标签:
开篇先自我检讨一下,写了博客几年以来首次试过连续两个月没出过博文,有客观也有主观原因,但是最近这年里博文数量也越来越少,博文的质量也每况日下。希望自己一直能坚持下来,多写写博文,这月尽量多写几篇来弥补上两个月的。
话说我们的DBA妹子离开我们也两月了。在DBA不在的日子里,小伙伴只能靠自己了。但貌似我的数据库技术还是定格在她离开的时候。
她当时教我最厉害的一招利用SQL生成SQL最终执行查询,大致就是通过sys.table查出表名,生成SQL并合并,最后exec执行。感觉还是比较有用。假设数据库中有一堆命名规范且结构相似的表,要查出这批表的数据,就可以考虑一下用这样的方式
首先从把表名查出来
SELECT name FROM sys.tables WHERE name like ‘%表名的模式%‘ AND type= ‘U‘
上面的通配符什么的就不说了,接下来就是要把查询数据的SQL语句拼接出来了。原来还可以这样用,看来以前是没开窍或者是太老实了。
SELECT ‘ UNION SELECT * FROM ‘+ name FROM sys.tables WHERE name like ‘%表名的模式%‘ AND type=‘U‘
这样查询出来的结果就是最终SQL的半成品。但上面我觉得尽量不要用*,这里有表的结构不一样,UNION就会出错了。接下来还需要经过组合和截取,这里就用到了两个函数,一个是 FOR XML PATH(‘‘),另一个是stuff(),顺序是先让上面的结果合并成一个字符串,再去截取。SQL就成下面的样子
DECLARE @sql varchar(max) SET @sql= SELECT ‘ UNION SELECT * FROM ‘+ name FROM sys.tables WHERE name like ‘%表名的模式%‘ AND type=‘U‘ FOR XML PATH(‘‘) Set @sql=stuff(@sql,1,7,‘ ‘) Select @sql
这样就可以把SQL语句显示出来了,需要执行的话只需要exec(@sql)就可以了。
这样语句不光可以用于查询数据,加入我要批量删除某一类的表 这样的操作也可以,但有个弊端,就是varchar(max)的容量有限,假如表或者语句太大,varchar(max)放不下的话,最终执行的SQL肯定达不到效果啦!
在上一家公司里面,彬哥教导我们,不要用子查询,会让查询速度变慢的,但是这位DBA教我用了联表子查询,原本的子查询放在FORM子句中;DBA教导的是把子查询放到JOIN子句中,当我提到说影响效率,DBA说不会,我也不明白了。这种语句说应用场景也比较多,我举个例子。
假如现在有一张成绩表,需要查询每个同学去除他整个学期所有测试中最高和最低分的结果,这种情况,关联的子查询适合了
SELECT a.* FROM Exam AS a LEFT JOIN (SELECT [name],MAX(score) AS MaxScore,MIN(score) AS MinScore FROM Exam GROUP BY [name] HAVING MAX(score)<>MIN(score) ) AS b ON a.name=b.name AND a.score<>b.MaxScore AND a.score<>b.MinScore WHERE b.name IS NOT NULL
从下面开始则是个人积累阶段了
去除重复会涉及到子查询,但子查询会分在FROM子句关联的子查询和直接在WHERE子句里面。共同点在于把视为重复的若干列先分组把他们的键查出来,然后在另一个查询中把最大或最小的保留,其余的DELETE,又拿Exam(id,name,score,subject)表为例,单科只需要一个成绩,其余的去掉。
DELETE FROM Exam WHERE id NOT IN ( SELECT MIN(id) FROM Exam GROUP BY name,subject )
另外一种在FROM子句的关联删除会在联表删除中列出来,假如没有主键,或组合主键不便于值用一个值去唯一标识这一行的,我想到的另一个办法是:建临时表#temptable,然后INSERT #temptable SELECT DESTINCT ,接着把原表删除,最后把临时表的数据INSERT去原表并把临时表删掉就得了,这个用在大数据量不知是否会合适。
联表更新只是很基本的SQL语法而已,只是鄙人基本功不够扎实,就记录一下
UPDATE a SET a.value=b.monvalue WHERE table1 AS a INNER JOIN table2 AS B ON a.id=b.id WHERE …….
在这里顺便几下SQLite的
UPDATE table1 SET value=(SELECT monvalue FROM table2 where id=table1.id )
还有MySQL的
UPDATE table1 AS a,table2 AS b SET a.value=b.monvalue WHERE a.id=b.id
与上面说的删除重复数据相照应,直接上SQL
DELETE a FROM Exam AS a LEFT JOIN ( SELECT MIN(id) FROM Exam GROUP BY name,subject ) AS b ON a.id=b.id WHERE b.id IS NULL
Case when 实际上有两种格式,简单一点的是case函数形式,如下面情况
Case sex When ‘1‘ THEN ‘男‘ WHEN ‘2‘ THEN ‘女‘ ELSE ‘其他‘ END
另外一种形式叫case搜索函数,就像下面这样子
Case when sex=‘1‘ THEN ‘‘ When sex=‘2‘ THEN ‘女‘ ELSE ‘其他‘ END
个人认为case when 在查询中实现了分支判断的效果,单纯从外观语法上case函数形式会简介,但从效果来说case函数适合于分支判定是离散的值时适合;case搜索函数是适合于一定的范围,或者说自由度更广的一些判定条件,当然这个也包含了离散的值这个状况。但是case 搜索函数在判定好一个条件符合之后则会屏蔽后面合适的条件。像下面这条语句是能分清各个成绩的等级的
SELECT *,CASE WHEN score >90 THEN ‘优秀‘ WHEN score>80 THEN ‘良好‘ WHEN score>60 THEN ‘合格‘ ELSE ‘不合格‘ END FROM Exam
但是下面就只有合格与不合格两种等级了
SELECT *,CASE WHEN score>60 THEN ‘合格‘ WHEN score>80 THEN ‘良好‘ WHEN score >90 THEN ‘优秀‘ ELSE ‘不合格‘ END FROM Exam
之前鄙人一直在写case when … is null 这样的语句,老是不断尝试看语法又没出错,区分好case函数和case 搜索函数之后就明白,该用case when … is null 而不是case … when is null这样了。
现在数据库里面的表老是说横向表,纵向表,横向表就例如下面的表结构SubjectTest(id,name,subject,score)。假如要展示的结果是(学生,语文,数学,英语)这样的结果时则需要用到行转列
行转列有用到上面case when语句,大概是先把记录按姓名去分组,然后从分组中把各个分数用case分离出来,再用聚集函数求最值或者是求和,语句就这样子
select name, MAX( CASE [subject] WHEN ‘语文‘ THEN [score] ELSE 0 END ) AS ‘语文‘, MAX( CASE [subject] WHEN ‘数学‘ THEN [score] ELSE 0 END ) AS ‘数学‘, MAX( CASE [subject] WHEN ‘英语‘ THEN [score] ELSE 0 END ) AS ‘英语‘, SUM([score]) AS ‘总分‘, AVG([score]) AS ‘平均分‘ FROM SubjectTest GROUP BY [name]
原来也就这么一回事,当科目多了,MAX除了要多写几次外,还可以用用DBA妹子教的SQL拼凑生成把语句生成出来在执行,可惜视图View不支持这样子,唉!
在SQL Server 2005以上有另外一种方式pivot,直接上语句
SELECT * FROM subjecttest PIVOT( SUM(score) FOR [subject] IN( 语文,数学,英语 ) ) a
我很奇怪网上说的结果都是合并好的,而我的结果却是这个样子
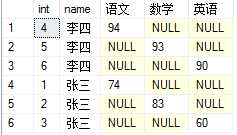
有行转列,也会有列转行,不过这个更没意思,但顺带也说说UNPIOVT
select name,‘语文‘,语文 as score FROM SubjectTest UNION ALL select name,‘数学‘,数学 as score FROM SubjectTest UNION ALL select name,‘英语‘,英语 as score FROM SubjectTest
SELECT * FROM subjecttest UNPIVOT ( score for [subject] IN (语文,数学,英语) ) a
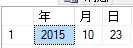
这几个函数用于求日期的相应部分,顾名思义是月份,年份,天数
DECLARE @testTimePoint DateTime SET @testTimePoint=‘2015-10-23‘ SELECT YEAR(@testTimePoint) AS 年,MONTH(@testTimePoint) AS 月,DAY(@testTimePoint) AS 日
Cast函数用于作为数据类型转换,使用它有三点要注意
(1)两个表达式的数据类型完全相同。;
(2)两个表达式可隐性转换。
(3)必须显式转换数据类型。
像下面这样子是会报错的
SELECT CAST(‘12.3‘ AS int)
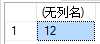
因为‘12.3‘只能转到浮点数,不能转成整形,但是浮点数能转成整形,要让它能成功转,就得这样子
SELECT CAST( CAST(‘12.3‘ AS Float) AS Int)
写完这篇博文后,我发现比之前DBA走的时候,长进了一点点了。我只是想当一名合格的程序员。
标签:
原文地址:http://www.cnblogs.com/HopeGi/p/4973468.html