标签:
关于KMP算法的原理网上有很详细的解释,我总结一下理解它的要点:
以这张图片为例子
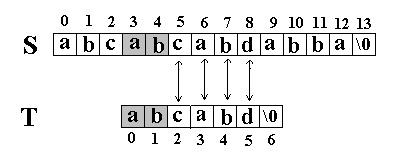
这里我们匹配到j=5时失效了,接下来就直接比较T[2](next[5]=2)和S[5]
那为什么可以跳过朴素算法里的几次比较,而直接用T[next[j]]比较就可以呢?
Q:next数组计算的原理是什么?
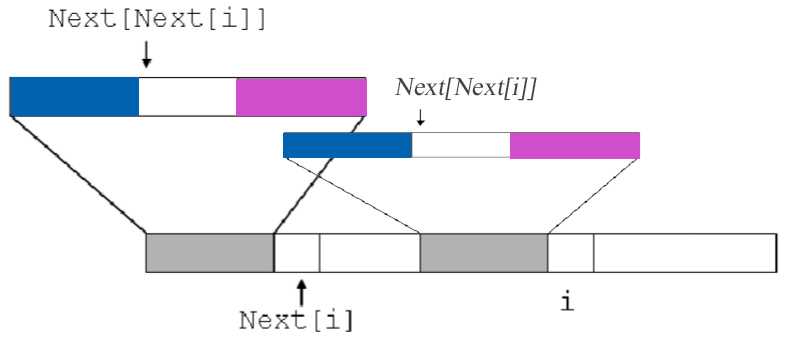
如果我们算完了next[i] ,现在要算next[i+1]了,我们让k=next[i],
if(T[k]==T[i])
{
k++;
i++;
next[i]=k;
}
整个的代码就是:
void get_next(const string &T,int *next){
int i=0,k=-1;
next[i]=k;
while(T[i]!=‘\0‘){
if(k==-1||T[k]==T[i])
{
k++;
i++;
next[i]=k;
}else{
k=next[k];
}
}
}
但是其实还可以再改进,因为例如
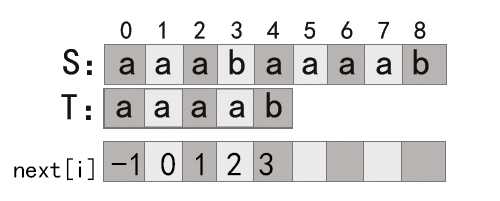
那么当i=3失配时,T的移动如下,
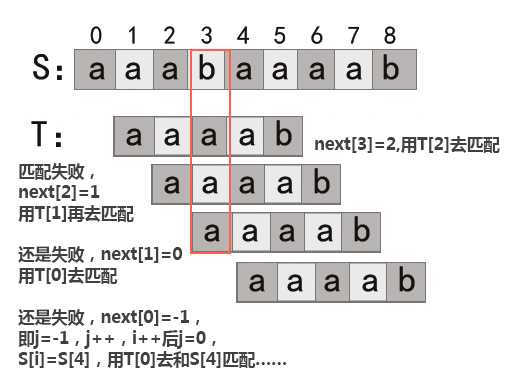
这样没有利用前面那么多a一样的特点,导致匹配次数比较多,所以我们这样改进:
因为T[3]失配了,而T[3]=T[2],所以T[2]也会失配,因为失配,所以还要用next寻找合适的匹配位置,所以next[3]=next[2]。在我们计算next[3]之前,next[2]已经计算出来,同理的,next[2]=next[1]=next[0]=-1。
所以改进的next的规则多了一条:
如果T[i]=T[i-1],next[i]=next[i-1]
在这里,next[0]=-1,next[1]=-1,next[2]=-1,next[3]=-1,next[4]=3,代码就变成了:
void get_next(const string &T,int *next)
{
int i=0,k=-1;
next[i]=k;
while(T[i]!=‘\0‘)
{
if(k==-1||T[k]==T[i])
{
k++;
i++;
if(T[i] != T[k])
next[i] = k;
else
next[i] = next[k];
}
else
{
k=next[k];
}
}
}
完整程序代码:
#include<iostream>
#include<cstring>
using namespace std;
void get_next(const string &T,int *next)
{
int i=0,k=-1;
next[i]=k;
while(T[i]!=‘\0‘)
{
if(k==-1||T[k]==T[i])
{
k++;
i++;
if(T[i] != T[k])
next[i] = k;
else
next[i] = next[k];
}
else
k=next[k];
}
}
/*
返回模式串T在主串P的第pos个字符起第一次出现的位置,
若不存在,则返回-1,下标从0开始,0<=pos<=P.size()(P的字符总个数)
*/
int KMP_index(const string &P,const string &T,int pos)
{
int *next=new int[T.size()+2];//动态分配next数组
get_next(T,next);
int i=0,j=pos;
while(i<T.size()&&j<P.size())
{
if(i==-1||P[j]==T[i])
{
j++;
i++;
}
else
i=next[i];
}
delete []next;
if(i>=T.size())
return j-i;
return -1;
}
int main()
{
char *T,*P;
T=new char[100];
P=new char[100];
cin>>P>>T;
cout<<KMP_index(P,T,0)<<endl;
return 0;
}
标签:
原文地址:http://www.cnblogs.com/flipped/p/5015722.html