标签:
Array & String
大纲
1. 入门题 string match
2. Array 中 HashTable 的应用
3. C/C++ 中的 string
4. 例题分析
part 1 入门题
在 source(母串)中,寻找 target(子串) 是否出现。
/* Returns the position of the first occurrence of string target in string source, or -1 if target is not part of source.*/ int strStr(String source, String target) { //… }
字符串匹配
两种比较易于实现的字符串比较算法:
假设在长度为 n 的母串中匹配长度为 m 的子串。(http://en.wikipedia.org/wiki/String_searching_algorithm)。
1. Brute-Force 算法: 顺序遍历母串,将每个字符作为匹配的起始字符,判断是否匹配子串。时间复杂度 O(m*n)
char* strStr(const char *str, const char *target) { if(!*target) return str; char *p1 = (char*)str; while(*p1) { char *p1Begin = p1, *p2 = (char*)target; while(*p1 && *p2 && *p1 == *p2) { p1++; p2++; } if(!*p2) return p1Begin; p1 = p1Begin + 1; } return NULL; }
2.Rabin-Karp 算法 :将每一个匹配子串映射为一个hash值。例如,将子串看做一个多进制数,比较它的值与母串中相同长度子串的hash值,如果相同,再细致地按字符确认字符串是否确实相同。顺序计算母串hash值的过程中,使用增量计算的方法:扣除最高位的hash值,增加最低位的hash值。因此能在平均情况下做到O(m+n)。
#include <string> #include <iostream> #include <functional> using namespace std; size_t Rabin_karp_StrStr(string &source, string &target) { hash<string> strHash; size_t targetHash = strHash(target); for (size_t i = 0; i < source.size() - target.size() + 1; i++) { string subSource = source.substr(i, target.size()); if (strHash(subSource) == targetHash) { if (subSource == target) return i; } } return 0; } int main() { string s1 = "abcd"; string s2 = "cd"; cout << Rabin_karp_StrStr(s1, s2); return 0; }
part 2 Array
int array[arraySize]; //在Stack上定义长度为arraySize的整型数组 int *array = new int[arraySize]; //在Heap上定义长度为arraySize的整型数组 delete[] array; //使用完后需要释放内存:
注意,在旧的编译器中,不能在Stack上定义一个长度不确定的数组,即只能定义如下:
int array[10];
新的编译器没有如上限制。但是如果数组长度不定,则不能初始化数组:
int array[arraySize] = {0}; //把不定长度的数组初始化为零,编译报错。
part 3 工具箱:Stack Vs. Heap
Stack主要是指由操作系统自动管理的内存空间。当进入一个函数,操作系统会为该函数中的局部变量分配储存空间。事实上,系统会分配一个内存块,叠加在当前的stack上,并且利用指针指向前一个内存块的地址。
函数的局部变量就存储在当前的内存块上。当该函数返回时,系统“弹出”内存块,并且根据指针回到前一个内存块。所以,Stack总是以后进先出(LIFO)的方式工作
Heap是用来储存动态分配变量的空间。对于heap而言,并没有像stack那样后进先出的规则,程序员可以选择随时分配或回收内存。这就意味着需要程序员自己用命令回收内存,否则会产生内存泄露(memory leak)。
在C/C++中,程序员需要调用free/delete来释放动态分配的内存。在JAVA,Objective-C (with Automatic Reference Count)中,语言本身引入垃圾回收和计数规则帮助用户决定在什么时候自动释放内存。
part 4 二维数组
//在Stack上创建: int array[M][N]; //传递给子函数: void func(int arr[M][N]) { /* M可以省略,但N必须存在,以便编译器确定移动内存的间距 */ } //在Heap上创建: int **array = new int*[M]; // 或者 (int**)malloc( M * sizeof(int*) ); for( int i = 0; i < M; i++) array [i] = new int[N]; // 或者 (int*)malloc( N * sizeof(int) ); //传递给子函数: void func( int **arr, int M, int N ){} //使用完后需要释放内存: for( int i = 0; i < M; i++) delete[] array[i]; delete[] array;
part 5 工具箱:Vector
vector可以用运算符[]直接访问元素。请参考http://www.cplusplus.com/reference/vector/vector/
size_type size() const; // Returns the number of elements in the vector. void push_back (const value_type& val); void pop_back(); iterator erase (iterator first, iterator last); // Removes from the vector either a singleelement (position) or a range of elements ([first,last)). for (vector<int>::iterator it = v.begin(); it != v.end(); ) { if (condition) { it = v.erase(it); } else { ++it; } }
part 6 Hash Table
Hash table 几乎是最为重要的数据结构,主要用于基于“key”的查找,存储的基本元素是 key-value 的 pair。逻辑上,数组可以作为 Hash table 的一个特例:key是一个非负整数。
Operations
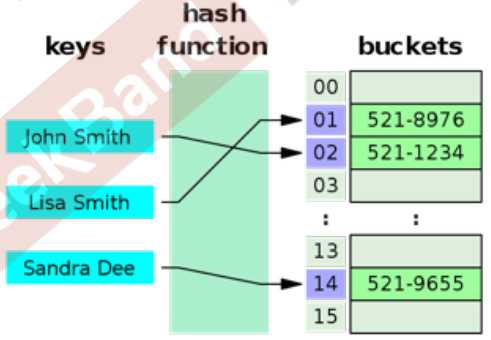
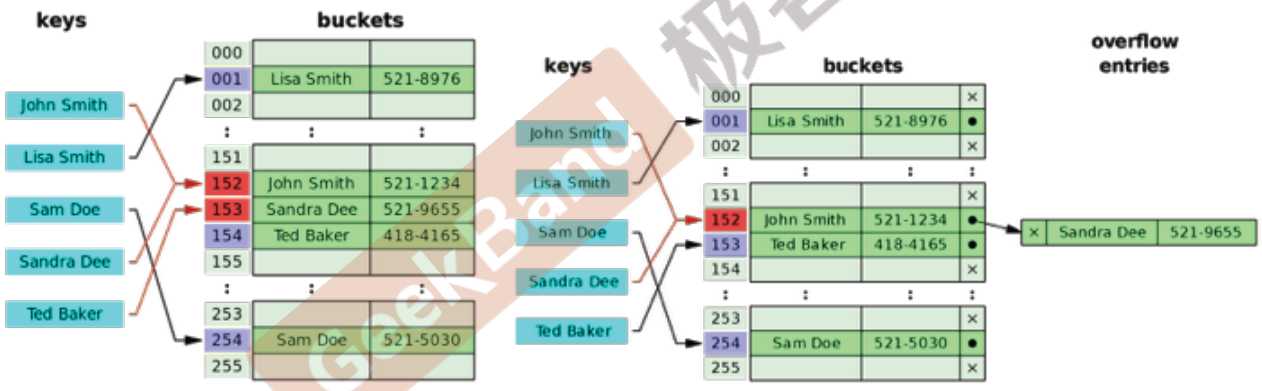
哈希碰撞 - Open Hashing(再哈希法) vs Closed Hashing(链地址法)
part 7 C++标准库
提供map容器,可以插入,删除,查找key-value pair,底层以平衡二叉搜索树的方式实现,根据key进行了排序。
在C++11中,标准库添加了unordered_map,更符合Hash table的传统定义,平均查找时间O(1)
part 8 String
在C语言中,字符串指的是一个以’\0’结尾的char数组。关于字符串的函数通常需要传入一个字符型指针。
在C++中,String是一个类,并且可以通过调用类函数实现判断字符串长度,子串等等操作。
part 9 工具箱:C语言中String常用函数
char *strcpy ( char *destination, const char *source ); //copy source string to destination string char *strcat ( char *destination, const char *source ); //Appends a copy of the source string to the destination string. int strcmp ( const char *str1, const char *str2 ); char *strstr (char *str1, const char *str2 ); // Returns a pointer to the first occurrence of str2 in str1, or a NULL pointer if str2 is not part of str1. size_t strlen ( const char *str ); // Returns the length of the C string str. double atof (const char *str); // convert char string to a double int atoi (const char *str); // convert char string to an int
part 10 工具箱:C++中String类常用函数
String类重载了+, <, >, =, ==等运算符,故复制、比较、判断是否相等,附加子串等都可以用运算符直接实现。请参考( http://www.cplusplus.com/reference/string/string/)
size_t find (const string& str, size_t pos = 0) const; // Searches the string for the first occurrence of the str, returns index string substr (size_t pos = 0, size_t len = npos) const; // Returns a newly constructed string object with its value initialized to a copy of a substring starting at pos with length len. string &erase (size_t pos = 0, size_t len = npos); // erase characters from pos with length len size_t length(); // Returns the length of the string, in terms of bytes
模式识别
当遇到某些题目需要统计一个元素集中元素出现的次数,应该直觉反应使用 Hash Table,即使用 std::unordered_map 或 std::map:key 是元素,value 是出现的次数。特别地,有一些题目仅仅需要判断元素出现与否(相当于判断 value 是0还是1),可以用 bitvector,即 bitset,利用一个bit来表示当前的下标是否有值。
标签:
原文地址:http://www.cnblogs.com/fengyubo/p/5027583.html