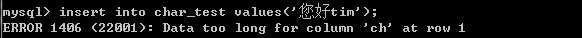
图3:非正常插入
您好tim总共有5个字符,插入就出错了,这是在STRICT_TRANS_TABLES模式下,直接报错了。
VARCHAR(M)和CHAR(M)的情况一样,M也是表示最大的字符数。只是和很多资料上的情况不一样的是VARCHAR(M)中的M取值范围并不是固定的0~65535,而是根据编码不同有所不同。

图4:使用ascii编码

图5:使用默认的utf-8编码
如上图4、5所示,当使用ascii编码的时候,M的取值是0~65535,当使用utf-8编码是时候M的取值范围是0~21845。

图6:VARCHAR(M)官方文档
因为MySQL的官方文档对于VARCHAR的介绍是最大是65535给字节,而utf-8占用的是1~6个字节。而21845*3 = 65535,所以我们也只能猜测在中文环境中MySQL只支持占用3个字节的汉字,因为汉字大多数占3个字节。这样就算是21845个字符全部是汉子都刚好占用65535个字节。
接下来的事情就是,考虑定长和变长的事了。这其实和功能没有太大的关系了,主要是存储和使用效率有关了。
CHAR(M)是定长的,顾名思义就是长度是固定的,这里的长度是指底层存储空间的字节数。例如CHAR(4),根据编码不同MySQL为CHAR(4)分配的就是固定的字节数的存储空间,不管你放‘hi’还是‘非常高兴’,底层都是占用4个字符所占用的字节。不够怎么办?没关系,填充空格。至于查询的时候只要不是PAD_CHAR_TO_FULL_LENGTH模式下,就会把CHAR(M)类型末尾的空格去掉。
VARCHAR(M)是变长的,顾名思义就是长度是可变的,例如:VARCHAR(4),虽然最大的字符数是4但是我如果只存放一个hi,底层就只占用2个字符所占用的字节。
那么问题来了,我们该怎样选择CHAR(M)和VARCHAR(M)呢?这其实是一个比较复杂的问题,考虑到不同的场景和不同的存储引擎,选择是不同的。
如果您对性能没有什么要求,并且也不太想花时间去分析思考这些数据的应用场景,数据的查询和索引效率等的关系,那么直接用VARCHAR(M)吧。
如果您对性能有要求,那么您就可以考虑一下是否对数据进行一些约束,限制一下数据的长度,做一下合理的转换,特别是对一些经常索引和查询的数据。例如:有一张用户表,包含name,address,phone,password等属性。也许就可以把name设置成CHAR类型的因为name显然是经常查询的字段,并且长度比较固定。姓名嘛,一般就是2-4个字符嘛,就算设置大一点,也算是用空间换时间,address看具体的情况,phone没什么说的固定的CHAR(11)一点都不浪费,不要为了怕出错弄一个CHAR(20)这样的类型,因为手机号码有非常明显的数据约束,就算是错误,也是客户端的错误。至于password完全可以考虑学习一下MySQL的做法,直接弄一个CHAR(40),然后用sha1(password)加密在存放。不仅效率高,还很保证了数据的安全性。
标签:
原文地址:http://my.oschina.net/u/2474629/blog/531601