标签:
今天想通过一些数据,来测试一下我的《基于信息熵的无字典分词算法》这篇文章的正确性。就写了一下MapReduce程序从MSSQL SERVER2008数据库里取数据分析。程序发布到hadoop机器上运行报SQLEXCEPTION错误
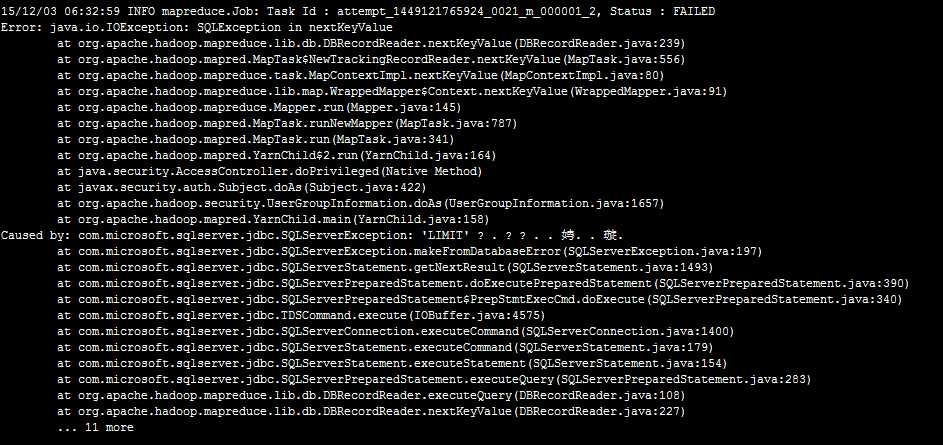
奇怪了,我的SQL语句中没有LIMIT,这LIMIT哪来的。我翻看了DBInputFormat类的源码,

1 protected RecordReader<LongWritable, T> createDBRecordReader(DBInputSplit split, 2 3 Configuration conf) throws IOException { 4 5 6 7 @SuppressWarnings("unchecked") 8 9 Class<T> inputClass = (Class<T>) (dbConf.getInputClass()); 10 11 try { 12 13 // use database product name to determine appropriate record reader. 14 15 if (dbProductName.startsWith("ORACLE")) { 16 17 // use Oracle-specific db reader. 18 19 return new OracleDBRecordReader<T>(split, inputClass, 20 21 conf, createConnection(), getDBConf(), conditions, fieldNames, 22 23 tableName); 24 25 } else if (dbProductName.startsWith("MYSQL")) { 26 27 // use MySQL-specific db reader. 28 29 return new MySQLDBRecordReader<T>(split, inputClass, 30 31 conf, createConnection(), getDBConf(), conditions, fieldNames, 32 33 tableName); 34 35 } else { 36 37 // Generic reader. 38 39 return new DBRecordReader<T>(split, inputClass, 40 41 conf, createConnection(), getDBConf(), conditions, fieldNames, 42 43 tableName); 44 45 } 46 47 } catch (SQLException ex) { 48 49 throw new IOException(ex.getMessage()); 50 51 } 52 53 }
DBRecordReader的源码
1 protected String getSelectQuery() { 2 3 StringBuilder query = new StringBuilder(); 4 5 6 7 // Default codepath for MySQL, HSQLDB, etc. Relies on LIMIT/OFFSET for splits. 8 9 if(dbConf.getInputQuery() == null) { 10 11 query.append("SELECT "); 12 13 14 15 for (int i = 0; i < fieldNames.length; i++) { 16 17 query.append(fieldNames[i]); 18 19 if (i != fieldNames.length -1) { 20 21 query.append(", "); 22 23 } 24 25 } 26 27 28 29 query.append(" FROM ").append(tableName); 30 31 query.append(" AS ").append(tableName); //in hsqldb this is necessary 32 33 if (conditions != null && conditions.length() > 0) { 34 35 query.append(" WHERE (").append(conditions).append(")"); 36 37 } 38 39 40 41 String orderBy = dbConf.getInputOrderBy(); 42 43 if (orderBy != null && orderBy.length() > 0) { 44 45 query.append(" ORDER BY ").append(orderBy); 46 47 } 48 49 } else { 50 51 //PREBUILT QUERY 52 53 query.append(dbConf.getInputQuery()); 54 55 } 56 57 58 59 try { 60 61 query.append(" LIMIT ").append(split.getLength()); //问题所在 62 63 query.append(" OFFSET ").append(split.getStart()); 64 65 } catch (IOException ex) { 66 67 // Ignore, will not throw. 68 69 } 70 71 72 73 return query.toString(); 74 75 }
终于找到原因了。
原来,hadoop只实现了Mysql的DBRecordReader(MySQLDBRecordReader)和ORACLE的DBRecordReader(OracleDBRecordReader)。
原因找到了,我参考着OracleDBRecordReader实现了MSSQL SERVER的DBRecordReader代码如下:
MSSQLDBInputFormat的代码:
1 /** 2 * 3 */ 4 package org.apache.hadoop.mapreduce.lib.db; 5 6 import java.io.IOException; 7 import java.sql.SQLException; 8 9 import org.apache.hadoop.conf.Configuration; 10 import org.apache.hadoop.io.LongWritable; 11 import org.apache.hadoop.mapreduce.Job; 12 import org.apache.hadoop.mapreduce.RecordReader; 13 14 /** 15 * @author summer 16 * MICROSOFT SQL SERVER 17 */ 18 public class MSSQLDBInputFormat<T extends DBWritable> extends DBInputFormat<T> { 19 20 public static void setInput(Job job, 21 Class<? extends DBWritable> inputClass, 22 String inputQuery, String inputCountQuery,String rowId) { 23 job.setInputFormatClass(MSSQLDBInputFormat.class); 24 DBConfiguration dbConf = new DBConfiguration(job.getConfiguration()); 25 dbConf.setInputClass(inputClass); 26 dbConf.setInputQuery(inputQuery); 27 dbConf.setInputCountQuery(inputCountQuery); 28 dbConf.setInputFieldNames(new String[]{rowId}); 29 } 30 31 @Override 32 protected RecordReader<LongWritable, T> createDBRecordReader( 33 org.apache.hadoop.mapreduce.lib.db.DBInputFormat.DBInputSplit split, 34 Configuration conf) throws IOException { 35 36 @SuppressWarnings("unchecked") 37 Class<T> inputClass = (Class<T>) (dbConf.getInputClass()); 38 try { 39 40 return new MSSQLDBRecordReader<T>(split, inputClass, 41 conf, createConnection(), getDBConf(), conditions, fieldNames, 42 tableName); 43 44 } catch (SQLException ex) { 45 throw new IOException(ex.getMessage()); 46 } 47 48 49 } 50 51 52 }
MSSQLDBRecordReader的代码:
1 /** 2 * 3 */ 4 package org.apache.hadoop.mapreduce.lib.db; 5 6 import java.io.IOException; 7 import java.sql.Connection; 8 import java.sql.SQLException; 9 10 import org.apache.hadoop.conf.Configuration; 11 12 13 /** 14 * @author summer 15 * 16 */ 17 public class MSSQLDBRecordReader <T extends DBWritable> extends DBRecordReader<T>{ 18 19 public MSSQLDBRecordReader(DBInputFormat.DBInputSplit split, 20 Class<T> inputClass, Configuration conf, Connection conn, DBConfiguration dbConfig, 21 String cond, String [] fields, String table) throws SQLException { 22 super(split, inputClass, conf, conn, dbConfig, cond, fields, table); 23 24 } 25 26 @Override 27 protected String getSelectQuery() { 28 StringBuilder query = new StringBuilder(); 29 DBConfiguration dbConf = getDBConf(); 30 String conditions = getConditions(); 31 String tableName = getTableName(); 32 String [] fieldNames = getFieldNames(); 33 34 // Oracle-specific codepath to use rownum instead of LIMIT/OFFSET. 35 if(dbConf.getInputQuery() == null) { 36 query.append("SELECT "); 37 38 for (int i = 0; i < fieldNames.length; i++) { 39 query.append(fieldNames[i]); 40 if (i != fieldNames.length -1) { 41 query.append(", "); 42 } 43 } 44 45 query.append(" FROM ").append(tableName); 46 if (conditions != null && conditions.length() > 0) 47 query.append(" WHERE ").append(conditions); 48 String orderBy = dbConf.getInputOrderBy(); 49 if (orderBy != null && orderBy.length() > 0) { 50 query.append(" ORDER BY ").append(orderBy); 51 } 52 } else { 53 //PREBUILT QUERY 54 query.append(dbConf.getInputQuery()); 55 } 56 57 try { 58 DBInputFormat.DBInputSplit split = getSplit(); 59 if (split.getLength() > 0){ 60 String querystring = query.toString(); 61 String id = fieldNames[0]; 62 query = new StringBuilder(); 63 query.append("SELECT TOP "+split.getLength()+"* FROM ( "); 64 query.append(querystring); 65 query.append(" ) a WHERE " + id +" NOT IN (SELECT TOP ").append(split.getEnd()); 66 query.append(" "+id +" FROM ("); 67 query.append(querystring); 68 query.append(" ) b"); 69 query.append(" )"); 70 System.out.println("----------------------MICROSOFT SQL SERVER QUERY STRING---------------------------"); 71 System.out.println(query.toString()); 72 System.out.println("----------------------MICROSOFT SQL SERVER QUERY STRING---------------------------"); 73 } 74 } catch (IOException ex) { 75 // ignore, will not throw. 76 } 77 78 return query.toString(); 79 } 80 81 82 83 }
mapreduce的代码
1 /** 2 * 3 */ 4 package com.nltk.sns.mapreduce; 5 6 import java.io.IOException; 7 import java.util.List; 8 9 import org.apache.hadoop.conf.Configuration; 10 import org.apache.hadoop.fs.FileSystem; 11 import org.apache.hadoop.fs.Path; 12 import org.apache.hadoop.io.LongWritable; 13 import org.apache.hadoop.io.Text; 14 import org.apache.hadoop.mapreduce.Job; 15 import org.apache.hadoop.mapreduce.MRJobConfig; 16 import org.apache.hadoop.mapreduce.Mapper; 17 import org.apache.hadoop.mapreduce.lib.db.DBConfiguration; 18 import org.apache.hadoop.mapreduce.lib.db.MSSQLDBInputFormat; 19 import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; 20 21 22 23 24 25 26 import com.nltk.sns.ETLUtils; 27 28 /** 29 * @author summer 30 * 31 */ 32 public class LawDataEtl { 33 34 public static class CaseETLMapper extends 35 Mapper<LongWritable, LawCaseRecord, LongWritable, Text>{ 36 37 static final int step = 6; 38 39 LongWritable key = new LongWritable(1); 40 Text value = new Text(); 41 42 @Override 43 protected void map( 44 LongWritable key, 45 LawCaseRecord lawCaseRecord, 46 Mapper<LongWritable, LawCaseRecord, LongWritable, Text>.Context context) 47 throws IOException, InterruptedException { 48 49 System.out.println("-----------------------------"+lawCaseRecord+"------------------------------"); 50 51 key.set(lawCaseRecord.id); 52 String source = ETLUtils.format(lawCaseRecord.source); 53 List<String> words = ETLUtils.split(source, step); 54 for(String w:words){ 55 value.set(w); 56 context.write(key, value); 57 } 58 } 59 } 60 61 static final String driverClass = "com.microsoft.sqlserver.jdbc.SQLServerDriver"; 62 static final String dbUrl = "jdbc:sqlserver://192.168.0.100:1433;DatabaseName=lawdb"; 63 static final String uid = "sa"; 64 static final String pwd = "cistjava"; 65 static final String inputQuery = "select sid,source from LawDB.dbo.case_source where sid<1000"; 66 static final String inputCountQuery = "select count(1) from LawDB.dbo.case_source where sid<1000"; 67 static final String jarClassPath = "/user/lib/sqljdbc4.jar"; 68 static final String outputPath = "hdfs://ubuntu:9000/user/lawdata"; 69 static final String rowId = "sid"; 70 71 public static Job configureJob(Configuration conf) throws Exception{ 72 73 String jobName = "etlcase"; 74 Job job = Job.getInstance(conf, jobName); 75 76 job.addFileToClassPath(new Path(jarClassPath)); 77 MSSQLDBInputFormat.setInput(job, LawCaseRecord.class, inputQuery, inputCountQuery,rowId); 78 job.setJarByClass(LawDataEtl.class); 79 80 FileOutputFormat.setOutputPath(job, new Path(outputPath)); 81 82 job.setMapOutputKeyClass(LongWritable.class); 83 job.setMapOutputValueClass(Text.class); 84 job.setOutputKeyClass(LongWritable.class); 85 job.setOutputValueClass(Text.class); 86 job.setMapperClass(CaseETLMapper.class); 87 88 return job; 89 } 90 91 public static void main(String[] args) throws Exception{ 92 93 Configuration conf = new Configuration(); 94 FileSystem fs = FileSystem.get(conf); 95 fs.delete(new Path(outputPath), true); 96 97 DBConfiguration.configureDB(conf, driverClass, dbUrl, uid, pwd); 98 conf.set(MRJobConfig.NUM_MAPS, String.valueOf(10)); 99 Job job = configureJob(conf); 100 System.out.println("------------------------------------------------"); 101 System.out.println(conf.get(DBConfiguration.DRIVER_CLASS_PROPERTY)); 102 System.out.println(conf.get(DBConfiguration.URL_PROPERTY)); 103 System.out.println(conf.get(DBConfiguration.USERNAME_PROPERTY)); 104 System.out.println(conf.get(DBConfiguration.PASSWORD_PROPERTY)); 105 System.out.println("------------------------------------------------"); 106 System.exit(job.waitForCompletion(true) ? 0 : 1); 107 108 } 109 }
辅助类的代码:
1 /** 2 * 3 */ 4 package com.nltk.sns; 5 6 import java.util.ArrayList; 7 import java.util.List; 8 9 import org.apache.commons.lang.StringUtils; 10 11 12 13 14 15 /** 16 * @author summer 17 * 18 */ 19 public class ETLUtils { 20 21 public final static String NULL_CHAR = ""; 22 public final static String PUNCTUATION_REGEX = "[(\\pP)&&[^\\|\\{\\}\\#]]+"; 23 public final static String WHITESPACE_REGEX = "[\\p{Space}]+"; 24 25 public static String format(String s){ 26 27 return s.replaceAll(PUNCTUATION_REGEX, NULL_CHAR).replaceAll(WHITESPACE_REGEX, NULL_CHAR); 28 } 29 30 public static List<String> split(String s,int stepN){ 31 32 List<String> splits = new ArrayList<String>(); 33 if(StringUtils.isEmpty(s) || stepN<1) 34 return splits; 35 int len = s.length(); 36 if(len<=stepN) 37 splits.add(s); 38 else{ 39 for(int j=1;j<=stepN;j++) 40 for(int i=0;i<=len-j;i++){ 41 String key = StringUtils.mid(s, i,j); 42 if(StringUtils.isEmpty(key)) 43 continue; 44 splits.add(key); 45 } 46 } 47 return splits; 48 49 } 50 51 public static void main(String[] args){ 52 53 String s="谢婷婷等与姜波等"; 54 int stepN = 2; 55 List<String> splits = split(s,stepN); 56 System.out.println(splits); 57 } 58 }
运行成功了
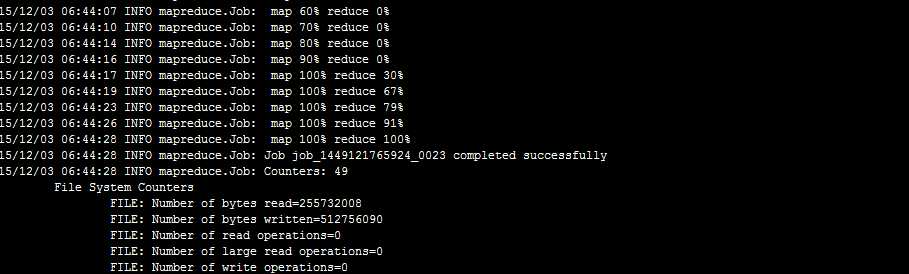
代码初略的实现,主要是为了满足我的需求,大家可以根据自己的需要进行修改。
实际上DBRecordReader作者实现的并不好,我们来看DBRecordReader、MySQLDBRecordReader和OracleDBRecordReader源码,DBRecordReader和MySQLDBRecordReader耦合度太高。一般而言,就是对于没有具体实现的数据库DBRecordReader也应该做到运行不报异常,无非就是采用单一的SPLIT和单一的MAP。
标签:
原文地址:http://www.cnblogs.com/bigdatafly/p/5018076.html
