标签:
http://www.cnblogs.com/luxiaoxun/archive/2013/05/09/3069036.html
Dynamic Time Warping(DTW)是一种衡量两个时间序列之间的相似度的方法,主要应用在语音识别领域来识别两段语音是否表示同一个单词。
1. DTW方法原理
在时间序列中,需要比较相似性的两段时间序列的长度可能并不相等,在语音识别领域表现为不同人的语速不同。而且同一个单词内的不同音素的发音速度也不同,比如有的人会把“A”这个音拖得很长,或者把“i”发的很短。另外,不同时间序列可能仅仅存在时间轴上的位移,亦即在还原位移的情况下,两个时间序列是一致的。在这些复杂情况下,使用传统的欧几里得距离无法有效地求的两个时间序列之间的距离(或者相似性)。
DTW通过把时间序列进行延伸和缩短,来计算两个时间序列性之间的相似性:
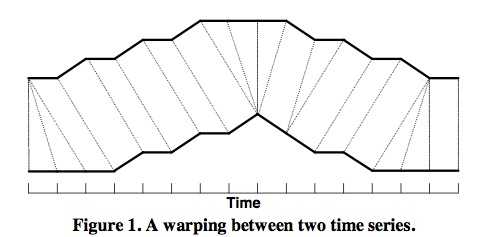
如上图所示,上下两条实线代表两个时间序列,时间序列之间的虚线代表两个时间序列之间的相似的点。DTW使用所有这些相似点之间的距离的和,称之为归整路径距离(Warp Path Distance)来衡量两个时间序列之间的相似性。
2. DTW计算方法:
令要计算相似度的两个时间序列为X和Y,长度分别为|X|和|Y|。
归整路径(Warp Path)
归整路径的形式为W=w1,w2,...,wK,其中Max(|X|,|Y|)<=K<=|X|+|Y|。
wk的形式为(i,j),其中i表示的是X中的i坐标,j表示的是Y中的j坐标。
归整路径W必须从w1=(1,1)开始,到wK=(|X|,|Y|)结尾,以保证X和Y中的每个坐标都在W中出现。
另外,W中w(i,j)的i和j必须是单调增加的,以保证图1中的虚线不会相交,所谓单调增加是指:
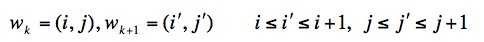
最后要得到的归整路径是距离最短的一个归整路径:
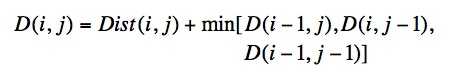
最后求得的归整路径距离为D(|X|,|Y|),使用动态规划来进行求解:
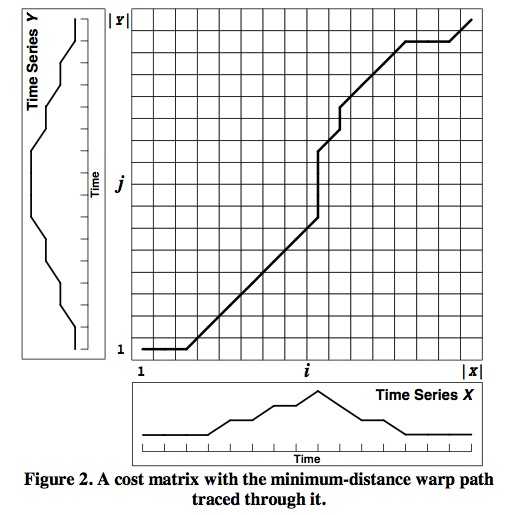
上图为代价矩阵(Cost Matrix) D,D(i,j)表示长度为i和j的两个时间序列之间的归整路径距离。
3. DTW实现:
matlab代码:

function dist = dtw(t,r)
n = size(t,1);
m = size(r,1);
% 帧匹配距离矩阵
d = zeros(n,m);
for i = 1:n
for j = 1:m
d(i,j) = sum((t(i,:)-r(j,:)).^2);
end
end
% 累积距离矩阵
D = ones(n,m) * realmax;
D(1,1) = d(1,1);
% 动态规划
for i = 2:n
for j = 1:m
D1 = D(i-1,j);
if j>1
D2 = D(i-1,j-1);
else
D2 = realmax;
end
if j>2
D3 = D(i-1,j-2);
else
D3 = realmax;
end
D(i,j) = d(i,j) + min([D1,D2,D3]);
end
end
dist = D(n,m);
C++实现:
dtwrecoge.h
 View Code
View Codedtwrecoge.cpp
View CodeC++代码下载:DTW算法.rar
http://blog.csdn.net/vanezuo/article/details/5586727

In time series analysis, dynamic time warping (DTW) is an algorithm for measuring similarity between two temporal sequences which may vary in time or speed. For instance, similarities in walking patterns could be detected using DTW, even if one person was walking faster than the other, or if there were accelerations and decelerations during the course of an observation. DTW has been applied to temporal sequences of video, audio, and graphics data — indeed, any data which can be turned into a linear sequence can be analyzed with DTW. A well known application has been automaticspeech recognition, to cope with different speaking speeds. Other applications include speaker recognition and onlinesignature recognition. Also it is seen that it can be used in partial shape matching application.
In general, DTW is a method that calculates an optimal match between two given sequences (e.g. time series) with certain restrictions. The sequences are "warped" non-linearly in the time dimension to determine a measure of their similarity independent of certain non-linear variations in the time dimension. This sequence alignment method is often used in time series classification. Although DTW measures a distance-like quantity between two given sequences, it doesn‘t guarantee the triangle inequality to hold.
This example illustrates the implementation of the dynamic time warping algorithm when the two sequences s and t are strings of discrete symbols. For two symbols x and y, d(x, y) is a distance between the symbols, e.g. d(x, y) = | x - y |
int DTWDistance(s: array [1..n], t: array [1..m]) {
DTW := array [0..n, 0..m]
for i := 1 to n
DTW[i, 0] := infinity
for i := 1 to m
DTW[0, i] := infinity
DTW[0, 0] := 0
for i := 1 to n
for j := 1 to m
cost:= d(s[i], t[j])
DTW[i, j] := cost + minimum(DTW[i-1, j ], // insertion
DTW[i , j-1], // deletion
DTW[i-1, j-1]) // match
return DTW[n, m]
}
We sometimes want to add a locality constraint. That is, we require that if s[i] is matched with t[j], then | i - j | is no larger than w, a window parameter.
We can easily modify the above algorithm to add a locality constraint (differences marked in bold italic). However, the above given modification works only if | n - m | is no larger than w, i.e. the end point is within the window length from diagonal. In order to make the algorithm work, the window parameter w must be adapted so that | n - m | ≤ w (see the line marked with (*) in the code).
int DTWDistance(s: array [1..n], t: array [1..m], w: int) {
DTW := array [0..n, 0..m]
w := max(w, abs(n-m)) // adapt window size (*)
for i := 0 to n
for j:= 0 to m
DTW[i, j] := infinity
DTW[0, 0] := 0
for i := 1 to n
for j := max(1, i-w) to min(m, i+w)
cost := d(s[i], t[j])
DTW[i, j] := cost + minimum(DTW[i-1, j ], // insertion
DTW[i, j-1], // deletion
DTW[i-1, j-1]) // match
return DTW[n, m]
Computing the DTW requires  in general. Fast techniques for computing DTW include SparseDTW[1] and the FastDTW.[2] A common task, retrieval of similar time series, can be accelerated by using lower bounds such as LB_Keogh[3] or LB_Improved.[4] In a survey, Wang et al. reported slightly better results with the LB_Improved lower bound than the LB_Keogh bound, and found that other techniques were inefficient.[5]
in general. Fast techniques for computing DTW include SparseDTW[1] and the FastDTW.[2] A common task, retrieval of similar time series, can be accelerated by using lower bounds such as LB_Keogh[3] or LB_Improved.[4] In a survey, Wang et al. reported slightly better results with the LB_Improved lower bound than the LB_Keogh bound, and found that other techniques were inefficient.[5]
Averaging for Dynamic Time Warping is the problem of finding an average sequence for a set of sequences. The average sequence is the sequence that minimizes the sum of the squares to the set of objects. NLAAF[6] is the exact method for two sequences. For more than two sequences, the problem is related to the one of the Multiple alignment and requires heuristics. DBA[7] is currently the reference method to average a set of sequences consistently with DTW. COMASA[8] efficiently randomizes the search for the average sequence, using DBA as a local optimization process.
A Nearest Neighbour Classifier can achieve state-of-the-art performance when using Dynamic Time Warping as a distance measure.[9]
An alternative technique for DTW is based on functional data analysis, in which the time series are regarded as discretizations of smooth (differentiable) functions of time and therefore continuous mathematics is applied.[10] Optimal nonlinear time warping functions are computed by minimizing a measure of distance of the set of functions to their warped average. Roughness penalty terms for the warping functions may be added, e.g., by constraining the size of their curvature. The resultant warping functions are smooth, which facilitates further processing. This approach has been successfully applied to analyze patterns and variability of speech movements.[11][12]
Due to different speaking rates, a non-linear fluctuation occurs in speech pattern versus time axis which needs to be eliminated.[13] DP-matching, which is a pattern matching algorithm discussed in paper "Dynamic Programming Algorithm Optimization For Spoken Word Recognition" by Hiroaki Sakoe and Seibi Chiba, uses a time normalisation effect where the fluctuations in the time axis are modeled using a non-linear time-warping function. Considering any two speech patterns, we can get rid off their timing differences by warping the time axis of one so that the maximum coincidence in attained with the other. Moreover, if the warping function is allowed to take any possible value, very less distinction can be made between words belonging to different categories. So, to enhance the distinction between words belonging to different categories, restrictions were imposed on the warping function slope.
标签:
原文地址:http://www.cnblogs.com/bnuvincent/p/4995782.html