标签:
本文旨在基于复旦中文语料库和神经网络模型构建中文的概率语言模型。
统计语言模型的一个目标是找到句子中不同词汇的联合分布,也就是找到一个单词序列出现的概率,一个训练好的统计语言模型可以被应用于语音识别、中文输入法、机器翻译等领域。在神经网络方法被提出之前,一个非常成功的构建语言模型的方法是 n-gram,n-gram 模型学习出统计出给出特定的单词序列时某个单词出现的条件概率,并且通过把一系列重叠的短语拼接起来,获得了模型的泛化能力。然而 n-gram 模型也有很多不如人意的地方。第一, n 的数值不能取得太大,否则会导致数据稀疏的问题;第二,它没有考虑到词汇与词汇之间语法和语义的相似性,也限制了它的泛化能力。
本文所采用的算法基于两篇论文 《A Neural Probabilistic Languge Model》 by Bengio et al. @2003 和 《Adam: A Method For Stochastic Optimization》 by P.Kingma & Lei ba @2015。神经网络模型将会同时学习两个目标:第一,学习出每个单词的分布式表示(分布式表示是指用多个编译单元来表示一个单词,也就是每个单词用一个n维的实数向量来表示,而传统的表示方法是把单词表示成文档的一个特征,包含单词则这个特征为1,否则为0。传统的表示方法只能表达单词出现与否,不能表达单词之间的距离);第二, 学习出单词序列的联合分布。此模型获得泛化能力的原因是,相似的单词(无论是语法上还是语义上)具有相似的分布式表示,因此作为模型的输入时将会得到相似的输出。
此神经网络模型的参数极多,因此可以基于MPI(Message Passing Interface,用于实施分布式并行计算的接口)和Linux机群实施并行计算。采用Adam算法,对比Bengio中所使用的算法,测试Adam算法在此数据集中的表现。
1 数据集预处理
1.1 数据集介绍
本文数据集来自复旦大学的中文语料库。复旦大学的中文语料库分为训练集和验证集两部分,两部分的文档数量基本相等,在将训练集与验证集合并之后,得到该语料库的一些基本信息如下:
类别总数量:20
文档总数量:19637
类别名称(类别代码):文档数量
Agriculture(C32):2043篇
Art(C3):1482篇
Communication(C17):52篇
Computer(C19):2715篇
Economy(C34):3201篇
Education(C5):120篇
Electronics(C16):55篇
Energy(C15):65篇
Enviornment(C31):2435篇
History(C7):934篇
Law(C35):103篇
Literature(C4):67篇
Medical(C36):104篇
Military(C37):150篇
Mine(C23):67篇
Philosophy(C6):89篇
Politics(C38):2050篇
Space(C11):1282篇
Sports(C39):2507篇
Transport(C29):116篇
文档示例:
1.2 数据集预处理
首先需要感谢复旦语料库整理人员的辛勤劳动,也要指出数据集中的瑕疵:
(1)主要采用了gbk编码而不是UTF-8,但是部分又不是采用的GBK编码(这给编码转换工作带来麻烦)。
(2)语料库包含训练集和测试集,分别包含9000多个文档,却有许多文档是重复的。
(3)训练集和测试集中的C35-Law中的部分文件是已经经过分词处理了的(分词结果很差,不可能直接使用)。
(4)有些文章只有文章头部,而没有实际的内容。
所以本文对数据集进行以下几个步骤的预处理:
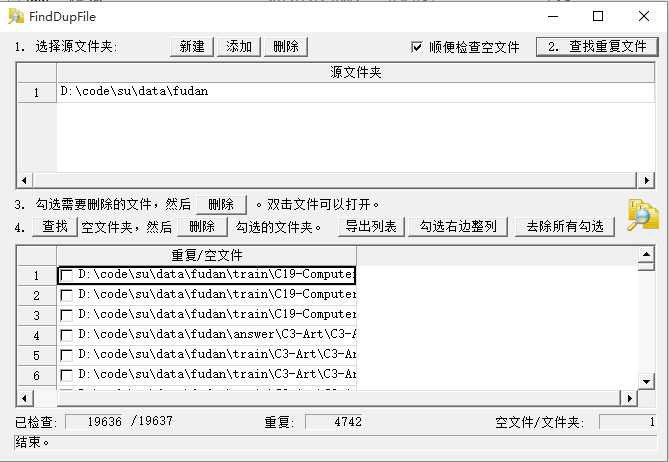
(1)使用FindDupFile工具找到train和answer文件夹的重复文件,删除之,删除后总的文件数目为14894。如图所示:
(2)把answer文件夹和train文件夹中的内容合并放到同一个目录。在去除重复处理之后,本文不采用原始的划分方式(即训练集:测试集=1:1)的方式,而是合并全部文件,保证每个文件有一个独有的标识符,每个分类划分70%作为训练集,10%为验证集,20%作为测试集。
(3)使用python把文件从gbk编码转换到utf-8编码。
(4)去除所有文档的空格和换行符。由于原始文档中的句子常常被换行符和空格隔开,甚至有些句子已经被分词处理过(而且分词效果很差),导致不能识别出句子,所以去除这些符号再来进行分词。去除空格也方便正则表达式精确匹配日期。
预处理程序见源文件:pre-proc.py。
ps:在 python中用正则表达式处理文本的编码范式是 : regex = re.compile(oldstring) ,然后 re.__( regex[, newstring], subject) 或者 regex.__([, newstring], subject)
re是一个模块,regex是正则表达式实例,subject是目标字符串。.subn 表示替换,.split 表示分隔,.match 表示匹配
如果不用正则表达式,则只能用字符串类中定义的对应函数 subject.__(oldstring, newstring)
2 数据库设计
本文基于MySQL存储数据。本文对模型的训练基于这样的观点:上一个句子中出现的单词对下一个句子中出现的单词也是有影响的,因此本文不会把文档划分成句子,而是直接按照单词在整篇文章中的出现顺序来进行训练,那么存储文本信息的schema设计为:
doc(name, class) —— 表示文档实体,在本文中类别字段主要用于分组,每个分组选取一部分作为测试集,其他作为验证集或者测试集。
word(term, vector) —— 表示单词实体。vector字段代表了单词向量,采用 “_” 分隔符分隔向量中的元素,向量维度m在实验中分别取 30,60,100
doc_term(doc, term, locatoin) —— 表示单词在文档中的位置。这个关系表也可以用于构建搜索引擎。
存储神经网络参数的schema设计为:
W1(start, end, weight)
W2(start, end, weight)
W3(start, end, weight)
b1(end, weight)
b2(end, weight)
每张表的具体含义在构建神经网络时会具体讨论。
3 分词
中文文本词汇之间没有分隔符,因此需要用特殊的方法进行切分,文本的切分方式会影响词汇集的大小 |V| 。分词的任务是把文档拆分成词汇序列,同时需要进行以下对词汇集的处理:词汇集合将去除标点;把数字映射成为一个特殊单词 *__num__*;把特别罕见的词汇映射成特殊单词 *__rare__*;把网址映射成 *__url__*;把日期映射成 *__date__*。
本文借助开源项目结巴分词实现中文分词(项目地址:https://github.com/fxsjy/jieba/ ),并在此项目的基础上进一步完善,例如基于正则表达式实现日期、网址的精确匹配。
2.1 精确匹配提取词组
基于正则表达式去除无关字符,以及精确匹配和提取日期、网址、邮箱、数学式等
2.2 结巴分词技术
基于Trie树生成有向无环状态转换图 采用动态规划方法寻找最大概率路径,切分语句 采用基于汉字成词能力的HMM模型和Viterbi算法,处理未登录词
2.3 分词结果
分词之后,不同的单词个数是 ,词汇集大小 |V| = 。
4 构建神经网络
3.1 并行神经网络模型
正则项 采用 adam 算法 输入
3.1 word2vector预先提取词向量,可以缩短收敛时间
探讨参数的数目
5 实验
学习率 0.001 ,m 取 30 60 100 , n取 3 5 10 20 单词向量的初始化 word2vec
当n 取 3 的时候,可以通过平面图直观的看出模型的预测效果。
5 n-gram
6 源代码
标签:
原文地址:http://www.cnblogs.com/xinchrome/p/5009726.html