标签:
文章提出一个从数据中训练得到相似性度量的方法。针对类别较多但每个类别的样本较少的情况,这个方法有用。这个方法的思想是:学习一个能够将输入特征映射到一个目标空间的函数,在这个目标空间中用一个L1范数来度量输入空间的“距离”,通过最小化loss函数以实现最小化同一类和最大化不同类的“距离”。映射的函数不固定,可以根据具体问题来假设映射的函数,本文中使用卷积神经网络来作为映射函数。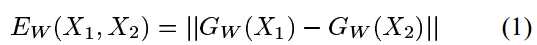
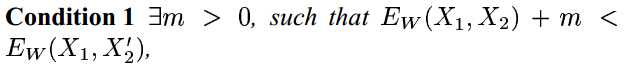
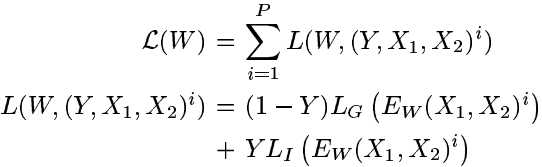
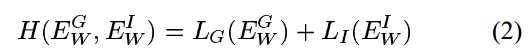
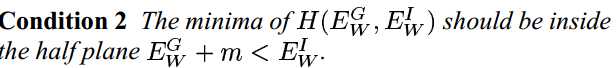
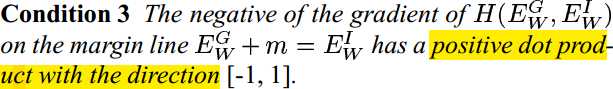
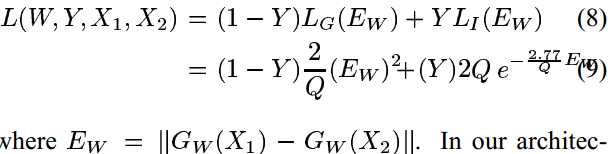
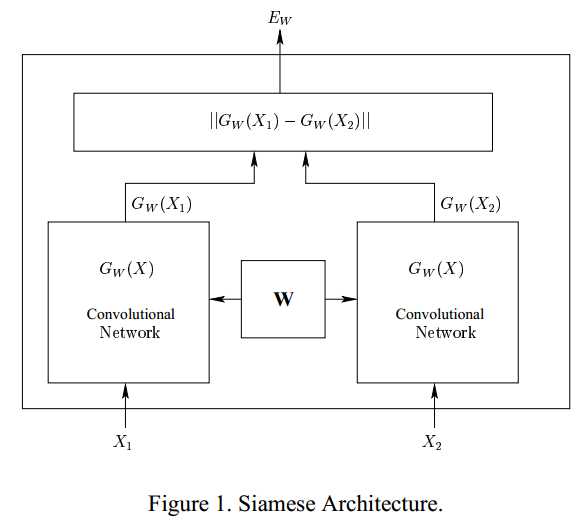


Notes:Learning a Similarity Metric Discriminatively, with Application to Face
标签:
原文地址:http://www.cnblogs.com/lijingcong/p/4978354.html