标签:
先创建一个示例表temp
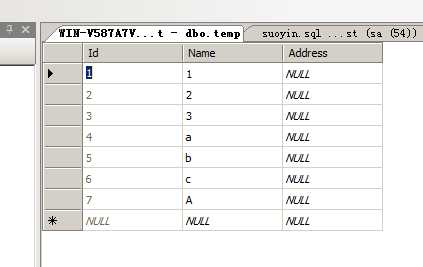
对表中Name字段创建一个索引
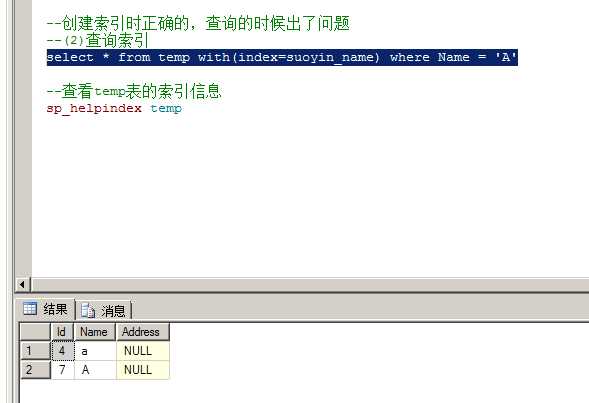
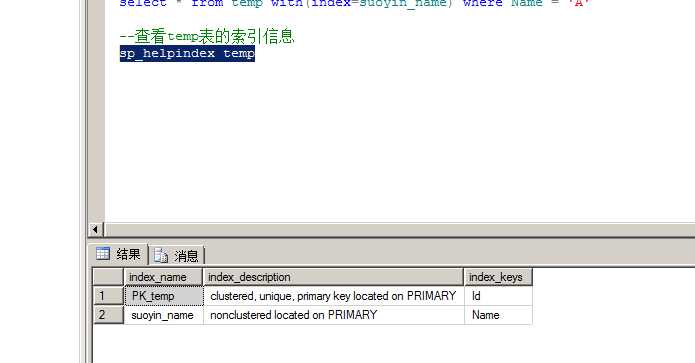
if exists(select name from sysindexes where name = ‘suoyin‘) drop index temp.suoyin ---如果存在这个名字的索引,则删除这个索引 create nonclustered index suoyin_name on temp(Name) --创建索引时正确的,查询的时候出了问题 --(2)查询索引 select * from temp with(index=suoyin_name) where Name = ‘A‘ --查看temp表的索引信息 sp_helpindex temp
语法
CREATE [UNIQUE] [CLUSTERED| NONCLUSTERED ]
INDEX index_name ON { table | view } ( column [ ASC | DESC ] [ ,...n ] )
[with[PAD_INDEX][[,]FILLFACTOR=fillfactor]
[[,]IGNORE_DUP_KEY]
[[,]DROP_EXISTING]
[[,]STATISTICS_NORECOMPUTE]
[[,]SORT_IN_TEMPDB]
]
[ ON filegroup ]
CREATE INDEX命令创建索引各参数说明如下: UNIQUE:用于指定为表或视图创建唯一索引,即不允许存在索引值相同的两行。 CLUSTERED:用于指定创建的索引为聚集索引。 NONCLUSTERED:用于指定创建的索引为非聚集索引。 index_name:用于指定所创建的索引的名称。 table:用于指定创建索引的表的名称。 view:用于指定创建索引的视图的名称。 ASC|DESC:用于指定具体某个索引列的升序或降序排序方向。 Column:用于指定被索引的列。 PAD_INDEX:用于指定索引中间级中每个页(节点)上保持开放的空间。 FILLFACTOR = fillfactor:用于指定在创建索引时,每个索引页的数据占索引页大小的百分比,fillfactor的值为1到100。 IGNORE_DUP_KEY:用于控制当往包含于一个唯一聚集索引中的列中插入重复数据时SQL Server所作的反应。 DROP_EXISTING:用于指定应删除并重新创建已命名的先前存在的聚集索引或者非聚集索引。 STATISTICS_NORECOMPUTE:用于指定过期的索引统计不会自动重新计算。 SORT_IN_TEMPDB:用于指定创建索引时的中间排序结果将存储在 tempdb 数据库中。 ON filegroup:用于指定存放索引的文件组。
标签:
原文地址:http://www.cnblogs.com/shy1766IT/p/4992955.html