模块是一种组织形式,他是 实现了某个功能的代码的集合,它将彼此有关系的代码组织到一个文件或一个目录中(目录中包含多个文件,这里改称为 “包”)。
模块分三类
内置模块
第三方模块
自定义模块
模块的定义:
package/
└── mod01.py
package/
├── mod01.py
├── mod02.py
└── mod03.py
package/
├── __init__.py
├── mod01.py
├── mod02.py
└── mod03.py
package/
├── __init__.py
├── mod01.py
├── mod02.py
├── mod03.py
└── subpackage
├── __init__.py
├── mod01.py
├── mod02.py
└── mod03.py
需要注意的是__init__.py 文件,__init__.py是一个特殊文件,它在python模块的每一个包中都存在,保重包含一些文件和子目录,如果子目录中也有__init__.py文件,那么这个子目录就是一个子包。在将一个模块导入的时候,实际上是导入了__init__.py文件。
__init__.py文件定义了包的属性和方法,他也可以为空文件,但必须存在。如果他不存在,那就不能被其他的包导入,或者 嵌套包和包含其他的模块
当一个模块被创建以后,模块的名字即使不带.py后缀名的文件名,你可以在一个模块中使用import语句来导入这个模块。导入模块的方式有以下几种,可根据实际情况来使用
import modulefrom module.xx.xx import xx
from module.xx.xx import xx,xx,xxfrom module.xx.xx import xx as rename #用于要导入的模块或者模块属性名称被占用,
# 或者不想使用导入的名字
from module.xx.xx import * #不在推荐使用
推荐所有的模块在python模块的开头部分导入,推荐的导入顺序是:
1. 内置模块(标准库模块)
2. 第三方模块
3. 自定义模块
然后使用一个空行来分隔这三类模块的导入语句
导入模块时的搜索路径
在导入模块的时候,解释器会去某些目录下进行查找,如果找不到模块,就会报错。就像下面这样:
>>> import ttt Traceback (most recent call last): File "<stdin>", line 1, in <module> ImportError: No module named ttt
解释器的默认搜索路径是在编译或者安装的时候指定的,
一是 : 在启动python的shell或者命令行的PATHONPATH环境变量 中设置
二是 : 解释器启动后,在sys模块的sys.path变量里进行设置
####################################
关于一些模块的介绍
paramiko 模块
paramiko模块,遵循SSH2协议,支持以加密和认证的方式,进行远程服务器的连接,fabric和ansible内部的远程管理就是使用的paramiko来现实的。
安装
# pycrypto,由于 paramiko 模块内部依赖pycrypto,所以先下载安装pycrypto # 下载安装 pycrypto wget http://files.cnblogs.com/files/wupeiqi/pycrypto-2.6.1.tar.gz tar -xvf pycrypto-2.6.1.tar.gz cd pycrypto-2.6.1 python setup.py build python setup.py install # 进入python环境,导入Crypto检查是否安装成功 # 下载安装 paramiko wget http://files.cnblogs.com/files/wupeiqi/paramiko-1.10.1.tar.gz tar -xvf paramiko-1.10.1.tar.gz cd paramiko-1.10.1 python setup.py build python setup.py install # 进入python环境,导入paramiko检查是否安装成功
通过用户名和密码连接服务器 import paramiko private_key_path = ‘/home/auto/.ssh/id_rsa‘ key = paramiko.RSAKey.from_private_key_file(private_key_path) ssh = paramiko.SSHClient() ssh.set_missing_host_key_policy(paramiko.AutoAddPolicy()) ssh.connect(‘主机名 ‘, 端口, ‘用户名‘, key) stdin, stdout, stderr = ssh.exec_command(‘df‘) print stdout.read() ssh.close() 执行命令 - 过密钥链接服务器
通过密钥链接服务器 import os,sysimport paramiko t = paramiko.Transport((‘182.92.219.86‘,22)) t.connect(username=‘wupeiqi‘,password=‘123‘) sftp = paramiko.SFTPClient.from_transport(t) sftp.put(‘/tmp/test.py‘,‘/tmp/test.py‘) t.close()import os,sysimport paramiko t = paramiko.Transport((‘182.92.219.86‘,22)) t.connect(username=‘wupeiqi‘,password=‘123‘) sftp = paramiko.SFTPClient.from_transport(t) sftp.get(‘/tmp/test.py‘,‘/tmp/test2.py‘) t.close()
通过用户名和密码 上传或者下载文件 import os,sysimport paramiko t = paramiko.Transport((‘182.92.219.86‘,22)) t.connect(username=‘wupeiqi‘,password=‘123‘) sftp = paramiko.SFTPClient.from_transport(t) sftp.put(‘/tmp/test.py‘,‘/tmp/test.py‘) t.close()import os,sysimport paramiko t = paramiko.Transport((‘182.92.219.86‘,22)) t.connect(username=‘wupeiqi‘,password=‘123‘) sftp = paramiko.SFTPClient.from_transport(t) sftp.get(‘/tmp/test.py‘,‘/tmp/test2.py‘) t.close()
通过密钥 上传或下载文件 import paramiko pravie_key_path = ‘/home/auto/.ssh/id_rsa‘key = paramiko.RSAKey.from_private_key_file(pravie_key_path) t = paramiko.Transport((‘182.92.219.86‘,22)) t.connect(username=‘wupeiqi‘,pkey=key) sftp = paramiko.SFTPClient.from_transport(t) sftp.put(‘/tmp/test3.py‘,‘/tmp/test3.py‘) t.close()import paramiko pravie_key_path = ‘/home/auto/.ssh/id_rsa‘key = paramiko.RSAKey.from_private_key_file(pravie_key_path) t = paramiko.Transport((‘182.92.219.86‘,22)) t.connect(username=‘wupeiqi‘,pkey=key) sftp = paramiko.SFTPClient.from_transport(t) sftp.get(‘/tmp/test3.py‘,‘/tmp/test4.py‘) t.close()
os 模块 --- 提供操作系统级别的操作
os.getcwd() 获取当前工作目录,即当前python脚本工作的目录路径
os.chdir("dirname") 改变当前脚本工作目录;相当于shell下cd
os.curdir 返回当前目录: (‘.‘)
os.pardir 获取当前目录的父目录字符串名:(‘..‘)
os.makedirs(‘dirname1/dirname2‘) 可生成多层递归目录
os.removedirs(‘dirname1‘) 若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,依此类推
os.mkdir(‘dirname‘) 生成单级目录;相当于shell中mkdir dirname
os.rmdir(‘dirname‘) 删除单级空目录,若目录不为空则无法删除,报错;相当于shell中rmdir dirname
os.listdir(‘dirname‘) 列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印
os.remove() 删除一个文件
os.rename("oldname","newname") 重命名文件/目录
os.stat(‘path/filename‘) 获取文件/目录信息
os.sep 输出操作系统特定的路径分隔符,win下为"\\",Linux下为"/"os.linesep 输出当前平台使用的行终止符,win下为"\t\n",Linux下为"\n"os.pathsep 输出用于分割文件路径的字符串
os.name 输出字符串指示当前使用平台。win->‘nt‘; Linux->‘posix‘os.system("bash command") 运行shell命令,直接显示
os.environ 获取系统环境变量
os.path.abspath(path) 返回path规范化的绝对路径
os.path.split(path) 将path分割成目录和文件名二元组返回
os.path.dirname(path) 返回path的目录。其实就是os.path.split(path)的第一个元素
os.path.basename(path) 返回path最后的文件名。如何path以/或\结尾,那么就会返回空值。即os.path.split(path)的第二个元素
os.path.exists(path) 如果path存在,返回True;如果path不存在,返回False
os.path.isabs(path) 如果path是绝对路径,返回True
os.path.isfile(path) 如果path是一个存在的文件,返回True。否则返回False
os.path.isdir(path) 如果path是一个存在的目录,则返回True。否则返回False
os.path.join(path1[, path2[, ...]]) 将多个路径组合后返回,第一个绝对路径之前的参数将被忽略
os.path.getatime(path) 返回path所指向的文件或者目录的最后存取时间
os.path.getmtime(path) 返回path所指向的文件或者目录的最后修改时间sys模块 提供对解释器相关的操作
sys.argv 命令行参数List,第一个元素是程序本身路径 sys.exit(n) 退出程序,正常退出时exit(0) sys.version 获取Python解释程序的版本信息 sys.maxint 最大的Int值 sys.path 返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值 sys.platform 返回操作系统平台名称 sys.stdout.write(‘please:‘) val = sys.stdin.readline()[:-1]
hashlib模块
用于加密相关的操作,代替了md5模块和sha模块,主要提供 SHA1, SHA224, SHA256, SHA384, SHA512 ,MD5 算法
已经废弃的 md5 和 sha
import md5 hash = md5.new() hash.update(‘admin‘)print hash.hexdigest()
import sha hash = sha.new() hash.update(‘admin‘)print hash.hexdigest()
import hashlib # ######## md5 ######## hash = hashlib.md5() hash.update(‘admin‘) print hash.hexdigest() # ######## sha1 ######## hash = hashlib.sha1() hash.update(‘admin‘) print hash.hexdigest() # ######## sha256 ######## hash = hashlib.sha256() hash.update(‘admin‘) print hash.hexdigest() # ######## sha384 ######## hash = hashlib.sha384() hash.update(‘admin‘) print hash.hexdigest() # ######## sha512 ######## hash = hashlib.sha512() hash.update(‘admin‘) print hash.hexdigest()
以上加密算法虽然依然非常厉害,但时候存在缺陷,即:通过撞库可以反解。所以,有必要对加密算法中添加自定义key再来做加密。
import hashlib # ######## md5 ######## hash = hashlib.md5(‘898oaFs09f‘) hash.update(‘admin‘) print hash.hexdigest()
hmac 模块,它内部对我们创建 key 和 内容 再进行处理然后再加密
import hmac h = hmac.new(‘wueiqi‘) h.update(‘hellowo‘) print h.hexdigest()
json和pickle模块
用于序列化的两个模块
json,用于字符串 和 python数据类型间进行转换
pickle,用于python特有的类型 和 python的数据类型间进行转换
Json模块提供了四个功能:dumps、dump、loads、load
pickle模块提供了四个功能:dumps、dump、loads、load
import pickle
data = {"k1":123,"k2":"abc"}
#pickle.dumps 可以将数据通过特殊的形式转换为只有python认识的字符串
p_str = pickle.dumps(data)
print p_str
# pickle.dump 可以将数据通过特殊的形式转换为只有python认识的字符串,并写入文件
with open("result.pk","w") as fp:
pickle.dump(data,fp)
import json
# json.dumps 可以将数据通过特殊的形式转换为所有程序都认识的字符串
j_str = json.dumps()
print j_str
# json.dumps 可以将数据通过特殊的形式转换为所有程序都认识的字符串,并写入文件
with open("result.json","w") as fj:
json.dump(data,fj)
和执行操作系统命令相关的模块和函数
os.system
os.spawn*
os.popen* --废弃
popen2.* --废弃
commands.* --废弃,3.x中被移除
以上执行shell命令的相关的模块和函数的功能均在 subprocess 模块中实现,并提供了更丰富的功能。
call
执行命令,返回状态码
ret = subprocess.call(["ls", "-l"], shell=False)ret = subprocess.call("ls -l", shell=True)check_call
执行命令,如果执行状态码是 0 ,则返回0,否则抛异常
subprocess.check_call(["ls", "-l"])subprocess.check_call("exit 1", shell=True)check_output
执行命令,如果状态码是 0 ,则返回执行结果,否则抛异常
subprocess.check_output(["echo", "Hello World!"])subprocess.check_output("exit 1", shell=True)subprocess.Popen(...)
用于执行复杂的系统命令
参数:
args:shell命令,可以是字符串或者序列类型(如:list,元组)
bufsize:指定缓冲。0 无缓冲,1 行缓冲,其他 缓冲区大小,负值 系统缓冲
stdin, stdout, stderr:分别表示程序的标准输入、输出、错误句柄
preexec_fn:只在Unix平台下有效,用于指定一个可执行对象(callable object),它将在子进程运行之前被调用
close_sfs:在windows平台下,如果close_fds被设置为True,则新创建的子进程将不会继承父进程的输入、输出、错误管道。
所以不能将close_fds设置为True同时重定向子进程的标准输入、输出与错误(stdin, stdout, stderr)。
shell:同上
cwd:用于设置子进程的当前目录
env:用于指定子进程的环境变量。如果env = None,子进程的环境变量将从父进程中继承。
universal_newlines:不同系统的换行符不同,True -> 同意使用 \n
startupinfo与createionflags只在windows下有效
将被传递给底层的CreateProcess()函数,用于设置子进程的一些属性,如:主窗口的外观,进程的优先级等等
执行普通命令
import subprocess
ret1 = subprocess.Popen(["mkdir","t1"])
ret2 = subprocess.Popen("mkdir t2", shell=True)终端输入的命令分为两种:
输入即可得到输出,如:ifconfig
输入进行某环境,依赖再输入,如:python
import subprocess
obj = subprocess.Popen("mkdir t3", shell=True, cwd=‘/home/dev‘,)
###############################
import subprocess
obj = subprocess.Popen(["python"], stdin=subprocess.PIPE, stdout=subprocess.PIPE, stderr=subprocess.PIPE)
obj.stdin.write(‘print 1 \n ‘)
obj.stdin.write(‘print 2 \n ‘)
obj.stdin.write(‘print 3 \n ‘)
obj.stdin.write(‘print 4 \n ‘)
cmd_out = obj.stdout.read()
cmd_error = obj.stderr.read()print cmd_outprint cmd_error
###############################
import subprocess
obj = subprocess.Popen(["python"], stdin=subprocess.PIPE, stdout=subprocess.PIPE, stderr=subprocess.PIPE)
obj.stdin.write(‘print 1 \n ‘)
obj.stdin.write(‘print 2 \n ‘)
obj.stdin.write(‘print 3 \n ‘)
obj.stdin.write(‘print 4 \n ‘)
out_error_list = obj.communicate()print out_error_list
###############################
import subprocess
obj = subprocess.Popen(["python"], stdin=subprocess.PIPE, stdout=subprocess.PIPE, stderr=subprocess.PIPE)
out_error_list = obj.communicate(‘print "hello"‘)print out_error_listshutil模块 -- 高级的 文件、文件夹、压缩包 处理模块
高级的 文件、文件夹、压缩包 处理模块
shutil.copyfileobj(fsrc, fdst[, length])
将文件内容拷贝到另一个文件中,可以部分内容
def copyfileobj(fsrc, fdst, length=16*1024): """copy data from file-like object fsrc to file-like object fdst""" while 1: buf = fsrc.read(length) if not buf: break fdst.write(buf)
shutil.copyfile(src, dst)
拷贝文件
def copyfile(src, dst): """Copy data from src to dst"""
if _samefile(src, dst): raise Error("`%s` and `%s` are the same file" % (src, dst)) for fn in [src, dst]: try:
st = os.stat(fn) except OSError: # File most likely does not exist
pass
else: # XXX What about other special files? (sockets, devices...)
if stat.S_ISFIFO(st.st_mode): raise SpecialFileError("`%s` is a named pipe" % fn)
with open(src, ‘rb‘) as fsrc:
with open(dst, ‘wb‘) as fdst:
copyfileobj(fsrc, fdst)shutil.copymode(src, dst)
仅拷贝权限。内容、组、用户均不变
def copymode(src, dst): """Copy mode bits from src to dst""" if hasattr(os, ‘chmod‘): st = os.stat(src) mode = stat.S_IMODE(st.st_mode) os.chmod(dst, mode)
shutil.copystat(src, dst)
拷贝状态的信息,包括:mode bits, atime, mtime, flags
def copystat(src, dst): """Copy all stat info (mode bits, atime, mtime, flags) from src to dst""" st = os.stat(src) mode = stat.S_IMODE(st.st_mode) if hasattr(os, ‘utime‘): os.utime(dst, (st.st_atime, st.st_mtime)) if hasattr(os, ‘chmod‘): os.chmod(dst, mode) if hasattr(os, ‘chflags‘) and hasattr(st, ‘st_flags‘): try: os.chflags(dst, st.st_flags) except OSError, why: for err in ‘EOPNOTSUPP‘, ‘ENOTSUP‘: if hasattr(errno, err) and why.errno == getattr(errno, err): break else: raise
shutil.copy(src, dst)
拷贝文件和权限
def copy(src, dst): """Copy data and mode bits ("cp src dst").
The destination may be a directory. """
if os.path.isdir(dst):
dst = os.path.join(dst, os.path.basename(src))
copyfile(src, dst)
copymode(src, dst)shutil.copy2(src, dst)
拷贝文件和状态信息
def copy2(src, dst): """Copy data and all stat info ("cp -p src dst").
The destination may be a directory. """
if os.path.isdir(dst):
dst = os.path.join(dst, os.path.basename(src))
copyfile(src, dst)
copystat(src, dst)shutil.ignore_patterns(*patterns)
shutil.copytree(src, dst, symlinks=False, ignore=None)
递归的去拷贝文件
例如:copytree(source, destination, ignore=ignore_patterns(‘*.pyc‘, ‘tmp*‘))
def ignore_patterns(*patterns): """Function that can be used as copytree() ignore parameter. Patterns is a sequence of glob-style patterns that are used to exclude files""" def _ignore_patterns(path, names): ignored_names = [] for pattern in patterns: ignored_names.extend(fnmatch.filter(names, pattern)) return set(ignored_names) return _ignore_patternsdef copytree(src, dst, symlinks=False, ignore=None): """Recursively copy a directory tree using copy2(). The destination directory must not already exist. If exception(s) occur, an Error is raised with a list of reasons. If the optional symlinks flag is true, symbolic links in the source tree result in symbolic links in the destination tree; if it is false, the contents of the files pointed to by symbolic links are copied. The optional ignore argument is a callable. If given, it is called with the `src` parameter, which is the directory being visited by copytree(), and `names` which is the list of `src` contents, as returned by os.listdir(): callable(src, names) -> ignored_names Since copytree() is called recursively, the callable will be called once for each directory that is copied. It returns a list of names relative to the `src` directory that should not be copied. XXX Consider this example code rather than the ultimate tool. """ names = os.listdir(src) if ignore is not None: ignored_names = ignore(src, names) else: ignored_names = set() os.makedirs(dst) errors = [] for name in names: if name in ignored_names: continue srcname = os.path.join(src, name) dstname = os.path.join(dst, name) try: if symlinks and os.path.islink(srcname): linkto = os.readlink(srcname) os.symlink(linkto, dstname) elif os.path.isdir(srcname): copytree(srcname, dstname, symlinks, ignore) else: # Will raise a SpecialFileError for unsupported file types copy2(srcname, dstname) # catch the Error from the recursive copytree so that we can # continue with other files except Error, err: errors.extend(err.args[0]) except EnvironmentError, why: errors.append((srcname, dstname, str(why))) try: copystat(src, dst) except OSError, why: if WindowsError is not None and isinstance(why, WindowsError): # Copying file access times may fail on Windows pass else: errors.append((src, dst, str(why))) if errors: raise Error, errors
shutil.rmtree(path[, ignore_errors[, onerror]])
递归的去删除文件
def rmtree(path, ignore_errors=False, onerror=None): """Recursively delete a directory tree.
If ignore_errors is set, errors are ignored; otherwise, if onerror
is set, it is called to handle the error with arguments (func,
path, exc_info) where func is os.listdir, os.remove, or os.rmdir;
path is the argument to that function that caused it to fail; and
exc_info is a tuple returned by sys.exc_info(). If ignore_errors
is false and onerror is None, an exception is raised. """
if ignore_errors: def onerror(*args): pass
elif onerror is None: def onerror(*args): raise
try: if os.path.islink(path): # symlinks to directories are forbidden, see bug #1669
raise OSError("Cannot call rmtree on a symbolic link") except OSError:
onerror(os.path.islink, path, sys.exc_info()) # can‘t continue even if onerror hook returns
return
names = [] try:
names = os.listdir(path) except os.error, err:
onerror(os.listdir, path, sys.exc_info()) for name in names:
fullname = os.path.join(path, name) try:
mode = os.lstat(fullname).st_mode except os.error:
mode = 0 if stat.S_ISDIR(mode):
rmtree(fullname, ignore_errors, onerror) else: try:
os.remove(fullname) except os.error, err:
onerror(os.remove, fullname, sys.exc_info()) try:
os.rmdir(path) except os.error:
onerror(os.rmdir, path, sys.exc_info())shutil.move(src, dst)
递归的去移动文件
def move(src, dst): """Recursively move a file or directory to another location. This is similar to the Unix "mv" command. If the destination is a directory or a symlink to a directory, the source is moved inside the directory. The destination path must not already exist. If the destination already exists but is not a directory, it may be overwritten depending on os.rename() semantics. If the destination is on our current filesystem, then rename() is used. Otherwise, src is copied to the destination and then removed. A lot more could be done here... A look at a mv.c shows a lot of the issues this implementation glosses over. """ real_dst = dst if os.path.isdir(dst): if _samefile(src, dst): # We might be on a case insensitive filesystem, # perform the rename anyway. os.rename(src, dst) return real_dst = os.path.join(dst, _basename(src)) if os.path.exists(real_dst): raise Error, "Destination path ‘%s‘ already exists" % real_dst try: os.rename(src, real_dst) except OSError: if os.path.isdir(src): if _destinsrc(src, dst): raise Error, "Cannot move a directory ‘%s‘ into itself ‘%s‘." % (src, dst) copytree(src, real_dst, symlinks=True) rmtree(src) else: copy2(src, real_dst) os.unlink(src)
shutil.make_archive(base_name, format,...)
创建压缩包并返回文件路径,例如:zip、tar
base_name: 压缩包的文件名,也可以是压缩包的路径。只是文件名时,则保存至当前目录,否则保存至指定路径,
如:www =>保存至当前路径
如:/Users/wupeiqi/www =>保存至/Users/wupeiqi/
format: 压缩包种类,“zip”, “tar”, “bztar”,“gztar”
root_dir: 要压缩的文件夹路径(默认当前目录)
owner: 用户,默认当前用户
group: 组,默认当前组
logger: 用于记录日志,通常是logging.Logger对象
#将 /Users/wupeiqi/Downloads/test 下的文件打包放置当前程序目录
import shutil
ret = shutil.make_archive("wwwwwwwwww", ‘gztar‘, root_dir=‘/Users/wupeiqi/Downloads/test‘)
#将 /Users/wupeiqi/Downloads/test 下的文件打包放置 /Users/wupeiqi/目录
import shutil
ret = shutil.make_archive("/Users/wupeiqi/wwwwwwwwww", ‘gztar‘, root_dir=‘/Users/wupeiqi/Downloads/test‘)def make_archive(base_name, format, root_dir=None, base_dir=None, verbose=0,
dry_run=0, owner=None, group=None, logger=None): """Create an archive file (eg. zip or tar).
‘base_name‘ is the name of the file to create, minus any format-specific
extension; ‘format‘ is the archive format: one of "zip", "tar", "bztar"
or "gztar".
‘root_dir‘ is a directory that will be the root directory of the
archive; ie. we typically chdir into ‘root_dir‘ before creating the
archive. ‘base_dir‘ is the directory where we start archiving from;
ie. ‘base_dir‘ will be the common prefix of all files and
directories in the archive. ‘root_dir‘ and ‘base_dir‘ both default
to the current directory. Returns the name of the archive file.
‘owner‘ and ‘group‘ are used when creating a tar archive. By default,
uses the current owner and group. """
save_cwd = os.getcwd() if root_dir is not None: if logger is not None:
logger.debug("changing into ‘%s‘", root_dir)
base_name = os.path.abspath(base_name) if not dry_run:
os.chdir(root_dir) if base_dir is None:
base_dir = os.curdir
kwargs = {‘dry_run‘: dry_run, ‘logger‘: logger} try:
format_info = _ARCHIVE_FORMATS[format] except KeyError: raise ValueError, "unknown archive format ‘%s‘" % format
func = format_info[0] for arg, val in format_info[1]:
kwargs[arg] = val if format != ‘zip‘:
kwargs[‘owner‘] = owner
kwargs[‘group‘] = group try:
filename = func(base_name, base_dir, **kwargs) finally: if root_dir is not None: if logger is not None:
logger.debug("changing back to ‘%s‘", save_cwd)
os.chdir(save_cwd) return filenameshutil 对压缩包的处理是调用 ZipFile 和 TarFile 两个模块来进行的,详细:
zipfile 压缩解压 import zipfile# 压缩z = zipfile.ZipFile(‘laxi.zip‘, ‘w‘) z.write(‘a.log‘) z.write(‘data.data‘) z.close()# 解压z = zipfile.ZipFile(‘laxi.zip‘, ‘r‘) z.extractall() z.close()
tarfile 压缩解压 import tarfile# 压缩tar = tarfile.open(‘your.tar‘,‘w‘) tar.add(‘/Users/wupeiqi/PycharmProjects/bbs2.zip‘, arcname=‘bbs2.zip‘) tar.add(‘/Users/wupeiqi/PycharmProjects/cmdb.zip‘, arcname=‘cmdb.zip‘) tar.close()# 解压tar = tarfile.open(‘your.tar‘,‘r‘) tar.extractall() # 可设置解压地址tar.close()
CongifParser模块
用于对特定的配置进行操作(例如mysql的配置文件),当前模块的名称在 python 3.x 版本中变更为 configparser。
# 注释1 ; 注释2 [section1] k1 = v1 k2:v2 [section2] k1 = v1
import ConfigParser config = ConfigParser.ConfigParser() config.read(‘i.cfg‘) # ########## 读 ########## #secs = config.sections() #print secs #options = config.options(‘group2‘) #print options #item_list = config.items(‘group2‘) #print item_list #val = config.get(‘group1‘,‘key‘) #val = config.getint(‘group1‘,‘key‘) # ########## 改写 ########## #sec = config.remove_section(‘group1‘) #config.write(open(‘i.cfg‘, "w")) #sec = config.has_section(‘wupeiqi‘) #sec = config.add_section(‘wupeiqi‘) #config.write(open(‘i.cfg‘, "w")) #config.set(‘group2‘,‘k1‘,11111) #config.write(open(‘i.cfg‘, "w")) #config.remove_option(‘group2‘,‘age‘) #config.write(open(‘i.cfg‘, "w"))
logging模块
用于便捷记录日志且线程安全的模块
import logging logging.basicConfig(filename=‘log.log‘, format=‘%(asctime)s - %(name)s - %(levelname)s -%(module)s: %(message)s‘, datefmt=‘%Y-%m-%d %H:%M:%S %p‘, level=10) logging.debug(‘debug‘) logging.info(‘info‘) logging.warning(‘warning‘) logging.error(‘error‘) logging.critical(‘critical‘) logging.log(10,‘log‘)
对于等级:
CRITICAL = 50 FATAL = CRITICAL ERROR = 40 WARNING = 30 WARN = WARNING INFO = 20 DEBUG = 10 NOTSET = 0
只有大于当前日志等级的操作才会被记录。
对于格式,有如下属性可是配置:

time 模块
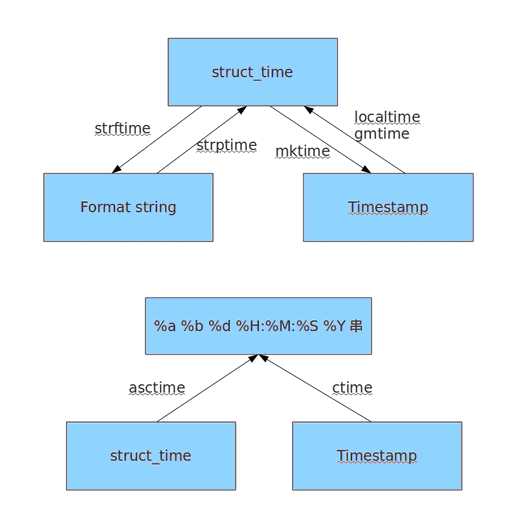
时间相关的操作,时间有三种表示方式:
时间戳 1970年1月1日之后的秒,即:time.time()
格式化的字符串 2014-11-11 11:11, 即:time.strftime(‘%Y-%m-%d‘)
结构化时间 元组包含了:年、日、星期等... time.struct_time 即:time.localtime()
print time.time()
print time.mktime(time.localtime())
print time.gmtime() #可加时间戳参数
print time.localtime() #可加时间戳参数
print time.strptime(‘2014-11-11‘, ‘%Y-%m-%d‘)
print time.strftime(‘%Y-%m-%d‘) #默认当前时间
print time.strftime(‘%Y-%m-%d‘,time.localtime()) #默认当前时间
print time.asctime()
print time.asctime(time.localtime())
print time.ctime(time.time())
import datetime
‘‘‘
datetime.date:表示日期的类。常用的属性有year, month, day
datetime.time:表示时间的类。常用的属性有hour, minute, second, microsecond
datetime.datetime:表示日期时间
datetime.timedelta:表示时间间隔,即两个时间点之间的长度
timedelta([days[, seconds[, microseconds[, milliseconds[, minutes[, hours[, weeks]]]]]]])
strftime("%Y-%m-%d")
‘‘‘
import datetime
print datetime.datetime.now()
print datetime.datetime.now() - datetime.timedelta(days=5)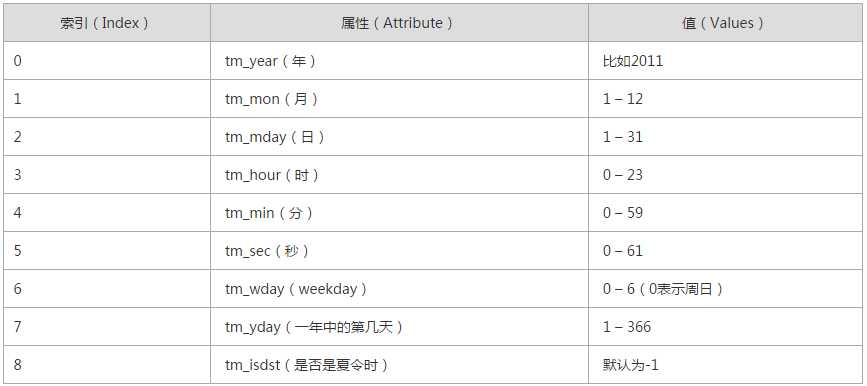
re模块
re模块用于对python的正则表达式的操作。
字符:
. 匹配除换行符以外的任意字符
\w 匹配字母或数字或下划线或汉字
\s 匹配任意的空白符
\d 匹配数字
\b 匹配单词的开始或结束
^ 匹配字符串的开始
$ 匹配字符串的结束
次数:
* 重复零次或更多次
+ 重复一次或更多次
? 重复零次或一次
{n} 重复n次
{n,} 重复n次或更多次
{n,m} 重复n到m次
1、match(pattern, string, flags=0)
从起始位置开始根据模型去字符串中匹配指定内容,匹配单个
正则表达式
要匹配的字符串
标志位,用于控制正则表达式的匹配方式
import re obj = re.match(‘\d+‘, ‘123uuasf‘) if obj: print obj.group()
# flags I = IGNORECASE = sre_compile.SRE_FLAG_IGNORECASE # ignore case L = LOCALE = sre_compile.SRE_FLAG_LOCALE # assume current 8-bit locale U = UNICODE = sre_compile.SRE_FLAG_UNICODE # assume unicode locale M = MULTILINE = sre_compile.SRE_FLAG_MULTILINE # make anchors look for newline S = DOTALL = sre_compile.SRE_FLAG_DOTALL # make dot match newline X = VERBOSE = sre_compile.SRE_FLAG_VERBOSE # ignore whitespace and comments
2、search(pattern, string, flags=0)
根据模型去字符串中匹配指定内容,匹配单个
re obj = re.search(, ) obj: obj.group()
3、group和groups
= re.search(, ).group() re.search(, ).group() re.search(, ).group() re.search(, ).group() re.search(, ).groups()
4、findall(pattern, string, flags=0)
上述两中方式均用于匹配单值,即:只能匹配字符串中的一个,如果想要匹配到字符串中所有符合条件的元素,则需要使用 findall。
re obj = re.findall(, ) obj
sub(pattern, repl, string, =, =)
= new_content = re.sub(, , ) new_content 相比于str.replace功能更加强大 6、split(pattern, string, maxsplit=0, flags=0) 根据指定匹配进行分组
content = = re.split(, content) content = = re.split(, content) inpp = inpp = re.sub(,,inpp) = re.split(, inpp, )
相比于str.split更加强大
mport .random() .randint(,) .randrange(,) checkcode = i (): current = .randrange(,) current != i: temp = (.randint(,)) : temp = .randint(,) checkcode += (temp) checkcode
http://timesnotes.blog.51cto.com/1079212/1716584
http://www.timesnotes.com/?p=118
本文出自 “Will的笔记” 博客,请务必保留此出处http://timesnotes.blog.51cto.com/1079212/1716584
原文地址:http://timesnotes.blog.51cto.com/1079212/1716584