标签:
在讨论数据库之前我们先要明白一个问题:什么是数据库?
数据库是若干对象的集合,这些对象用来控制和维护数据。一个经典的数据库实例仅仅包含少量的数据库,但用户一般也不会在一个实例上创建太多的数据库。一个数据库实例最多能创建32767个数据库,但是按照实际情况,一般设计是不会达到这个限制值。
为了更明显地说明数据库,数据库包含了以下属性和功能:
*. 它是很多对象的集合,比如表、视图、存储过程、约束。对象集合的最大值是2(31) - 1(超过2百亿)。一般对象的数量在几百至一万。
*. 它维持拥有的用户account、roles、schemas以及security;
*. 它拥有系统表去控制数据库目录;
*. 它拥有自己的事务日志并且管理自己的事务;
*. 它有自己的范围大小, 从2MB到524272T;
*. 它能自动或者手动的增长或者收缩;
*. 它能和其他同一数据库实例的其他数据库进行内联查询操作;
系统数据库
当安装一个数据库,Sql Server自动会创建4个数据库:master、model、tempdb、msdb。但很多人都不知道还有第五个隐藏的数据库,通过常规的sql指令是看不到这个数据库的。它更像一个资源数据库,真实名称叫做mssqlsystemresource。接下来分别介绍这几个数据库:
1)master。master由系统表组成,用来跟踪整个服务安装器和被用户创建的其他数据库。虽然每个数据库都包含有系统目录,用来维持数据库包含的对象信息,但是master包含的系统目录还维持了磁盘空间、文件分配、系统配置、登陆账号、当前实体包含的数据库等等。
你应该习惯经常备份master数据库。因为很多操作,例如创建数据库、改变配置、修改登录账号等都会写入到master中,所以当你执行这些操作后要经常备份。
2)model。model是一个简单的模板数据库。当用户创建一个数据库,sql server拷贝一份model到新数据库的基础表中。例如,你想新建一个数据库默认包含某些对象或者权限,你可以把这些对象或者权限放到model中,新建的表会继承model。
3)tempdb。tempdb被作为一个工作区。在sql server 数据库中它也是唯一的,如果重启了数据库它会重新创建。它被用户用来创建临时表,在执行查询和排序时作为工作表保存中间结果,维持行版本信息,实现静态游标和keyset游标的主键。因为tempdb数据库每次启动会重新创建,所以你在它里边创建的任何对象以及权限都会丢失。如果你像把某些对象保存在tempdb中,你可以编写存储过程创建对象,每次启动数据库时执行该存储过程。
4)mssqlsystemresource(资源数据库)。mssqlsystemresource是一个隐藏的数据库,存储可执行系统对象,像存储过程、函数。为什么该数据库是不可见的?微软创建它是用来快速并且安全的做数据库更新。因为没有人能获取它,没有人能改变它。通过任何预览数据库的方法去查看该数据都是无效的,例如从sys.databases 或者 executing
sp_helpdb。也不会显示在SQL Server M Studio的树结构上。但是,它始终还是需要存储在磁盘上。
你可以在目录C:\Program Files\Microsoft SQL Server\MSSQL10.MSSQLSERVER\
MSSQL\Binn上查看到该数据库文件,包含两个文件: mssqlsystemresource.mdf(60MB)、mssqlsystemresource.ldf(0.5MB)。你可以通过两种方式查看它的内容。最简单的是停止数据库,拷贝两个文件,重启数据库,通过附加文件的方式创建一个新的数据库。或者你可以用CREATE DATABASE FOR ATTACH语法创建一个拷贝数据库。
CREATE DATABASE resource_COPY
ON (NAME = data, FILENAME = ‘C:\Program Files\Microsoft SQL Server\MSSQL.1\MSSQL\binn
\mssqlsystemresource_COPY.mdf‘),
(NAME = log, FILENAME =
‘C:\Program Files\Microsoft SQL Server\MSSQL.1\MSSQL\binn\mssqlsystemresource_COPY.ldf‘)
FOR ATTACH;
5)msdb。msdb被用作sql server代理服务,形成计划活动(例如备份、复制任务)、服务中间者(为sql server
提供可靠的信息)。为了备份 ,msdb支持jobs、alerts、log shipping、poliecies、数据库邮件以及损坏页的恢复等。但我们一般是不会操作该数据库的。
数据库文件
一个数据库文件不外乎就是一个操作系统文件。针对于数据库文件,sql server有备份策略,逻辑策略是映射成操作系统文件、物理策略例如磁盘驱动器。一个数据库至少分割成两个文件也可以多个。一个是数据文件(例如索引和分配的页),一个是事务日志文件。
数据库文件包含三种类型:
1)关键数据文件。必须有有一个关键数据文件用来存储数据,扩展名为.mdf。
2)第二数据文件。可以有零个或者多个,扩展名为.ndf。
3)日志文件。至少一个日志文件,包含必要的信息用来恢复数据库中的所有事物。扩展名为.ldf。
每个数据库文件包含五个属性 :逻辑文件名、物理文件名、初始大小、最大尺寸、增长值。我们可以通过元数据视图sys.database_files查看这些熟悉,每个文件包含一行数据。例如我创建一个数据库Sample。然后执行在Sample数据库中执行以下sql语句:
select * from sys.database_files;
查看到的结果:
关键列说明:
|
type
|
File type:
0 = Rows (includes full-text catalogs upgraded to or created in
SQL Server 2008)
1 = Log
2 = FILESTREAM
3 = Reserved for future use
4 = Full-text (includes full-text catalogs from versions earlier than
SQL Server 2008)
|
|
name
|
The logical name of the fi le
|
|
physical_name
|
Operating-system fi le name
|
|
size
|
Current size of the fi le, in 8-KB pages.
0 = Not applicable
For a database snapshot, size refl ects the maximum space that the snapshot
can ever use for the fi le.
|
|
max_size
|
Maximum fi le size, in 8-KB pages:
0 = No growth is allowed.
–1 = File will grow until the disk is full.
268435456 = Log fi le will grow to a maximum size of 2 terabytes.
|
|
growth
|
0 = File is a fi xed size and will not grow.
>0 = File will grow automatically.
If is_percent_growth = 0, growth increment is in units of 8-KB pages,
rounded to the nearest 64 KB.
If is_percent_growth = 1, growth increment is expressed as a whole number
percentage.
|
创建数据库
创建数据库最简单的方法是使用Management Stdudio对象浏览器创建。它等同于CREATE DATABASE指令。并不是所有的用户都可以创建数据库,创建数据库必须要有相应的权限,具体哪些权限可以创建数据库?包括任何拥有sysadmin角色、任何有CONTROL or ALTER权限、任何有CREATE DATABASE权限的sysadmin或者
dbcreator角色。
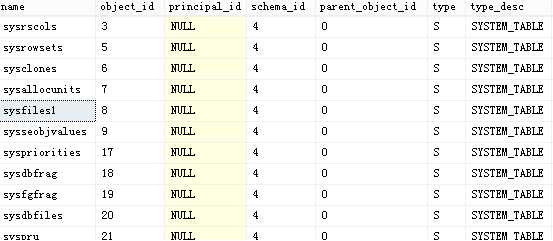
当创建了新数据库,SQL Server拷贝model数据库。如果你有一个定制的对象想包含在你创建的新数据库里,你应该首先创建该对象在model数据数据库中。你也可以在model总设置默认数据库参数,新建数据库都会继承这些参数。model数据库包含53个对象:45个系统表、6个对象(用户sql数据)、1张表(帮助管理change tracking)。你可以在 sys.objects查看这些对象,执行sql:
select * from sys.objects
可以查看到具体的数据:
一个新的用户数据库不能小于3MB(包括日志文件)。并且主数据文件的大小不能小于model数据库的主数据文件大小。创建数据库时,尽可能地使用默认值创建。因此创建一个数据库的简单sql语句如下:
CREATE DATABASE newdb;
执行该语句后,newdb数据库拥有默认的大小、newdb和newdb_log两个逻辑名称、物理文件newdb.mdf和newdb_log.ldf被创建在默认的文件夹。
接下来给出一个完成的创建数据库语句:
|
CREATE DATABASE Archive
ON
PRIMARY
( NAME = Arch1,
FILENAME =
‘c:\program files\microsoft sql server\mssql.1\mssql\data\archdat1.mdf‘,
SIZE = 100MB,
MAXSIZE = 200MB,
FILEGROWTH = 20MB),
( NAME = Arch2,
FILENAME =
‘c:\program files\microsoft sql server\mssql.1\mssql\data\archdat2.ndf‘,
SIZE = 10GB,
MAXSIZE = 50GB,
FILEGROWTH = 250MB)
LOG ON
( NAME = Archlog1,
FILENAME =
‘c:\program files\microsoft sql server\mssql.1\mssql\data\archlog1.ldf‘,
SIZE = 2GB,
MAXSIZE = 10GB,
FILEGROWTH = 100MB);
|
数据库文件的扩展可以使用FILEGROWTH 自动实现,FILEGROWTH 定义使用的单位包括TB、GB、MB、KB或者%,属性MAXSIZE限制问价你的最大值。
设置文件为自增长有优点也有缺点。例如,你设置文件按照10%自动增长,如果一个应用试图插入一行并且没有空余的空间,数据库开始自动按10%的比例扩大,但这个过程也需要花费大量时间,可能导致插入超时,写数据失败。
数据库文件也可以自动缩减。这个功能可以使用DBCC SHRINKDATABASE指令操作:
DBCC SHRINKDATABASE (database_name, 20%)
上面的语句表示如果数据库占用空间减小了20%以上,自动执行缩减20%。
DBCC SHRINKFILE指令允许你缩减当前数据库的文件。举个例子,一个数据文件的70%正在使用,使用 DBCC SHRINKFILE缩减5MB,但最终文件缩减成7MB而不是5MB。
这里我们在说说 DBCC SHRINKFILE,该指令缩减一个数据库里边的所有文件,但必须注意的是,缩减不允许任何文件小于数据它自身的最小值。这个最小值是数据库初始化时的大小。如果你需要缩减一个数据库小于它的最小值,可以使用DBCC SHRINKFILE 缩减数据库文件到指定大小。这个指定的大小变成最新的最小值。
数据库文件分组(filegroup)
你可以为一个数据库分组数据文件到一个“文件分组”里边,它有利于分配和管理。有些时候,你可以通过把数据索引指定到特别的分组从而提升性能。包含主数据文件的分组叫做主文件分组。一个数据库有且仅有一个主文件分组,但你可以通过freelancer关键字创建多个用户定义的分组。
这里必须要说明下主文件分组primary filegroup和主文件的区别:
(1)当我们创建一个数据库时,首先看到的就是主文件,一般扩展名为.mdf。主文件一个特殊的功能就是指向master数据库(可通过目录视图sys.database_files查看属于数据库的文件)。
(2)主文件分组包含主文件以及其他没有放置到其他分组的文件。
数据库文件分组有什么用呢?举个简单的例子,你的数据库由一个大小为120G的文件组成,如果你考虑恢复这个数据库,你不得不腾出120G的空间才能恢复整个数据库。但如果我们创建数据库在若干个小文件上,可以增加恢复时的灵活性。
创建FILEGROUP可通过以下指令:
|
CREATE DATABASE Sales
ON PRIMARY
( NAME = salesPrimary1,
FILENAME =
‘c:\program files\microsoft sql server\mssql.1\mssql\data\salesPrimary1.mdf‘,
SIZE = 100,
MAXSIZE = 500,
FILEGROWTH = 100 ),
( NAME = salesPrimary2,
FILENAME =
‘c:\program files\microsoft sql server\mssql.1\mssql\data\salesPrimary2.ndf‘,
SIZE = 100,
MAXSIZE = 500,
FILEGROWTH = 100 ),
FILEGROUP SalesGroup1
( NAME = salesGrp1Fi1e1,
FILENAME =
‘c:\program files\microsoft sql server\mssql.1\mssql\data\salesGrp1Fi1e1.ndf‘,
SIZE = 500,
MAXSIZE = 3000,
FILEGROWTH = 500 ),
( NAME = salesGrp1Fi1e2,
FILENAME =
‘c:\program files\microsoft sql server\mssql.1\mssql\data\salesGrp1Fi1e2.ndf‘,
SIZE = 500,
MAXSIZE = 3000,
FILEGROWTH = 500 ),
FILEGROUP SalesGroup2
( NAME = salesGrp2Fi1e1,
FILENAME =
‘c:\program files\microsoft sql server\mssql.1\mssql\data\salesGrp2Fi1e1.ndf‘,
SIZE = 100,
MAXSIZE = 5000,
FILEGROWTH = 500 ),
( NAME = salesGrp2Fi1e2,
FILENAME =
‘c:\program files\microsoft sql server\mssql.1\mssql\data\salesGrp2Fi1e2.ndf‘,
SIZE = 100,
MAXSIZE = 5000,
FILEGROWTH = 500 )
LOG ON
( NAME = ‘Sales_log‘,
FILENAME =
‘c:\program files\microsoft sql server\mssql.1\mssql\data\saleslog.ldf‘,
SIZE = 5MB,
MAXSIZE = 25MB,
FILEGROWTH = 5MB );
|
修改数据库
当我们想修改文件大小时,可执行:
USE master
GO
ALTER DATABASE Test1
MODIFY FILE
( NAME = ‘test1dat3‘,
SIZE = 2000MB);
当我们想添加文件分组并设置为默认时,可参考以下语句:
|
ALTER DATABASE Test1
ADD FILEGROUP Test1FG1;
GO
ALTER DATABASE Test1
ADD FILE
( NAME = ‘test1dat4‘,
FILENAME =
‘c:\program files\microsoft sql server\mssql.1\mssql\data\t1dat4.ndf‘,
SIZE = 500MB,
MAXSIZE = 1000MB,
FILEGROWTH = 50MB),
( NAME = ‘test1dat5‘,
FILENAME =
‘c:\program files\microsoft sql server\mssql.1\mssql\data\t1dat5.ndf‘,
SIZE = 500MB,
MAXSIZE = 1000MB,
FILEGROWTH = 50MB)
TO FILEGROUP Test1FG1;
GO
ALTER DATABASE Test1
MODIFY FILEGROUP Test1FG1 DEFAULT;
GO
|
数据库下的引擎
一个数据库由用户创建分配若干空间,用户对象例如表和索引都存储在这些空间里。并且这些空间分配在若干个分割系统文件中。
数据库被分割成许多逻辑页(每个页大小为8KB),每个文件的分页编号也是连续的从0到n,n的大小也是根据文件的大小来定。你可以使用database ID、file ID以及page number区别任何页。当你使用ALTER DATABASE扩展文件时,增加的空间附加在文件的末尾。新分配空间的第一个页便成为n + 1。但你使用 DBCC SHRINKDATABASE或者 DBCC SHRINKFILE缩减数据库时,页编号也是从n到小移除。这样确保了一个文件的页编号总是连续的。
使用CREATE DATABASE创建数据库时,我们可得到一个唯一的database ID,我们可以通过执行以下语句:
select * from sys.databases;
查看新增的数据库信息。信息包含name、database_id、create date等等。
设置数据引擎
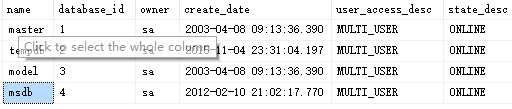
我们可以在sys.databases目录视图中查看数据库信息:
SELECT name, database_id, suser_sname(owner_sid) as owner,
create_date, user_access_desc, state_desc
FROM sys.databases
WHERE database_id <= 4
查询结果如下:
接下来我们讨论一些比较重要的数据库属性
(1)状态属性
| a. SINGLE_USER | RESTRICTED_USER | MULTI_USER |
用来描述用户访问数据库的属性。
例如:
ALTER DATABASE Sample SET SINGLE_USER; SINGLE_USER表示某一时刻之允许有一个链接;
RESTRICTED_USER表示用户仅仅拥有dbcreator、sysadmin server角色或者是数据库db_owner,才可以访问数据库;
MULTI_USER表示任意用户连接。你可以通过SELECT USER_ACCESS_DESC FROM sys.databases WHERE name = ‘<name of database>‘查看数据库用户访问属性。
|
| b. OFFLINE | ONLINE | EMERGENCY |
数据库设置成OFFLINE后该数据库就不能被修改;如果当前有任何用户链接,数据库也不能设置成OFFLINE。
修改语句如下:
ALTER DATABASE Sample SET OFFLINE;
SELECT state_desc from sys.databases WHERE name = ‘Sample‘;
|
| c. READ_ONLY | READ_WRITE |
该组属性设置数据库读写模式,默认是READ_WRITE可读可写,READ_ONLY表示只读,没有INSERT, UPDATE, or DELETE操作。
例如:
ALTER DATABASE Sample SET READ_ONLY;
SELECT name, is_read_only FROM sys.databases WHERE name = ‘Sample ‘;
|
接下来我们添加一张表,sql语句如下:
create table Tab1
(
id int identity(1, 1) primary key,
Name nvarchar(100) not null
)
执行后,数据库报错:Failed to update database "Sample" because the database is read-only。提示用户数据库只读。
(2)SQL选项
| a. ANSI_NULLS |
如果设置为ON,任何和NULL比较返回UNKNOW;如果设置为OFF,如果两个都是NULL比较结果为TRUE |
数据库快照
首先说说数据库快照的功能:数据库快照可以把数据库镜像到reporting server,你不能读取数据从数据库mirror中。但是你可以创一个mirror的快照然后读取它;形成reports而不需要blocking;协调管理和保护用户错误。
创建快照的语法如下:
CREATE DATABASE Sample_snapshot ON
(NAME = N‘Sample‘, FILENAME = N‘D:\Program Files\Microsoft SQL Server\MSSQL11.MSSQLSERVER\MSSQL\DATA\Sample_snapshot.mdf‘)
AS SNAPSHOT OF Sample;
说明:Sample是我们之前创建的Sample数据库逻辑名称,Sample_snapshot.mdf是快照文件。
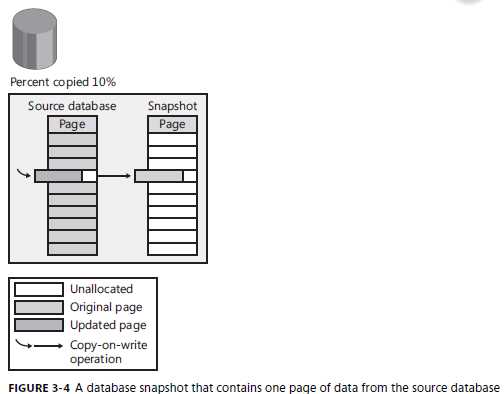
快照文件仅仅包含数据源中变化的数据,每个快照文件Sql Server会在内存中保持一份位图,标识文件中页的位置,指明是否数据页是否拷贝到快照。只要数据页一旦更新,Sql Server检查文件的位图并确定是否需要拷贝页到快照中。这样的操作叫做copy-on-write。下图展示了一个数据库的快照包含了10%的数据:
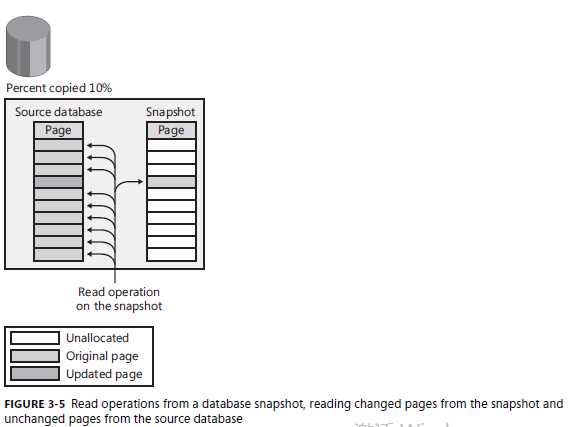
当一个进程从快照中读取数据,它首先访问位图确认快照是否包含需要访问页数据。请看下图,我们访问快照,9页数据来源于数据源,一页数据来源于快照。但是通过这种访问形式,不论当前是什么隔离级别,我们访问的数据不会有任何的锁行为。这也是使用快照的一大优势。
必须注意的是,这些位图是存储在缓存中,而不是它自身的文件里边,因此我们需要的时候都能读到它。当数据库重启后,这些位图丢失,需要重新启动构建。
tempdb数据库
tempdb和其他数据库最大的一个区别就是当数据库重启后tempdb数据库会被重新创建,它也像其他数据库一样,继承了model数据库的特性。某些数据库选项在tempdb上是无效的,例如OFFLINE以及READONLY。你也不能删除tempdb。
像之前内容,恢复是运行在一个创建了快照的数据库上。我们不能恢复tempdb,因此,我们也不能在tempdb上创建快照。这也意味着,我们不能使用DBCC CHECKDB。
tempdb里边包含三种对象:user objects、internal objects、the version store。下面分别介绍这三种对象:
1)user objects:所有的用户都有权限创建和使用包括在tempdb里边的本地以及全局的临时表。本地和全局临时名是以#或者##号开头。默认情况下,用户是没有权限使用tempdb创建表的,除非这个表以#或者##作为前缀。
2)internal Objects:对于一般的工具,内部对象在tempdb中是不可见的,但是它确实存在于数据库中。它们也没有罗列在catalog view中,因为它们的元数据仅仅存储在内存中。internal objects的三个基础类型分别是:work tables、work files、sort units。当执行一个大的查询、使用XML或者varchar(MAX)、使用statis或者keyset cursors时都会使用work tables;当在查询中使用hash operator、joining、aggregating时会使用work files;当在查询中包含Order by排序时会使用Sort units。Sql Server使用排序构建一个索引,也可能使用排序处理grouping查询。某些joins类型需要Sql Serve线排序数据再执行join。Sort units被创建在tempdb中去处理这些排序的数据。
3)Version Store:The verson store用于支持行级别数据版本技术。
tempdb优化
由于tempdb被使用在许多Sql Server内部操作,所以你不得不去监视和管理它。接下来的部分将讨论它的最佳实践和监视建议。并且将告诉你一些优化让tempdb管理对象更高效。
1)日志优化:像你知道的,影响你数据库的每一个操作都是有日志记录。在tempdb中,却不是这样的。例如,记录更新操作,仅仅原始数据被记录,没有记录新数据。另外,提交操作和提交的日志记录是没有同步到tempdb中,而是同步到其他数据库。
2)分配和缓存优化:许多分配优化被使用到所有数据库,不仅仅tempdb。但是,在操作过程中tempdb中经常有大量的新对象被创建和删除。因此,tempdb的性能冲击比其他的用户数据库都大。在Sql Server 2008中,分配页的访问的高效性决定了有效的自由度;你也看到很少的争夺在分配页方面,相对于之前的版本;Sql Server 2008也提供了一个非常高效的查询算法快速从混合区定位到单个页面。
tempdb的空间监视
Sql Server提供了一些系统视图提供tempdb的报表信息。最简单的是sys.dm_db_file_space_usage,它为每个数据文件返回一行数据。该视图包含的列如下:
|
■ database_id (even though the DBID 2 is the only one used)
■ file_id
■ unallocated_extent_page_count
■ version_store_reserved_page_count
■ user_object_reserved_page_count
■ internal_object_reserved_page_count
■ mixed_extent_page_count
|
这些列展示了tempdb中的user objects、internals objects、version store使用空间的情况。执行以下语句:
select * from sys.dm_db_file_space_usage;
结果如下图所示:
这些列展示了user objects、internals objects以及version store是怎样使用空间的。
数据库安全
安全对于数据库用户的每一个活动都是一个大的考虑点,包括管理员、开发者。数据库安全架构设计也是理解数据库或者数据库对象如何工作的关键点。对于安全,Sql Serve 2008有两个方面的基础。一个是Securable:一个Securable是一个能授予权限的实体,包括databases、schemas、objects;另外一个是Principal:一个Pirncipal是一个能访问Securables的实体。对于Pricipal,第一个关键是它代表了独立用户(像sql server login或者Windows login);第二个关键是它代表多用户(像一个角色或者一个WIndows分组)。
认证表现了两个不同的级别。首先,任何用户想访问数据库资源都必须在服务级别授权。为了认证登录,Sql Server 2008安全提供两个基础方法。它们是Windows认证和Sql Server认证。如果是Windows认证,Sql Server登录策略直接使用Windows策略,允许操作系统验证Sql Server用户;如果是Sql Server认证,任何用户链接Sql Server必须提供有效的账号和密码。在混合模式下,基于Windows的客户端可使用WIndows认证。非Windows客户端或者远程网络的连接使用Sql Server认证。另外,当一个用户配置在数据库实体(混合模式)安装时,数据库连接可一直显示这个登录名,例如像sa。这个连接用户允许使用Window用户名。
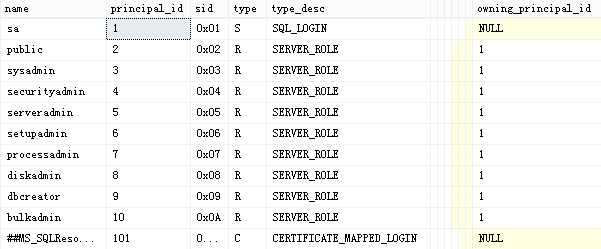
所有的Pricipal登录名,不管是windows还是Sql Server认证方式的,都能在目录视图ys.server_principals里边查看到。执行以下语句:
select * from sys.server_principals;
查看结果:
管理数据库安全
登录名是数据库的拥有者,我们可以在sys.databases视图中查看到SID列,这一列表示登录的SID,并且这个SID拥有这个数据库。数据库的资源被登陆用户所拥有。像你说看到的,数据库的所有对象被数据库Principals拥有。 执行以下语句:
select d.name, d.database_id, p.name
from sys.databases d
inner join sys.server_principals p
on d.owner_sid = p.sid
查看结果:
我们可以查到,master数据库的拥有者为sa登陆名。同时也可以看出数据库中也有一个叫做sa的Principal。
每个数据库都有一个sys.database_principals目录视图,通过这个视图,你可以了解登陆名和数据库中的用户对应关系。下面的查询语句展示了示例数据库中的用户和登陆名的映射关系,也展示了每个数据库用户的默认对象集合schema。
sql语句如下:
select d.name, d.database_id, p.name
from sys.databases d
inner join sys.server_principals p
on d.owner_sid = p.sid
执行结果如下:
分析:登录名sa有用户名称dbo。dbo是一个特殊的登录,dbo被sa登录使用(也被所有的sysadmin角色登录使用,包括在sys.databases罗列的数据库的所有登录)。
数据库和Schemas有什么关系?在ANSI SQL-92标准里,一个schema被定义作为数据库对象的集合,这个集合被单个用户拥有并且在同一个命名空间下。一个命名空间是一些列对象的集合,这个集合中的对象名称是不能重复的。
登录用户(Principals)和Schemas有什么关系?在Sql Server2008,用户和schemas是两个独立的东西。为了理解它们的不同,我们可以认为权限被授予用户(Principals),但对象存放在schemas里边。创建一个新用户一般默认schema都是dbo。
默认的Schemas是怎样的?当你创建一个数据库时,若干schemas包含在数据库中。它们包括dbo、INFORMATION_SCHEMA、guest。另外,每个数据库都有一个叫做sys的schemas,sys提供访问所有的系统表和视图。
移动、拷贝数据库
你可以通过简单的存储过程分离一个数据库,分离时需要保证该数据库没有任何连接。如果存在连接,你可以使用ALTER DATABASE 设置数据库为SINGLE_USER模式中断已存在的连接。一旦分离了数据库,该数据库在sys.databas、system tables中的记录被移除。
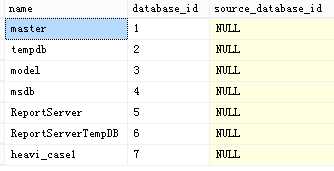
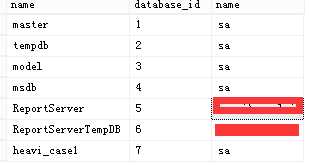
分离数据库的指令为:EXEC sp_detach_db <name of database>。例如我们有一个叫做heavi_case2的数据库,我们先执行sql:
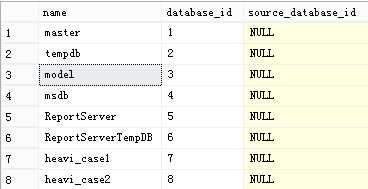
select * from sys.databases。结果如下:
现在我们执行分离数据库指令分离heavi_case2数据库。sql如下:
EXEC sp_detach_db heavi_case2;
然后再查看sys.databases表中的数据。通过结果可以看出heavi_case2已从表中移除。
分离数据库后,我们考虑怎样附件数据库。附件数据库可以使用CREATE DATABASE和FOR
ATTACH选项。语法如下:
CREATE DATABASE database_name
ON <filespec> [ ,...n ]
FOR { ATTACH
| ATTACH_REBUILD_LOG }
需要说明的是,以上语句只需要一个关键文件即可,因为关键文件已经包含了其他文件的位置。但是如果其他文件在不同的路径下就需要附加说明。现在我们根据以上语法把数据库heavi_case2附件到数据库上,在附加之前我们故意把heavi_case2.ldf文件移至其他目录下,然后执行以下语句:
CREATE DATABASE heavi_case2
ON
(NAME = heavi_case2,
FILENAME =
‘C:\Program Files\Microsoft SQL Server\MSSQL11.MSSQLSERVER\MSSQL\DATA\heavi_case2.mdf‘
)
FOR ATTACH
查看执行结果:New log file ‘C:\Program Files\Microsoft SQL Server\MSSQL11.MSSQLSERVER\MSSQL\DATA\heavi_case2_log.ldf‘ was created.。数据库直接创建了新的日志文件。考虑一种情况:如果我们想拷贝数据库并且日志文件很大时,我们可以不要日志文件,附件数据库时新建日志文件。
Sql Server来龙去脉系列之四 数据库和文件
标签:
原文地址:http://www.cnblogs.com/w-wanglei/p/ssql-series4.html









)_%60%25g0~%248.png)

jvcd2x.png)