标签:
本文目录
前面已经给大家介绍了iOS开发相关的一些基础知识,比如学习iOS开发需要什么准备、iOS开发的前景等等。在《开篇》这讲中说过:其实iOS开发就是开发iPhone\iPad上的软件,而要想开发一款软件,首先要学习程序设计语言。iOS开发需要学习的主要程序设计语言有:C语言、C++、Objective-C,其中C++、Objective-C都是以C语言为基础,从C语言衍生出来的。从这讲开始,我们就暂时抛开iOS相关的知识,沉下心来学习传说中的C语言。正式学习之前,先提醒一句:学习一门语言的语法是比较枯燥的事,很像是在学习1+1等于几,不可能说,学习C语言语法过程中就能马上做出一些好看的iPhone界面效果。大家要沉得住气,所谓苦尽甘来,没有语法的积累,如何能编写出好看的界面呢?
在学习C语言之前,先要了解一些计算机常识
因为计算机只能识别0和1,因此计算机所能识别的指令和数据都是用二进制数(0和1)来表示的。所谓二进制,就是用0和1来表示所有的数。不过我们日常生活中最常用的是十进制,用0~9来表示所有的数
给计算机灌输一些指令,它就能执行相应的操作,而计算机只能识别由0和1组成的指令。在计算机发展初期,计算机的指令长度为16,即以16个二进制数(0或1)组成一条指令,例如,用1011011000000000这条指令,是让计算机进行一次加法运算。因此,如果要想计算机执行一系列的操作,就必须编写许多条由0和1组成的指令,可以想象的到,这个工作量是如此巨大。
平时我们在计算机中存储的一些数据,比如文档、照片、视频等,都是以0和1的形式存储的。只不过计算机解析了这一大堆的0和1,以图形界面的形式将数据展示在我们眼前。
我们可以利用程序设计语言来编写程序,再将编好的程序运行到计算机上,计算机就能够按照程序中所说的去做。从计算机诞生至今,程序设计语言大致经历了3个发展阶段:机器语言、汇编语言、高级语言。其中,C语言属于高级语言。
在计算器诞生初期, 所有的计算机程序都是直接用计算机能识别的二进制指令来编写的,也就是说所有的代码里面只有0和1。这种程序设计语言就是“机器语言”。这些由0和1组成的二进制指令,又叫做“机器指令”
可以看出,机器语言很难掌握和推广,现在除了计算机生产厂家的专业人员外,绝大多数的程序员已经不再去学习机器语言了。
由于汇编语言依赖于硬件,代码可移植性差,符号又多又难记,于是人类就发明了非常接近自然语言的高级语言。后面要学习的C语言就是高级语言。
用高级语言编写的程序不能直接被计算机识别,需要经编译器翻译成二进制指令后,才能运行到计算机上
下面是2013年3月份的编程语言热门排行榜
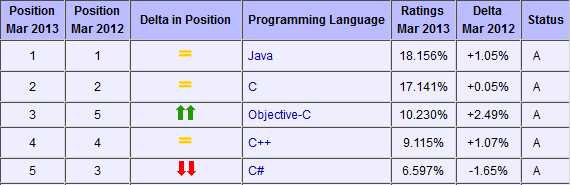
从C语言诞生至今,它的热度一点也没减过,前两名基本上都是Java和C
计算机的基本功能就是计算,因此一门程序设计语言的计算能力是非常重要的。C语言提供了34种运算符,计算类型极其丰富,其中包括了最基本的加减乘除运算。
跟汇编语言一样,C语言可以直接操作硬件,允许直接对位、字节、地址进行操作(位、字节、地址是计算机最基本的工作单元),可以说几乎没有C语言做不了的事情。
目标代码,就是经编译器翻译后的二进制代码。C语言的目标代码执行效率非常高。
在一个环境上用C语言编写的程序,不改动或稍加改动,就可移植到另一个完全不同的环境中运行。
上面所说的都是C语言的优点,它有个非常明显的缺点:语法限制不严格。这样就导致初学者对C语言语法不能理解得很透彻,而且在开发过程中也会带来很多容易忽略的问题。
从UNIX操作系统的成功后,C语言得到了广泛地应用,从大型主机到小型微机,都有C语言活跃的身影,也衍生了很多个版本的C语言。长期以往,C语言将可能成为一门有多个变种、松散的语言。一门正式的语言,肯定要有个标准才行,不然就乱套了。为了改变这种局面,1983年美国国家标准局(American National Standards Institute,简称ANSI)成立了一个委员会,开始制定C语言标准的工作。1989年C语言标准被批准,这个版本的C语言标准通常被称为ANSI C
当前移动开发的趋势已经势不可挡,这个系列希望浅谈一下个人对IOS开发的一些见解,这个IOS系列计划从几个角度去说IOS开发:
这么看下去还有大量的内容需要持续补充,但是今天我们从最基础的C语言开始,C语言部分我将分成几个章节去说,今天我们简单看一下C的一些基础知识,更高级的内容我将放到后面的文章中。
基础知识分为以下几点内容(注意:循环、条件语句在此不再赘述):
--------------------------------------------------------------------------------------------------------------------------------------------------------------
既然是IOS开发系列首先看一下在Mac OS X中的C的运行
打开Xcode

选择命令行程序

填写项目名称并选择使用C语言

选择保存目录

自动生成如下代码

OK,在Xcode上我们编写自己的程序如下
//
// main.c
// C语言基础
//
// Created by Kenshin Cui on 14-7-12.
// Copyright (c) 2014年 cmjstudio. All rights reserved.
//
#include <stdio.h>
void showMessage(){
printf("Hello,World!\n");
}
int main(int argc, const char * argv[]) {
showMessage();
return 0;
}
在上面的程序中我们需要解释几点:
注意:#include 包含文件时有两种方式:使用<>和””。区别就是<>包含只会查找编译器库函数文件,因此适用于包含库函数;而“”包含则首先查找程序当前目录,如果没有找到则查找库函数路径,因此适用于自定义文件;

C语言的运行分为两大步:编译和链接
在大型项目开发中程序中所有的代码都写到一个文件中是不现实的,我们通常将一个子操作分为两个文件:.c文件和.h文件。在.c文件中实现对应的函数,在.h中进行函数声明,这样只要在主函数上方包含对应的头文件就可以将子操作分离出来而且不用考虑顺序问题。例如改写“Hello World”的例子(注意message对应的.c和.h文件名完全可以不相同,但是出于规范的目的我们还是取相同的文件名):
message.h
// // Message.h // C语言基础 // // Created by Kenshin Cui on 14-7-12. // Copyright (c) 2014年 cmjstudio. All rights reserved. // void showMessage();
message.c
//
// Message.c
// C语言基础
//
// Created by Kenshin Cui on 14-7-12.
// Copyright (c) 2014年 cmjstudio. All rights reserved.
//
#include <stdio.h>
void showMessage(){
printf("Hello,World!\n");
}
main.c
//
// main.c
// C语言基础
//
// Created by Kenshin Cui on 14-7-12.
// Copyright (c) 2014年 cmjstudio. All rights reserved.
//
#include <stdio.h>
#include "Message.h"
int main(int argc, const char * argv[]) {
showMessage();
return 0;
}
可以发现程序仍然可以正常运行,但是我们思考一个问题:如果我们不分成两个文件,直接在主函数文件中包含message.c是否也可以正常运行呢?答案是否定的,原因是由于编译生成的两个文件main.obj和 message.obj在链接时会发现main.obj中已经有message.obj中定义的showMessage函数,抛出“标示符重复”的错误。


从上图我们可以清晰的看到C语言的数据类型结构,当然对于这些类型我们还有一些类型修饰符(或叫限定符)
对于类型修饰符需要做如下解释
当然有时候我们必须清楚每个类型占用的字节,下表列出常用数据类型占用的存储空间

注意:char类型是最小的数据类型单位,在任何类型的编译器下都是占用1个字节,char类型的变量赋值可以直接赋值等于某个字符也可以赋值为整数(对应的ASCII值);可以使用两个long来修饰一个整形(就是经常使用的8字节的整形long long),但是两个long不能修饰double而且也不存在两个short,否则编译警告;一个浮点型常量如果后面加上f编译器认为它是float类型,否则认为double类型,例如10.0是double类型,10.0f是float类型。
C语言中有34中运算符,同C#、Java等语言没有太大的区别,这里指列出一些注意事项
针对上面几点看以下例子
//
// main.c
// C语言基础
//
// Created by Kenshin Cui on 14-7-12.
// Copyright (c) 2014年 cmjstudio. All rights reserved.
//
#include <stdio.h>
int main(int argc, const char * argv[]) {
int a=2>1,b=2<1,c=99,d=0;
int f=0,g=0,h=0,e=(f=3,g=4,h=5);
a>0;//没有保存运算结果
printf("%d,%d\n",a,b);//结果:1,0
if(c){//可以通过
printf("true.\n");
}
if(d){//无法通过
printf("false\n");
}
printf("%d\n",e);//结果:5
return 0;
}
printf()函数用于向标准输出设备输出数据,配合格式符可以完成强大的输出功能,上面的例子中我们已经使用了这个函数。
通常我们的输出不是固定内容而是包含某些变量,此时需要用到格式符,常用格式符如下

对于格式符的输出宽度和浮点数的小数位我们可以进行精确的控制
//
// main.c
// C语言基础
//
// Created by Kenshin Cui on 14-7-12.
// Copyright (c) 2014年 cmjstudio. All rights reserved.
//
#include <stdio.h>
int main(int argc, const char * argv[]) {
int a=16;
float b=79.3f;
printf("[a=%4d]\n",a);
printf("[a=%-4d]\n",a);
printf("[b=%10f]\n",b);
printf("[b=%.2f]\n",b);
printf("[b=%4.2f]\n",b);
return 0;
}
运行结果如下

从运行结果我们不难发现格式符%前的正数可以设置前端补齐,负数设置后端对齐,如果数据的总长度超过设置的修饰长度,则按照实际长度显示;小数点后的整数用于控制小数点后保留小数位的长度。
scanf()函数用于从标准输入设备接收输入数据
//
// main.c
// C语言基础
//
// Created by Kenshin Cui on 14-7-12.
// Copyright (c) 2014年 cmjstudio. All rights reserved.
//
#include <stdio.h>
int main(int argc, const char * argv[]) {
int a,b,c;
scanf("%d,%d,%d",&a,&b,&c);//此时需要输入:1,2,3 然后回车
printf("a=%d,b=%d,c=%d\n",a,b,c);
return 0;
}
对于scanf()函数我们需求强调几点
1)for循环
c语言中的for循环语句使用最为灵活,不仅可以用于循环次数已经确定的情况,而且可以用于循环次数不确定而只给出循环结束条件的情况,它完全可以代替while语句.
for(表达式 1;表达式 2;表达式 3)语句
它的执行过程如下:
(1)先求表达式 1.
(2)求表达式2,若其值为真(值为非0),则执行for语句中指定的内嵌语句,然后执行下面第三步 做若为
假(值为0),则结束循环,转到第5步.
(3)求解表达式3
(4)转回上面第(2)步骤继续执行;
(5)结束循环,执行for语句下面的一个语句;
for(循环变量赋初值;循环条件;循环变量增值)语句
如
它的执行相当于
显然,用for语句更简单、方便。
说明:
(1)for语句的一般形式中的"表达式1"可以省略,此时应在for语句之前给循环变量赋初值.注意省略表达式1时,其后的分号不能省略.如for(;i<=100;i++){....};
(2)如果表达式2省略 即不判断循环条件,循环无终止地循环下去,也就是认为表达式2始终为真.
例如:for(i=1;;i++){.....};
相当于
(3)表达式3也可以省略,但此时程序设计者应另外设法保证循环能正常结束.如:
这个例子的循环增量没有放在表达式三的位置 而是作为循环体的一部分 其效果是一样的.
(4)可以省略表达式1和表达式3,只有表达式2 即只给循环条件.
如
(5)三个表达式都可以省略,如:
for(;;)语句
相当于
while(1)语句
即不设初值 不判断条件(认为表达式2为真值)循环变量不增值,无终止的执行循环体.
(6)表达式1也可以是设置循环变量初值的赋值表达式,也可以是与循环变量无关的其他表达式.如:
2)while循环:
#include <stdio.h> int main(void) { int i=0; while (i<10) { i++; printf("%d\n", i); } getchar(); return 0; }
3.) do while 循环:
#include <stdio.h> int main(void) { int i=0; do { i++; printf("%d\n", i); } while (i<10); getchar(); return 0; }
3.1 while 与 do while 的区别:
#include <stdio.h> int main(void) { int i=10; while (i<10) { printf("while"); //这个不会执行 } do { printf("do while"); //这个会执行 } while (i<10); getchar(); return 0; }
3.2. break 与 continue:
#include <stdio.h> int main(void) { int i=0; while (i<10) { i++; if (i == 8) break; /* 不超过 8 */ if (i%2 == 0) continue; /* 只要单数 */ printf("%d\n", i); } getchar(); return 0; }
3.3 无限循环:
#include <stdio.h> int main(void) { int i=0; while (1) //或 while (!0) { i++; printf("%d\n", i); if (i == 100) break; } getchar(); return 0; }
1)if语句
1. 常规:
#include <stdio.h> int main(void) { int i; for (i = 0; i < 10; i++) { if (i%2 == 0) printf("%d 是偶数\n", i); if (i%2 != 0) printf("%d 是奇数\n", i); } getchar(); return 0; }
#include <stdio.h> int main(void) { int i; for (i = 0; i < 10; i++) { if (i > 4) printf("%d\n", i); else printf("*\n"); } getchar(); return 0; }
2. && 与 ||
#include <stdio.h> int main(void) { int i; for (i = 0; i < 10; i++) { if (i>3 && i<7) { printf("%d\n", i); } } getchar(); return 0; }
#include <stdio.h> int main(void) { int i; for (i = 0; i < 10; i++) { if (i<3 || i>7) { printf("%d\n", i); } } getchar(); return 0; }
3. & 与 |
#include <stdio.h> int main(void) { int i; for (i = 0; i < 10; i++) { if (i>3 & i<7) { printf("%d\n", i); } } getchar(); return 0; }
#include <stdio.h> int main(void) { int i; for (i = 0; i < 10; i++) { if (i<3 | i>7) { printf("%d\n", i); } } getchar(); return 0; }
4. !
#include <stdio.h> int main(void) { int i; for (i = 0; i < 10; i++) { if (!(i > 4)) { printf("%d\n", i); } } getchar(); return 0; }
5. 梯次:
#include <stdio.h> int main(void) { int i; for (i = 0; i < 10; i++) { if (i/2 == 0) { printf("%d: 0-1\n", i); } else if(i/2 == 1) { printf("%d: 2-3\n", i); } else if(i/2 == 2) { printf("%d: 4-5\n", i); } else { printf("%d: 6-9\n", i); } } getchar(); return 0; }
6. 嵌套:
#include <stdio.h> int main(void) { int i; for (i = 0; i < 10; i++) { if (i > 2) { if (i%2 == 0) { printf("%d\n", i); } } } getchar(); return 0; }
7. 简化的 if 语句(? :)
#include <stdio.h> int main(void) { int i,j; for (i = 0; i < 10; i++) { j = i<5 ? 1 : 5; // printf("%d\n", j); } getchar(); return 0; }
#include <stdio.h> int main(void) { int i,j; for (i = 0; i < 10; i++) { i<5 ? printf("1\n") : printf("5\n"); } getchar(); return 0; }
2)switch语句
C语言作为底层开发最常用的语言,要理解C语言的运行机制,阅读对应的汇编代码是非常有帮助的。我会在下篇分析一下汇编中的switch。
这次是上篇,就当作一个热身吧,看看你是否已经了解switch语句是怎么执行的。
阅读下面的代码,请问,从语法上看,有多少处错误?

1 #include <stdio.h>
2 #define TWO 2
3
4 int main(int argc, char ** argv)
5 {
6 switch(argc) {
7 case 1:
8 printf("case 1\n");
9 case TWO:
10 printf("case 2\n");
11 case 3:
12 printf("case3\n");
13 xxx:
14 printf("xxx\n");
15 default:
16 printf("default\n");
17 break;
18 case 4:
19 printf("case 4\n");
20 goto xxx;
21 }
22 return 0;
23 }
好了看完了,是不是有以下的疑惑?
TWO是宏定义,可以写在case后面吗?有的地方为什么没有break?有没有关系?xxx是什么东西?default不是应该放在最后吗?
如果你对这些疑惑都有很清楚的答案,那么你会回答,这段代码从语法上来讲,错误个数是0. 是的,没有错误。
我们可以编译并成功生成a.out
看一下运行的结果。
randy@ubuntu:~/C_Language/switch$ ./a.out case1case2case3xxxdefault<br>randy@ubuntu:~/C_Language/switch$ ./a.out acase2case3xxxdefault<br>randy@ubuntu:~/C_Language/switch$ ./a.out a bcase3xxxdefault<br>randy@ubuntu:~/C_Language/switch$ ./a.out a b ccase 4xxxdefault<br>randy@ubuntu:~/C_Language/switch$ ./a.out a b c ddefault |
小结:
1.语法,"case 常量表达式: 语句序列”,宏定义的TWO经过预编译被替换成2.
2.switch不会在每个case标签后面的语句执行完毕后自动终止。一旦执行某个case语句,程序将会一次执行后面所有的case,除非遇到break语句。
这被称之为“fall through”。
3.switch内部的任何语句都可以加上标签,所有的case都是可选的,任何形式的语句,包括带标签的语句都是允许的(xxx)。
4.break中断了什么?break语句事实上跳出的是最近的那层循环语句或switch语句。
5.各个case和default顺序可以是任意的,如果没有default,而且每个case选项都不符合,则相当于switch语句没有执行。
-------------------------------------------------------------------------------------------------------------
想要深入地理解语言的运行机理,阅读汇编代码是很有帮助的。
前奏:我们这里用的汇编代码格式是AT&T的,这个微软的intel格式不一样。
AT&T格式是GCC,OBJDUMP等一些其他我们在linux环境下常用工具的默认格式。
今天就一起再来看看switch语句吧。
关键词:跳转,跳转表
先来一个最简单的例子:
1 int switch_eg(int x, int n)
2 {
3 int result = x;
4
5 switch (n) {
6 case 100:
7 result += 10;
8 break;
9 case 102:
10 result -= 10;
11 break;
12 default:
13 result = 0;
14 }
15
16 return result;
17 }
看一下其汇编代码:我会逐条注释。
命令是gcc -O1 -S test2.c
1 .file "test2.c" 2 .text 3 .globl switch_eg 4 .type switch_eg, @function 5 switch_eg: 6 .LFB0: 7 .cfi_startproc 8 movl 4(%esp), %ecx //x在esp+4的位置,存入寄存器ecx 9 movl 8(%esp), %edx //n在esp+8的位置,存入寄存器edx 10 leal 10(%ecx), %eax //将ecx的值+10存入eax,也就是x+10 11 cmpl $100, %edx //将n和100比较 12 je .L2 //n==100,跳到L2 13 subl $10, %ecx //n!=100,x=x-10 14 cmpl $102, %edx //n和102比较 15 movl $0, %eax //eax=0 16 cmove %ecx, %eax //如果n==102,eax=ecx 17 .L2: 18 rep //返回,result存在eax 19 ret 20 .cfi_endproc 21 .LFE0: 22 .size switch_eg, .-switch_eg 23 .ident "GCC: (Ubuntu/Linaro 4.6.3-1ubuntu5) 4.6.3" 24 .section .note.GNU-stack,"",@progbits
好了,对着注释看,是不是很简单呢。由此我们知道,switch语句实际上也是一种条件语句,而条件语句的核心是跳转。聪明的你应该还会想到跳转的标签个数应该是和case语句的分支个数成正比的。
可是,当case语句分支很多时,岂不是各种jmp?编译器很聪明的使用了一种叫跳转表的方法来解决这个问题。
其实也简单,跳转表的思想就是将要跳转的代码的地址存入一个数组中,然后根据不同的条件跳转到对应的地址处,就像访问数组一样。
空说太枯燥了,还是看个例子吧。(例子来源:深入理解计算机系统3.6.7)
C:
1 int switch_eg(int x, int n) {
2 int result = x;
3 switch (n) {
4 case 100:
5 result *= 13;
6 break;
7
8 case 102:
9 result += 10;
10 /* fall throuth */
11
12 case 103:
13 result += 11;
14 break;
15
16 case 104:
17 case 106:
18 result *= result;
19 break;
20
21 default:
22 result = 0;
23 }
24
25 return result;
26 }
同样的看一下对应的汇编。我省略了一些无关的代码。
1 movl 4(%esp), %eax 2 movl 8(%esp), %edx 3 subl $100, %edx 4 cmpl $6, %edx 5 ja .L8 6 jmp *.L7(,%edx,4) 7 .section .rodata 8 .align 4 9 .align 4 10 .L7: 11 .long .L3 12 .long .L8 13 .long .L4 14 .long .L5 15 .long .L6 16 .long .L8 17 .long .L6 18 .text 19 .L3: 20 leal (%eax,%eax,2), %edx 21 leal (%eax,%edx,4), %eax 22 ret 23 .L4: 24 addl $10, %eax 25 .L5: 26 addl $11, %eax 27 ret 28 .L6: 29 imull %eax, %eax 30 ret 31 .L8: 32 movl $0, %eax 33 ret
解释一下关键点:
首先生成了一张跳转表,以L7为基准,4自己为对齐单位,加上偏移就能跳转到相应的标签。
比如,L7+0就是跳到L3处,L7+4就是跳转到L8处,依次类推。
7 .section .rodata 8 .align 4 9 .align 4
10 .L7: 11 .long .L3 12 .long .L8 13 .long .L4 14 .long .L5 15 .long .L6 16 .long .L8 17 .long .L6
第6行: jmp *.L7(,%edx,4)
表示 goto *jt[index],举个例子,假设现在n是102,edx里面是2(102-100),查表得L7+2*4处,即跳到L4处。
23 .L4: 24 addl $10, %eax
将eax的值+10,这和C是对应的。
8 case 102: 9 result += 10;
注意到L4后面没有ret了,这就是我们上篇所说的fall through规则。不清楚可以看一下上篇的例子C语言拾遗(四):分析switch语句机制---上篇。
好了,其他的分支,各位可以自己用其他例子验证一下,看是不是跟C语言代码逻辑是一样的,欢迎讨论。
小结:
swith语句的本质是条件语句,条件语句的本质是跳转。
当case分支多了的时候(一般大于四个时),编译器巧妙地通过跳转表来访问代码位置。
-------------------------------------------------------------------------------------------------------------------------------------------------------------
C语言其他常用知识点
C 语言
示例
1、运算符
cOperator.h
#ifndef _MYHEAD_OPERATOR_ #define _MYHEAD_OPERATOR_ #ifdef __cplusplus extern "C" #endif char *demo_cOperator(); #endif
cOperator.c
/*
* 运算符
*/
#include "pch.h"
#include "cOperator.h"
#include "cHelper.h"
char *demo_cOperator()
{
// 算数运算符:+, -, *, /, %, ++, --
// 关系运算符:>, <, ==, >=, <=, !=
// 逻辑运算符:&&, ||, !
// 位操作运算符:&, |, ~, ^, <<, >>
// & - 按位与:都是 1 则为 1,其他情况为 0;比如 1001 & 0001 = 0001
// | - 按位或:有一个是 1 则为 1,其他情况为 0;比如 1001 | 0001 = 1001
// ^ - 按位异或:不一样则为 1,一样则为 0;比如 1001 | 0001 = 1000
// ~ - 按位非:~1001 = 0110
// 赋值运算符:=, +=, -=, *=, /=, %=, &=, |=, ^=, >>=, <<=
// 条件运算符:三目运算符 ?:
// 指针运算符:* 用于取内容 & 用于取地址
// i++, i本身加1,表达式i++的值为i加1前的值
// ++i, i本身加1,表达式++i的值为i加1后的值
int i = 0;
i++; // 此处 i 的值为 1, i++ 的值为 0
int j = 0;
++j; // 此处 j 的值为 1, ++j 的值为 1
// sizeof - 是 C 里面的关键字,而不是函数,其是求字节数运算符
// 计算一个数据类型所占用空间的大小
int intSize = sizeof(short); // 2, 不同平台下 int short long 之类的占用空间可能不一样,用 sizeof 就可以知道其占用空间的大小了
char *str = "abcdefghijklmnopqrstuvwxyz";
int dataSize = sizeof(str); // 4, 这里计算的是 str 指针所占用空间的大小
return str_concat2(int_toString(intSize), int_toString(dataSize));
}
2、表达式,条件语句,循环语句,转向语句,空语句等
cStatement.h
#ifndef _MYHEAD_STATEMENT_ #define _MYHEAD_STATEMENT_ #ifdef __cplusplus extern "C" #endif char *demo_cStatement(); #endif
cStatement.c
/*
* 表达式,条件语句,循环语句,控制语句,空语句等
*/
#include "pch.h"
#include "cStatement.h"
#include "cHelper.h"
char *demo_cStatement()
{
// 所谓表达式是由运算及运算对象所组成的具有特定含义的式子
// 所谓表达式语句就是由表达式加上分号“;”组成的
// i++, i本身加1,表达式i++的值为i加1前的值
// ++i, i本身加1,表达式++i的值为i加1后的值
// 复合语句(拿大括号括起来)
{
int p1 = 1;
int p2 = 2;
}
// 只有“;”的语句就叫做空语句
while (0)
{
; // 这一句就是空语句
}
// 上面的等于下面的
while (0)
;
// 上面的等于下面的
while (0);
// 分支结构的语句(if else)
int a = 0, b;
if (a == 1) b = 1; // 注意:变量 a 在此之前如果不初始化的话,则这里是无法编译过的,也就是说未赋值的变量不能使用
if (a == 1)
b = 2;
else if (a == 2)
b = 3;
else
b = 4;
// 分支结构的语句(switch case)
int x = 0, y;
switch (x)
{
case 1:
y = 2;
break;
case 2:
y = 3;
break;
default:
y = 4;
}
// 分支结构的语句(?:)
int m, n = 0;
m = n == 1 ? 2 : 3;
// 循环语句(while)
int i = 0;
while (i < 100)
{
i++;
}
// 循环语句(do while)
int j = 0;
do
{
j++;
}
while (j < 100);
// 循环语句(for)
for (i = 0; i < 100; i++)
{
}
for (i = 0; i < 100; )
{
i++;
}
for (i = 0, j = 0; i < 100 && j < 100; i++, j++)
{
i++;
j++;
}
int z = 0;
for ( ; z < 100; )
{
z++;
}
// 转向语句:break - 跳出循环
// 转向语句:continue - 跳过循环体的剩余的语句,直接进入下一次循环判断
// 转向语句:return - 退出函数,并提供返回值
// 转向语句:goto - 跳转至指定的标识符处,并执行其后的语句(需合理使用,比如多层嵌套语句退出时,使用 goto 就是很合理的)
int result = 0;
myAnchor: // 自定义标识符(标识符加冒号)
if (result == 1)
{
result = 100;
}
if (result == 0)
{
result = 1;
goto myAnchor; // 跳转至指定的标识符处(myAnchor:),并执行其后的语句
}
return str_concat2("看代码及注释吧", int_toString(result));
}
标签:
原文地址:http://www.cnblogs.com/CoderAlex/p/5018189.html