标签:
框架:类库的集合。
集合框架:用来表示和操作的统一的架构,包含了实现集合的接口与类。
集合又称为容器(containers),简单的来说集合框架就是一个对象,可以将具有相同性质的多个元素汇聚成一个整体。集合被用于存储、获取操纵和传输聚合的数据----存放数据的容器。
集合框架的核心接口为Collection、 List、 Set 和 Map.
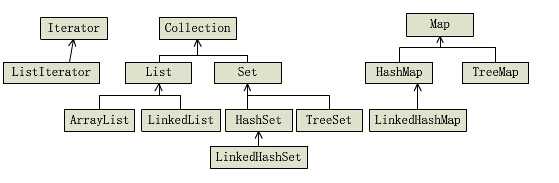
Collection是一组各自独立的元素,通常拥有相同的套用规则。Set 、List由它派生。
基本操作:
|
方法 |
方法作用 |
|
boolean add(Object obj) |
将指定对象obj新增至集合内,增加成功传回true,否则传回false |
|
boolean addAll(Collection c) |
将指定集合c内所有元素新增至集合内,增加成功传回true,否则传回false |
|
viod clear() |
将集合内所有元素清空 |
|
boolean isEmpty() |
检查集合内是否没有任何元素,如果是传回true,否则传回false |
|
Iterator iterator() |
将集合内的元素信息转存成Iterator对象 |
|
boolean remove(Object obj) |
将指定元素obj从集合内移除,成功移除传回true,否则传回false |
|
int size() |
将集合内的元素总数传回 |
|
Object[] toArray() |
将集合内的元素转存到数组后传回该数组 |
containsAll()方法:查找当前集合是否包含了另外一个集合的所有元素,即另外一个元素是否是当前集合的子集。
addAll()方法:将另外一个集合中的所有元素添加到当前集合中,类似于“并”操作。
clear()方法:删除当前集合中的所有元素。
removeAll()方法:类似于clear()方法,但是删除的是集合的一个子集。
retainAll()方法:类似于removeAll()方法,从当前集合中删除不属于子集的元素,即“交集运算”。
Iterator接口方法:
|
方法 |
方法说明 |
|
void add(Object obj) |
将Obj插入列表中的一个元素前,该元素在下一次调用next()方法时被返回 |
|
boolean hasNext() |
如果存在下一个元素,则返回true,否则返回false |
|
boolean hasPrevious() |
如果存在前一个元素,则返回true,否则返回false |
|
Object next() |
返回下一个元素,如不存在,引发一个NoSuchElementException异常 |
|
int nextIndex() |
返回下一个元素的下表,如果不存在下一个元素,则返回列表的大小 |
|
Object previous() |
返回前一个元素,如不存在,引发一个NoSuchElementException异常 |
|
void remove() |
从列表中删除当前元素 |
|
void set(Object obj) |
将obj赋给当前元素。即上一次调用next()方法或previousfangfa后返回的元素 |
Collection实现类:
|
类名 |
类的说明 |
|
AbstractCollection |
实现大多数Collection接口 |
|
AbstractList |
扩展AbstractCollection并实现大多数List接口 |
|
AbstractSequentialList |
为了被类集使用而扩展AbstractList,该类集是连续而不是用随机方式访问其元素 |
|
LinkedList |
通过扩展AbstractSequentialList来实现连接表 |
|
ArrayList |
通过扩展AbstractList来实现动态数组 |
|
AbstractSet |
扩展AbstractCollection并实现大多数AbstractSet |
|
HashSet |
为了使用散列表而扩展AbstractSet |
|
TreeSet |
实现存储在树中的一个集合,扩展扩展AbstractSet |
所有通用的 Collection 实现类(通常通过它的一个子接口间接实现 Collection)应该提供两个“标准”构造方法:一个是 void(无参数)构造方法,用于创建空 collection;另一个是带有 Collection 类型单参数的构造方法,用于创建一个具有与其参数相同元素新的 collection。实际上,后者允许用户复制任何 collection,以生成所需实现类型的一个等效 collection。尽管无法强制执行此约定(因为接口不能包含构造方法),但是 Java 平台库中所有通用的 Collection 实现都遵从它。
1 package demo; 2 3 import java.util.*; 4 5 /** 6 * 集合框架的简单测试 7 * Created by luts on 2015/12/5. 8 */ 9 public class test { 10 public static void main(String[] args) throws Exception{ 11 Collection country = new HashSet(); //set是无序的、没有重复元素的集合 12 country.add("China"); 13 country.add("Canada"); 14 country.add("Italy"); 15 country.add("Japan"); 16 country.add("China"); //重复插入一个元素 17 18 System.out.println("size = " + country.size()); 19 for (Iterator it = country.iterator(); it.hasNext();) 20 System.out.println(it.next()); 21 22 System.out.println(); 23 24 Collection countryNew = new ArrayList(); //List元素有序,可以添加重复的元素 25 countryNew.add("China"); 26 countryNew.add("Canada"); 27 countryNew.add("Italy"); 28 countryNew.add("Japan"); 29 countryNew.add("China"); //重复插入一个元素 30 System.out.println("size = " + countryNew.size()); 31 for (Iterator it = countryNew.iterator(); it.hasNext();) 32 System.out.println(it.next()); 33 } 34 }
结果:
size = 4 Canada China Japan Italy size = 5 China Canada Italy Japan China
就像有专门的java.util.Arrays来处理数组,Java中对集合也有java.util.Collections来处理。
第一组方法主要返回集合的各种数据:
Collections.checkedCollection / checkedList / checkedMap / checkedSet / checkedSortedMap / checkedSortedSet:
检查要添加的元素的类型并返回结果。任何尝试添加非法类型的变量都会抛出一个ClassCastException异常。这个功能可以防止在运行的时候出错。
Collections.emptyList / emptyMap / emptySet :返回一个固定的空集合,不能添加任何元素。
Collections.singleton / singletonList / singletonMap:返回一个只有一个入口的 set/list/map 集合。
Collections.synchronizedCollection / synchronizedList / synchronizedMap / synchronizedSet / synchronizedSortedMap / synchronizedSortedSet:获得集合的线程安全版本(多线程操作时开销低但不高效,而且不支持类似put或update这样的复合操作)
Collections.unmodifiableCollection / unmodifiableList / unmodifiableMap / unmodifiableSet / unmodifiableSortedMap / unmodifiableSortedSet:返回一个不可变的集合。当一个不可变对象中包含集合的时候,可以使用此方法。
第二组方法中,其中有一些方法因为某些原因没有加入到集合中:
Collections.addAll: 添加一些元素或者一个数组的内容到集合中。
Collections.binarySearch: 和数组的Arrays.binarySearch功能相同。
Collections.disjoint: 检查两个集合是不是没有相同的元素。
Collections.fill: 用一个指定的值代替集合中的所有元素。
Collections.frequency: 集合中有多少元素是和给定元素相同的。
Collections.indexOfSubList / lastIndexOfSubList:和String.indexOf(String) / lastIndexOf(String)方法类似——找出给定的List中第一个出现或者最后一个出现的子表。
Collections.max / min: 找出基于自然顺序或者比较器排序的集合中,最大的或者最小的元素。
Collections.replaceAll: 将集合中的某一元素替换成另一个元素。
Collections.reverse: 颠倒排列元素在集合中的顺序。如果你要在排序之后使用这个方法的话,在列表排序时,最好使用Collections.reverseOrder 比较器。
Collections.rotate:根据给定的距离旋转元素。
Collections.shuffle:随机排放List集合中的节点,可以给定你自己的生成器——例如 :java.util.Random / java.util.ThreadLocalRandom or java.security.SecureRandom。
Collections.sort:将集合按照自然顺序或者给定的顺序排序。
Collections.swap:交换集合中两个元素的位置(多数开发者都是自己实现这个操作的)。
Set类似于数学中的集合的概念,是无序的、没有重复元素的集合。也就是说Set的构造函数有一个约束条件:传入的Collection参数不能包含重复的元素。常用具体实现有HashSet和TreeSet类。
Set方法:

HashSet类是对AbstractSet类的扩展。它创建了一个类集。该类集使用散列表进行存储,而散列表则通过使用称之为散列法的机制来存储信息。在散列中,一个关键字的信息内容被用来确定唯一的一个值,称为散列码。而散列码则被用来当作与关键字相连的数据的存储下标。
HashSet类的构造方法:

填充比必须介于0.0与1.0之间。它决定在散列集合向上调整大小之前,有多少能被充满。具体地说,就是当元素的个数大于散列集合容量乘以它的填充比时,散列集合会被扩大。
注意:散列集合并不能确定其元素的排列顺序。
HashSet类的主要方法:
|
方法 |
功能描述 |
|
public boolean add(Object o) |
向集合添加指定元素 |
|
public void clear() |
清空集合中所有元素 |
|
public boolean contains(Object o) |
判断集合是否包含指定元素 |
|
public boolean isEmpty() |
判断集合是否还有元素。如果集合不包含任何元素,则返回true |
|
public Iterator iterator() |
返回对此集合中元素进行迭代的迭代器 |
|
public boolean remove(Object o) |
删除集合中的元素 |
|
public int size() |
返回此集合中的元素的个数 |
|
public Object[] toArray |
将集合中的元素放到数组中,并返回该数组 |
Set.contains(E e)的时候,先调用从Object继承而来的hashCode方法,然后在调用equals()方法,连个方法都返回真的时候,才认定Set包含某个元素。jvm运行时,给每个对象分配唯一一个标志身份的标志hanshcode。Object的hashCode()方法在默认情况下,判断哈希码是不是相同.即如同equals默认情况下比较的是二者是不是同一个内存快。Set集的contains方法,内部就是先调用hashCode再调用equals()方法。很多情况要结合实际对hashCode、equals方法进行改写.
TreeSet为使用树来进行存储的Set接口提供了一个工具。对象按升序进行存储,这方便我们对其进行访问和检索。在存储了大量的需要进行快速检索的排序信息的情况下,TreeSet是一个很好的选择。
TreeSet类的构造方法:
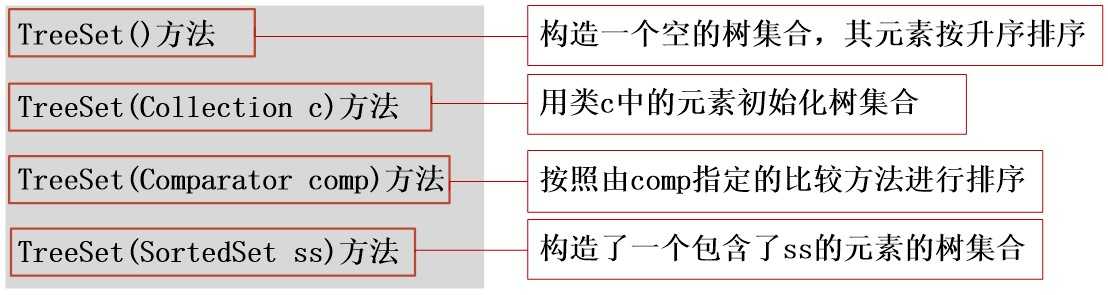
TreeSet类中有几个特殊的方法:
|
方法 |
功能描述 |
|
public E first() |
返回有序集合中第一个元素,即最小的那个元素 |
|
public E last() |
返回有序集合中最后一个元素,即最大的那个元素 |
|
public SortedSet subSet(E fromElement,E toElement) |
返回有序集合从fromElement(包括)到toElement(不包括)的元素 |
List是有序的Collection,使用此接口能够精确的控制每个元素插入的位置。能够使用索引(元素在List中的位置,类似于数组下标)来访问List中的元素,这类似于Java的数组。和Set不同,List允许有相同的元素。
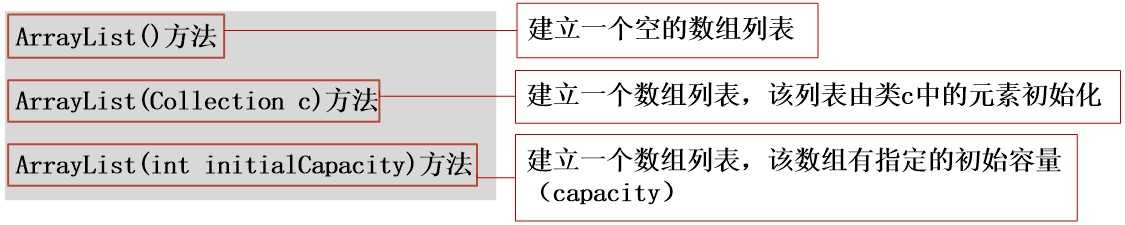
|
方法 |
功能描述 |
|
public boolean add(E o) |
将指定的元素追加到列表的最后 |
|
public void add(int index,E element) |
将参数element表示的元素插入此列表中参数index表示指定位置中 |
|
public boolean addAll(Collection c) |
将Collection中所有元素追加到此列表的尾部 |
|
public void clear() |
删除列表中的所有元素 |
|
public boolean contains(Object elem) |
判断此列表是否包含参数elem表示的指定元素 |
|
public get(int index) |
返回列表中指定位置上的元素 |
|
public boolean isEmpty() |
判断此列表中有没有元素 |
|
public remove(int index) |
删除列表中指定位置上的元素 |
|
public set(int index, E element) |
用参数element表示指定的元素代替列表中指定位置上的元素。 |
|
public int size() |
返回列表中的元素数 |
|
public Object[] toArray() |
返回一个包含列表中所有元素的数组 |
|
public T[] toArray(T[] a) |
返回一个包含列表中所有元素的数组 |
|
void trimToSize() |
将容量调整为该列表的当前大小 |
LinkedList类有两种构造方法:

除了它继承的方法之外,LinkedList类本身还定义了一些有用的方法:
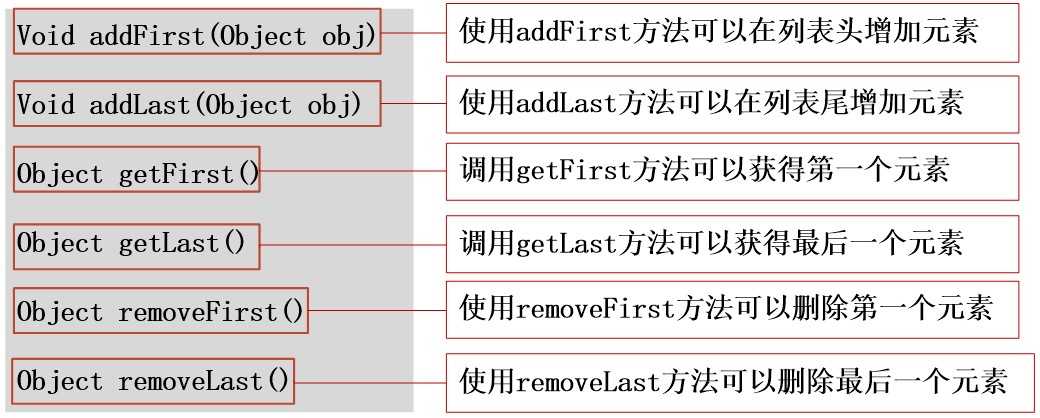
Vector类实现动态数组,这与ArrayList相似,但两者不同的是:Vector类是同步的,并且它包含了一些不属于类集框架的方法。
Vector类的构造方法:

注意:由Vector创建的Iterator,虽然和ArrayList创建的Iterator是同一接口,但是,因为Vector是同步的,当一个Iterator被创建而且正在被使用,另一个线程改变了Vector的状态(例如,添加或删除了一些元素),这时调用Iterator的方法时将抛出ConcurrentModificationException,因此必须捕获该异常。
Vetor提供了用于增加元素的方法:
|
方法 |
方法描述 |
|
public void addElement( Object obj ) |
将指定的组件添加到该向量的末尾,并将其大小增加1 |
|
public void addElement( int index,Object obj ) |
在向量的指定位置插入指定的元素obj,该位置及以后的元素位置后移 |
|
public void insertElementAt( Object obj,int index ) |
将指定对象作为此向量中的组件插入到指定的index处 |
Stack是Vector的一个子类,它实现标准的后进先出堆栈。Stack仅仅定义了创建空堆栈的默认构造方法。

Stack类包括了Vector类定义的所有方法,同时增加了几种它自己定的方法:
|
方法 |
功能描述 |
|
public E push(Object item) |
将元素引用压入栈顶 |
|
public E pop() |
删除栈顶元素。栈为空则会抛出EmptyStackException异常 |
|
public E peek() |
取得栈顶元素但不删除它。如果栈为空则会抛出EmptyStackException异常 |
|
public boolean empty() |
判断堆栈是否为空 |
|
public int search(Object o) |
返回Object对象在栈中所处的位置。其中栈顶元素位置为1,以后依次递增1。如果对象不在栈中则返回-1 |
Map没有继承Collection接口,映射(map)是一个存储关键字和值的关联,或者说是“关键字/值”对的对象,即给定一个关键字,可以得到它的值。关键字和值都是对象,关键字必须是唯一的,但值是可以被复制的。
映射接口定义了映射的特性和本质。支持映射的三大接口:

Map接口映射唯一关键字到值。关键字是以后用于检索值的对象。给定一个关键字和一个值,可以存储这个值到一个Map对象中。当这个值被存储以后,就可以使用它的关键字来检索它。Map.Entry接口使得可以操作映射的输入。而SortMap接口扩展了Map,它确保了各项关键字按升序排列。
Java转实现映射接口的类:
|
类名 |
类的描述 |
|
AbstractMap |
实现大多数的Map接口 |
|
HashMap |
将AbstractMap扩展到使用散列表 |
|
TreeMap |
将AbstractMap扩展到使用树 |
Hashtable继承Map接口,实现一个key-value映射的哈希表。任何非空(non-null)的对象都可作为key或者value。它与HashMap相似,但Hashtable是同步的。使用Hashtable时,指定一个对象作为关键字,同时指定与该关键字相关联的值。接着该关键字被散列,把得到的散列值作为存储在表中的值的下标。
Hashtable的构造方法:

添加数据使用put(key, value),取出数据使用get(key),这两个基本操作的时间开销为常数。
Hashtable通过initial capacity和load factor两个参数调整性能。通常缺省的load factor 0.75较好地实现了时间和空间的均衡。增大load factor可以节省空间但相应的查找时间将增大。
HashMap类使用散列表实现Map接口。HashMap是非同步的,并且允许null,即null value和null key。但是将HashMap视为Collection时(values()方法可返回Collection),其迭代子操作时间开销和HashMap的容量成比例。因此,如果迭代操作的性能相当重要的话,不要将HashMap的初始化容量设得过高,或者load factor过低。
HashMap类的构造方法:

HashMap类的主要方法:
|
方法 |
方法说明 |
|
public void clear() |
删除映射中所有映射关系 |
|
public boolean containsKey(Object key) |
判断HashMap中是否包指定的键的映射关系,如果包含则返回true |
|
public boolean containsValue(Object value) |
判断HashMap中是否包指定的键值的映射关系 |
|
public V get(Object key) |
返回参数key键在该映射中所映射的值 |
|
public boolean isEmpty() |
判断HashMap中是否包含键-值映射关系,如果不包含则返回true |
|
public V put(K key, V value) |
在映射中放入指定值与指定键 |
|
public void putAll(Map m) |
将指定映射的所有映射关系复制到此映射中 |
|
public int size() |
返回映射中键-值映射关系的数目 |
|
public V remove(Object key) |
删除映射中存在该键的映射关系 |

|
方法 |
方法说明 |
|
clear() |
从此TreeMap中删除所有映射关系 |
|
clone() |
返回TreeMap实例的浅表复制 |
|
comparator() |
返回用于对此映射进行排序的比较器,如果此映射使用它的键的自然顺序,则返回null |
|
containsKey(Objectkey) |
如果此映射包含对于指定的键的映射关系,则返回true |
|
containsValue(Objectvalue) |
如果此映射把一个或多个键映射到指定值,则返回true |
|
entrySet() |
返回此映射所包含的映射关系的set视图 |
|
firstKey() |
返回有序映射中当前第一个键 |
|
get(Objectkey) |
返回此映射中映射到指定键的值 |
|
headMap(KtoKey) |
返回此映射的部分视图,其键严格小于toKey |
|
keySet() |
返回此映射中所包含的键的Set视图 |
|
lastKey() |
返回有序映射中当前最后一个键 |
来自慕课网的例子:Course课程类:
1 /** 2 * Created by Luts on 2015/12/5. 3 */ 4 public class Course { 5 private String id; 6 private String name; 7 public Course(String id, String name){ 8 this.id = id; 9 this.name = name; 10 } 11 12 public Course(){} 13 14 public String getId() { 15 return id; 16 } 17 18 public void setId(String id) { 19 this.id = id; 20 } 21 22 public String getName() { 23 return name; 24 } 25 26 public void setName(String name) { 27 this.name = name; 28 } 29 }
学生类:
1 import java.util.*; 2 3 /** 4 * Created by Luts on 2015/12/5. 5 */ 6 public class Student { 7 private String id; 8 private String name; 9 private Set<Course> courses; 10 11 public Student(String id, String name){ 12 this.id = id; 13 this.name = name; 14 this.courses = new HashSet<Course>(); 15 } 16 17 public String getId() { 18 return id; 19 } 20 21 public void setId(String id) { 22 this.id = id; 23 } 24 25 public String getName() { 26 return name; 27 } 28 29 public void setName(String name) { 30 this.name = name; 31 } 32 33 public Set<Course> getCourses() { 34 return courses; 35 } 36 37 public void setCourses(Set<Course> courses) { 38 this.courses = courses; 39 } 40 41 }
测试类:
1 import javax.swing.text.html.parser.Entity; 2 import java.util.HashMap; 3 import java.util.Map; 4 import java.util.Scanner; 5 import java.util.Set; 6 import java.util.Map.*; 7 8 /** 9 * Created by Luts on 2015/12/5. 10 */ 11 public class MapTest { 12 13 //创建Map的学生类型 14 public Map<String, Student> students; 15 16 //初始化学生类型 17 public MapTest(){ 18 this.students = new HashMap<String, Student>(); 19 } 20 21 22 public void testPut(){ 23 Scanner input = new Scanner(System.in); 24 int i = 0; 25 while (i < 3){ 26 System.out.println("输入学生ID"); 27 String ID = input.next(); 28 Student st = students.get(ID); 29 if (st == null){ 30 System.out.println("输入学生姓名"); 31 String name = input.next(); 32 Student newStudent = new Student(ID, name); 33 students.put(ID, newStudent); 34 System.out.println("新添加学生:" + students.get(ID).getName()); 35 i++; 36 }else { 37 System.out.println("该学生ID已被占用"); 38 continue; 39 } 40 } 41 } 42 43 public void testKeySet(){ 44 Set<String> keySet = students.keySet(); //通过keySet方法返回Map值所有“键”的set集合 45 46 //取得students容量 47 System.out.println("总共有:"+students.size() +"个学生"); 48 49 //遍历keySet,取得键对应的值 50 for (String stuID : keySet){ 51 Student st = students.get(stuID); 52 if (st != null){ 53 System.out.println("学生:" + st.getName()); 54 } 55 } 56 57 } 58 59 60 public void testRemove(){ 61 Scanner input = new Scanner(System.in); 62 while (true){ 63 System.out.println("输入要删除的学生ID"); 64 String ID = input.next(); 65 Student st = students.get(ID); 66 if (st == null){ 67 System.out.println("该学生ID不存在"); 68 continue; 69 } 70 System.out.println("成功删除学生:" + students.get(ID).getName()); 71 break; 72 } 73 } 74 75 //通过entrySet方法遍历Maop 76 public void testEntrySet(){ 77 Set<Entry<String, Student>>entrySet = students.entrySet(); 78 for (Entry<String, Student>entry : entrySet){ 79 System.out.println("取得键:" + entry.getKey()); 80 System.out.println("对应的值为:" + entry.getValue().getName()); 81 } 82 } 83 84 public void testModify() { 85 // 提示输入要修改的学生ID 86 System.out.println("请输入要修改的学生ID:"); 87 // 创建一个Scanner对象,去获取从键盘上输入的学生ID字符串 88 Scanner input = new Scanner(System.in); 89 while (true) { 90 // 取得从键盘输入的学生ID 91 String stuID = input.next(); 92 // 从students中查找该学生ID对应的学生对象 93 Student student = students.get(stuID); 94 if (student == null) { 95 System.out.println("该ID不存在!请重新输入!"); 96 continue; 97 } 98 // 提示当前对应的学生对象的姓名 99 System.out.println("当前该学生ID,所对应的学生为:" + student.getName()); 100 // 提示输入新的学生姓名,来修改已有的映射 101 System.out.println("请输入新的学生姓名:"); 102 String name = input.next(); 103 Student newStudent = new Student(stuID, name); 104 students.put(stuID, newStudent); 105 System.out.println("修改成功!"); 106 break; 107 } 108 } 109 110 111 112 public static void main(String[] args){ 113 MapTest mt = new MapTest(); 114 mt.testPut(); 115 mt.testKeySet(); 116 mt.testRemove(); 117 //mt.testEntrySet(); 118 // mt.testModify(); 119 // mt.testEntrySet(); 120 121 } 122 }
TreeSet和TreeMap都按排序顺序存储元素。然而,精确定义到底采用哪种“排序顺序”则是比较方法。在默认情况下,Java采用的是“自然排序”的顺序存储它们的元素,例如A在B的前面,2在3的前面,等等。如果需要用到其他的方法对元素进行排序,可以在构造集合或者映射时,指定一个Comparator对象。
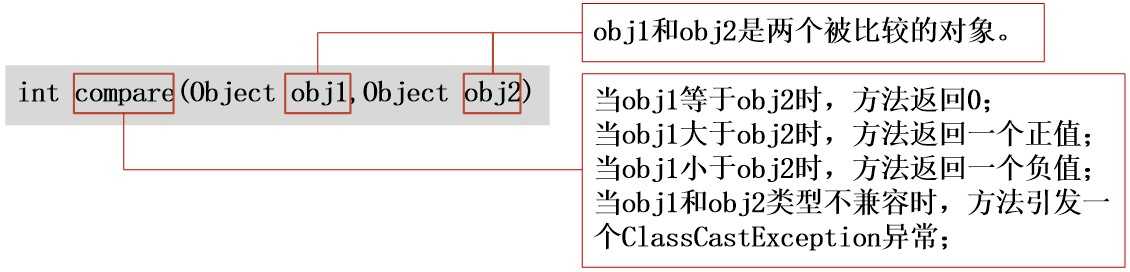
Comparator接口定义了两种方法:compare()和equals()。
compare()方法:

此接口强行对实现它的每个类的对象进行整体排序。此排序被称为该类的自然排序 ,类的 compareTo 方法被称为它的自然比较方法 。实现此接口的对象列表(和数组)可以通过 Collections.sort (和 Arrays.sort )进行自动排序。
int compareTo(T obj) 比较此对象与指定对象的顺序。如果该对象小于、等于或大于指定对象,则分别返回负整数、零或正整数。
Comparator位于包java.util下,而Comparable位于包java.lang下,Comparable接口将比较代码嵌入自身类中,而后者在一个独立的类中实现比较。 如果类的设计师没有考虑到Compare的问题而没有实现Comparable接口,可以通过 Comparator来实现比较算法进行排序,并且为了使用不同的排序标准做准备,比如:升序、降序。
关于比较器,更多参阅:http://blog.csdn.net/cz1029648683/article/details/6666855
|
接口
|
实现类
|
保持插入顺序
|
可重复
|
排序
|
使用说明
|
|
List
|
ArrayList
|
Y
|
Y
|
N
|
长于随机访问元素;但插入、删除元素较慢(数组特性)。
|
|
LinkedList
|
Y
|
Y
|
N
|
插入、删除元素较快,但随即访问较慢(链表特性)。
|
|
|
Set
|
HashSet
|
N
|
N
|
N
|
使用散列,最快的获取元素方法。
|
|
TreeSet
|
N
|
N
|
Y
|
将元素存储在红-黑树数据结构中。默认为升序。
|
|
|
LinkedHashSet
|
Y
|
N
|
N
|
使用散列,同时使用链表来维护元素的插入顺序。
|
|
|
Map
|
HashMap
|
N
|
N
|
N
|
使用散列,提供最快的查找技术。
|
|
TreeMap
|
N
|
N
|
Y
|
默认按照比较结果的升序保存键。
|
|
|
LinkedHashMap
|
Y
|
N
|
N
|
按照插入顺序保存键,同时使用散列提高查找速度。
|
标签:
原文地址:http://www.cnblogs.com/luts/p/5020474.html