标签:
一 、该模块包含用以 URL 解析的实用函数。 使用 require(‘url‘) 来调用该模块。
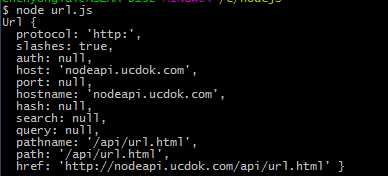
1、不同的 URL 字符串解析后返回的对象会有一些额外的字段信息,仅当该部分出现在 URL 中才会有。以下是一个 URL 例子:
‘http://nodeapi.ucdok.com/api/url.html‘
2、
true 则使用 querystring 模块来解析 URL 中德查询字符串部分,默认为 false。将第三个参数设置为 true 来把诸如 //foo/bar 这样的URL解析为 { host: ‘foo‘, pathname: ‘/bar‘ } 而不是 { pathname: ‘//foo/bar‘ }。 默认为 false。
二、
href 属性会被忽略处理.protocol无论是否有末尾的 : (冒号),会同样的处理
http, https, ftp, gopher, file 后缀是 :// (冒号-斜杠-斜杠).mailto, xmpp, aim, sftp, foo, 等 会加上后缀 : (冒号)auth 如果有将会出现.hostname 如果 host 属性没被定义,则会使用此属性.port 如果 host 属性没被定义,则会使用此属性.host 优先使用,将会替代 hostname 和portpathname 将会同样处理无论结尾是否有/ (斜杠)search 将会替代 query属性query (object类型; 详细请看 querystring) 如果没有 search,将会使用此属性.search 无论前面是否有 ? (问号),都会同样的处理hash无论前面是否有# (井号, 锚点),都会同样处理url.resolve(‘/one/two/three‘, ‘four‘) // ‘/one/two/four‘
url.resolve(‘http://example.com/‘, ‘/one‘) // ‘http://example.com/one‘
url.resolve(‘http://example.com/one‘, ‘/two‘) // ‘http://example.com/two‘
标签:
原文地址:http://www.cnblogs.com/cylblogs/p/5031935.html