标签:
摘要 在不同平台通信的时候,首先需要将对象进行序列化。iOS平台上我们常用`NSKeyedArchiver`进行归档,当然也可以将数据处理为JSON或者XML格式。`NSKeyedArchiver`只能在iOS/Mac平台使用,因此它归档的二进制数据不适合于在不同平台之间使用。JSON和XML虽然由于容易维护,易读而应用比较广泛,但是对数据的利用效率都不是高。Google提出了 Protocol Buffers作为一种跨平台、语言无关的序列化数据格式。Protocol Buffers提供代码生成工具,能够根据定义好的数据格式生成不同语言的代码,然后集成到项目中使用。Protocol Buffe...
目录[-]
在不同平台通信的时候,首先需要将对象进行序列化。iOS平台上我们常用NSKeyedArchiver进行归档,当然也可以将数据处理为JSON或者XML格式。NSKeyedArchiver只能在iOS/Mac平台使用,因此它归档的二进制数据不适合于在不同平台之间使用。JSON和XML虽然由于容易维护,易读而应用比较广泛,但是对数据的利用效率都不是高。Google提出了 Protocol Buffers 作为一种跨平台、语言无关的序列化数据格式。Protocol Buffers提供代码生成工具,能够根据定义好的数据格式生成不同语言的代码,然后集成到项目中使用。Protocol Buffers目前有两种格式:proto2和proto3。Protocol Buffers支持Java、Python、C++、Objective-C等代码的生成。
编译Protocol Buffers。虽然我们是可以直接将它的代码或者项目引入Xcode中,但是还是需要编译重要的代码生成工具(protoc)。由于Protocol Buffers编译时使用了autoconf/automake/libtool等UNIX工具,Mac可能没有自带,需要手动安装。我们可以使用HomeBrew或者MacPort进行安装(二选一就行)。
$ brew install autoconf
$ brew install automake
$ brew install libtool
$ sudo port install autoconf automake libtool
README.md中说可以直接用./configure进行配置并编译运行了,但实际还差一步,就是运行./autogen.sh脚本,否则会发生错误。然而遗憾的是,autogen.sh中会下载https://googlemock.googlecode.com/files/gmock-1.7.0.zip。gmock处于 墙外 ,只能用梯子出去取(没梯子的可以找 戴维营教育 交流群免费索取,会不会被请喝茶啊)。
没有运行autogen.sh的场景:
$ ./configure --with-protoc=protoc
$ ./configure: line 2215: syntax error near unexpected token ‘enable‘
$ ./configure: line 2215: ‘AM_MAINTAINER_MODE(enable)‘
一旦打开VPN了,运行下面的脚本:
$ ./autogen.sh
$ ./configure
$ make
# 如果希望安装protoc,执行下面的命令
$ make install
syntax = "proto3";
message Person {
string name = 1;
int32 uid = 2;
string email = 3;
enum PhoneType {
MOBILE = 0;
HOME = 1;
WORK = 2;
}
message PhoneNumber {
string number = 1;
PhoneType type = 2;
}
repeated PhoneNumber phone = 4;
}
--proto_path=后跟需要处理的proto文件所在的文件夹,--objc_out=指明生成的是Objective-C代码以及目标文件存放路径,最后是需要处理的文件。$ protoc --proto_path=. --objc_out=. Person.proto
$ ls
Person.pbobjc.h Person.pbobjc.m Person.proto
处理完成后,生成两个文件,分别是 Person.pbobjc.h 和 Person.pbobjc.m 。这两个文件是采用的手动引用计数,因此在加入项目后需要设置它们的编译参数。

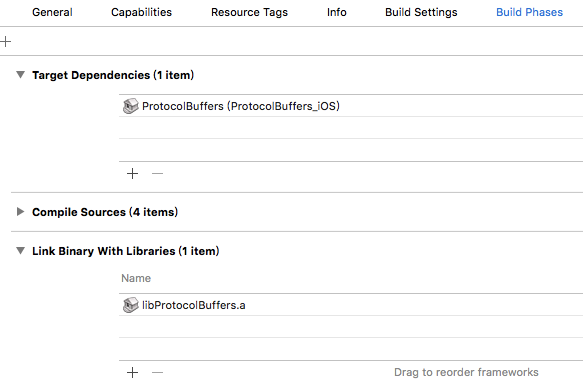
设置依赖和连接库。
#import "GPBProtocolBuffers.h"
#import "Person.pbobjc.h"
- (void)viewDidLoad {
[super viewDidLoad];
Person *person = [[Person alloc] init];
person.name = @"Zhangsan";
person.email = @"diveinedu@qq.com";
person.uid = 23;
NSData *data = [person data];
NSString *path = @"/Users/apple/Desktop/test.data";
[data writeToFile:path atomically:YES];
NSData *ldata = [NSData dataWithContentsOfFile:path];
Person *p = [Person parseFromData:ldata error:nil];
NSLog(@"\nname:%@\nemail:%@\nuid:%d", p.name, p.email, p.uid);
}
打印结果如下:
2015-12-02 13:09:46.890 ProtobufDemo[34761:150533]
name:Zhangsan
email:diveinedu@qq.com
uid:23
name: Zhangsan
email: diveinedu@qq.com
uid: 23
采用Protocol Buffers的数据大小为30个字节。而实用JSON存储时,尽管我们将Key变成一个字节,如下:
NSDictionary *dict = @{@"n":@"Zhangsan",
@"e":@"diveinedu@qq.com",
@"u":@23};
NSData *jd = [NSJSONSerialization dataWithJSONObject:dict options:0 error:nil];
NSLog(@"jd: %lu", jd.length);
JSON数据还是占了46个字节,并且随着可读性提高,效率更低。XML就更不用说了。
如果希望获得更好的的可读性,可以选用JSON和XML这类文本格式。但如果从数据效率上将,Protocol Buffer是一个不错的选择。存储效率高,并且proto文件的可读性和可维护性都比较强。
标签:
原文地址:http://www.cnblogs.com/diveinclub/p/5030764.html