标签:python 模块 sys os time re shutil
常用模块
sys
sys.argv 命令行参数列表,第一个元素是程序本身路径
sys.exit(n) 退出程序,正常退出时exit(0)
sys.version
sys.maxint 最大的int值
sys.path 返回模块的搜索路径
sys.paltform
sys.stdout.wirte(“hello”)
val = sys.stdin.readline()[:-1]
logging
import logging
logging.basicConfig(filename=‘log.log‘,
format=‘%(asctime)s - %(name)s - %(levelname)s -%(module)s:%(message)s‘,
datefmt=‘%Y-%m-%d %H:%M:%S %p‘,
level=10)
logging.debug(‘debug‘)
logging.info(‘info‘)
logging.warning(‘warning‘)
logging.error(‘error‘)
logging.critical(‘critical‘)
logging.log(10,‘log‘)
对于等级,只有大于当前日志等级的操作才会被记录
CRITICAL = 50
FATAL = CRITICAL
ERROR = 40
WARNING = 30
WARN = WARNING
INFO = 20
DEBUG = 10
NOTSET = 0
json 和pickle
json,用于字符串和python数据类型间进行转换
pickle,用于python特有的类型和python的数据类型间进行转换
dumps,dump,loads,load
data = dict(k1=123,k2=’hello’)
json.dumps(data) --- ‘{"k2": "hello", "k1": 123}‘
type(json.dumps(data) ---<type ‘str‘>
json.dumps(data) 将数据通过形式转换为所有程序语言都认识的字符串
json.dump(data,fp) fp为文件句柄,可以直接将data转换并写入文件
json.loads() 是将字符串转为python的数据类型,如将文件中的格式化的内容转为python的类型
json.loads(fp.read()) 或者 json.load(fp) --loads()的参数是字符串,而load是文件句柄
json.dumps 提供了很多好用的参数,常用的有sort_keys separators, indent
json.dumps(data,sort_keys=True)
json.dumps(data,indent=4) 带缩进,数据存储时比较好看
json.dumps(data,separator=(‘,’,’:’)) separators传进来的元组参数指明了data元素的分隔符,If ``separators`` is an ``(item_separator, dict_separator)`` tuple,then it will be used instead of the default ``(‘, ‘, ‘: ‘)`` separators. ``(‘,‘, ‘:‘)`` is the most compact JSON representation.separators必须为元组类型
--如果data为列表,json.dumps(data,separators=(‘’,’’)) 会将列表的元素合并为一个
subprocess执行系统命令
subprocess.call 执行命令,返回状态码,0为正确,1为有误
ret = subprocess.call([“ls”,”-l”]) --windows下需要加上shell=True
ret = subprocess.call(“ls –l”,shell =True) shell = True,允许shell命令是字符串形式,不建议使用字符串形式,有安全隐患
subprocess.check_call执行命令,如果状态码是0则返回0,否则抛异常
subprocess.check_output 执行命令,如果状态码是0则返回执行结果,否则抛异常
subprocess.popen() 生成一个子进程来执行命令或其它程序
参数:
args:shell命令,可以是字符串或者序列类型(如:list,元组)
bufsize:指定缓冲。0 无缓冲,1 行缓冲,其他缓冲区大小,负值系统缓冲
stdin, stdout, stderr:分别表示子进程的标准输入、输出、错误句柄
preexec_fn:只在Unix平台下有效,用于指定一个可执行对象(callable object),它将 在子进程运行之前被调用
close_sfs:在windows平台下,如果close_fds被设置为True,则新创建的子进程将不 会继承父进程的输入、输出、错误管道。所以不能将close_fds设置为True同时重定向 子进程的标准输入、输出与错误(stdin, stdout, stderr)。
shell:同上
cwd:用于设置子进程的当前目录
env:用于指定子进程的环境变量。如果env = None,子进程的环境变量将从父进程中 继承。
universal_newlines:不同系统的换行符不同,True -> 同意使用 \n
startupinfo与createionflags只在windows下有效,将被传递给底层的CreateProcess()函 数,用于设置子进程的一些属性,如:主窗口的外观,进程的优先级等等
communicate(input = None) 与进程交互,发送数据到stdin。从stdout和stderr中读取数据,直到结束。等待进程结束。可选的input是发送到了进程的字符串,如果没有数据发送给子进程,则input为空。它返回元组(stdout,stderr)
kill() 用sigkill杀掉进程
poll()
terminamte() 用sigterm中断进程
wait() 等待子进程中断,返回returncode
import subprocess
obj = subprocess.Popen([‘ls’,’-l‘])
–生成一个子进程执行ls –l, 此时obj是Popen的一个对象
print obj --<subprocess.Popen object at 0x139f990>
obj.pid --5634 这个子进程的pid,此时进程还存在,只有执行了其它的subprocess 的命令,这个子进程才会结束
stdin, stdout, stderr:分别表示子进程的标准输入、输出、错误句柄,可以利用PIPE 将它们连接在一起,构成管道
obj = subprocess.Popen([‘python’],stdin=subprocess.PIPE,
stdout=subprocess.PIPE,
stderr=subprocess.PIPE)
obj.stdin.write(‘print 1\n’)
obj.stdin.close()
print obj.stdout.read()
obj.stdout.close()
生成一个python进程,输入输出和出错都写到管道里,其实也是文件,当stdin.write 只是写入,并没有执行,只有当stdin.close()的时候,才执行,然后stdout.read()
才能读出来(stdin stdout stderr分别为三个文件)
利用 communicate可以简化这个过程
obj = subprocess.Popen([‘python’],stdin=subprocess.PIPE,
stdout=subprocess.PIPE,
stderr=subprocess.PIPE)
out_error_list = obj.communicate(‘print 1\n’)
print out_error_list
也可以利用管道将多个子进程的输入输出连接在一起
import subprocess
child1 = subprocess.Popen(["cat","/etc/passwd"], stdout=subprocess.PIPE)
child2 = subprocess.Popen(["grep","0:0"],stdin=child1.stdout, stdout=subprocess.PIPE)
out = child2.communicate()
print out
stdout=open(‘/dev/null’,’w’) stderr = subprocess.stdout 会将错误输出和正常输出到/dev/null(黑洞),就是不要输出
正则表达式
字符:
. 匹配除换行符以外的任意字符
\w 匹配字母或数字或下划线或汉字
\s 匹配任意的空白字符
\d 匹配数字
\b 匹配单词的开始或结束
^ 匹配字符串的开始
$ 匹配字符串的结束
次数:
* 重复零次或多次
+ 重得一次或多次
? 重复零次或一次
{n} 重复N次
{n,} 重复N次或更多
{n,m} 重复N到M次
re.match(pattern,string,flag=0)
从起始位置开始匹配,匹配单个
>>> re.match(‘\d+‘,‘12uu456‘).group()
‘12‘
>>> re.match(‘\d+‘,‘uu456‘).group()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: ‘NoneType‘ object has no attribute ‘group‘
re.search(pattern,string,flags=0)
根据匹配规则去字符串中匹配,匹配单个
>>> re.search(‘\d+‘,‘12uu456‘).group()
‘12‘
>>> re.search(‘\d+‘,‘uu456‘).group()
‘456‘
group 与 groups
>>> a = "123abc456hello"
>>> print re.search("([0-9]*)([a-z]*)([0-9]*)", a).group()
123abc456
>>> print re.search("([0-9]*)([a-z]*)([0-9]*)", a).group(0)
123abc456
>>> print re.search("([0-9]*)([a-z]*)([0-9]*)", a).group(1)
123
>>> print re.search("([0-9]*)([a-z]*)([0-9]*)", a).group(2)
abc
>>> print re.search("([0-9]*)([a-z]*)([0-9]*)", a).group(3)
456
>>> print re.search("([0-9]*)([a-z]*)([0-9]*)", a).groups()
(‘123‘, ‘abc‘, ‘456‘)
>>> print re.search("([0-9]*)([a-z]*)([0-9]*)", a).group(0,1,2,3,)
(‘123abc456‘, ‘123‘, ‘abc‘, ‘456‘)
这里的匹配规则是由三部分组成,找到的结果也会生成一个group元组, group(1) group(2) group(3)是满足这三部分条件的值
re.findall
re.findall(pattern,string,flags=0)
找到字符串中所有匹配规则的元素,返回列表
>>> a
‘123abc456hello‘
>>> print re.findall(‘\d+‘,a)
[‘123‘, ‘456‘]
>>> print re.findall(‘\d‘,a)
[‘1‘, ‘2‘, ‘3‘, ‘4‘, ‘5‘, ‘6‘]
>>> print re.findall(‘[a-z]+‘,a)
[‘abc‘, ‘hello‘]
>>> print re.findall(‘[a-z]+\d*‘,a)
[‘abc456‘, ‘hello‘]
re.split(pattern,string,maxsplit=0,flags=0)
根据匹配规则进行分组
>>> content = ‘1-2 *((60-30+1*(9-2*5/3+7/3*99/4*2998+10*568/14))-(-4*3)/(16-3*2) )‘
>>> re.split(‘\*‘, content)
[‘1 - 2 ‘, ‘ ((60-30+1‘, ‘(9-2‘, ‘5/3+7/3‘, ‘99/4‘, ‘2998+10‘, ‘568/14))-(-4‘, ‘3)/(16-3‘, ‘2) )‘]
>>> re.split(‘\*‘, content,1)
[‘1 - 2 ‘, ‘ ((60-30+1*(9-2*5/3+7/3*99/4*2998+10*568/14))-(-4*3)/(16-3*2) )‘]
>>> re.split(‘\*‘, content,2)
[‘1 - 2 ‘, ‘ ((60-30+1‘, ‘(9-2*5/3+7/3*99/4*2998+10*568/14))-(-4*3)/(16-3*2) )‘]
maxsplit默认为0时,全部分割;为1时,只分割一次,为2时,分割2次…
re.sub(pattern,repl,string,count=0,flags=0)
>>> a = ‘123abc456edg789hij‘
>>> re.sub(‘\d+‘,‘x‘,a)
‘xabcxedgxhij‘
>>> re.sub(‘\d+‘,‘x‘,a,count=1)
‘xabc456edg789hij‘
>>> re.sub(‘\d+‘,‘x‘,a,count=2)
‘xabcxedg789hij‘
time
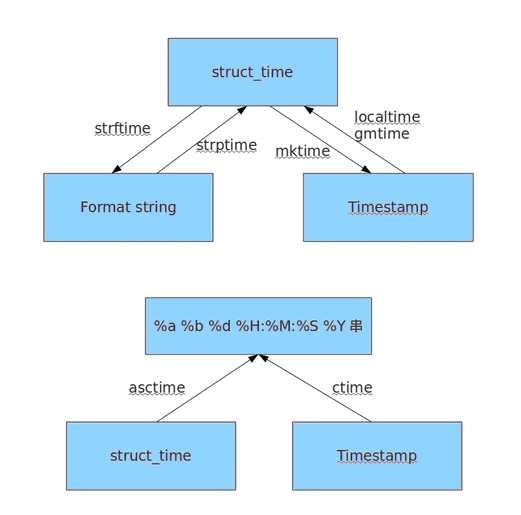
时间戳 time.time()
格式化的字符串 strftime(‘%Y-%m-%d’)
结构化时间 tme.localtime() 包含了年月日小时分钟秒星期一年中的第几天是否是夏令时
时间戳
print time.time()
print time.mktime(time.localtime())
格式化时间
print time.gmtime() #可加时间戳参数 世界标准时间
print time.localtime() #可加时间戳参数 本地时区时间
print time.strptime(‘2014-11-11‘, ‘%Y-%m-%d‘)
字符串
print time.strftime(‘%Y-%m-%d‘) #默认当前时间
print time.strftime(‘%Y-%m-%d‘,time.localtime()) #默认当前时间
print time.asctime() 转换时间元组成字符串,默认为time.localtime, 转换后的格式与ctime的一样
print time.asctime(time.localtime())
print time.ctime(time.time()) 转换时间戳成字符串,转换后的格式为
>>> time.ctime(time.time())
‘Wed Dec 9 01:57:24 2015‘
时间戳转为格式化字符串
>>> time.strftime(‘%Y-%m-%d %H:%M:%S‘,time.localtime(time.time()))
‘2015-12-09 01:45:27
格式化字符串转时间戳
>>> time.mktime(time.strptime(‘2015-10-10‘,‘%Y-%m-%d‘))
1444406400.0
strftime的格式字符意义
%a星期的简写。如星期三为Web
%A星期的全写。如星期三为Wednesday
%b月份的简写。如4月份为Apr
%B月份的全写。如4月份为April
%c: 日期时间的字符串表示。(如: 04/07/10 10:43:39)
%d: 日在这个月中的天数(是这个月的第几天)
%f: 微秒(范围[0,999999])
%H: 小时(24小时制,[0, 23])
%I: 小时(12小时制,[0, 11])
%j: 日在年中的天数 [001,366](是当年的第几天)
%m: 月份([01,12])
%M: 分钟([00,59])
%p: AM或者PM
%S: 秒(范围为[00,61],为什么不是[00, 59],参考python手册~_~)
%U: 周在当年的周数当年的第几周),星期天作为周的第一天
%w: 今天在这周的天数,范围为[0, 6],6表示星期天
%W: 周在当年的周数(是当年的第几周),星期一作为周的第一天
%x: 日期字符串(如:04/07/10)
%X: 时间字符串(如:10:43:39)
%y: 2个数字表示的年份
%Y: 4个数字表示的年份
%z: 与utc时间的间隔(如果是本地时间,返回空字符串)
%Z: 时区名称(如果是本地时间,返回空字符串)
datetime
datetime.date 表示日期的类,常用属性有year month day
datetime.time 表示时间的类,常用属性有hour minute second microsecond
datetime.datetime 表示日期时间
datetime.timedelta 表示时间间隔 有day seconds microseconds,minutes hours weeks
使用
from datetime import datetime
>>> datetime.now()
datetime.datetime(2015, 12, 9, 11, 22, 11, 407513)
>>> datetime.today()
datetime.datetime(2015, 12, 9, 11, 22, 13, 134834)
>>> datetime.weekday(datetime.now()) Monday == 0 ... Sunday == 6
2
>>> datetime.isoweekday(datetime.now()) Monday == 1 ... Sunday == 7
3
>>> datetime.date(datetime.now()).isoweekday()
3
>>> datetime.isocalendar(datetime.now())
--Return a 3-tuple containing ISO year, week number, and weekday
(2015, 50, 3)
>>> datetime.date(datetime.now())
datetime.date(2015, 12, 9)
>>> type(datetime.date(datetime.now()))
<type ‘datetime.date‘>
>>> datetime.date(datetime.now()).year
2015
>>> type(datetime.date(datetime.now()).year)
<type ‘int‘>
>>> datetime.date(datetime.now()).month
12
>>> datetime.date(datetime.now()).day
9
datetime.time与上面的类似
>>> datetime.strftime(datetime.today(),‘%Y-%m-%d‘)
‘2015-12-09‘
求某一天是星期几
>>> datetime.strptime(‘2015-10-10‘,‘%Y-%m-%d‘).isoweekday()
6
求某一天是那年中的第几天
>>> datetime.strptime(‘2015-10-10‘,‘%Y-%m-%d‘).timetuple().tm_yday
283
--strptime将字符串转换成datetime.datetime类型
--timetuple() 将datetime.datetime转换成time.struct_time
--tm_yday取出第几天
replace
datetime.replace([year[, month[, day[, hour[, minute[, second[, microsecond[, tzinfo]]]]]]]]):
>>> datetime.date(datetime.now())
datetime.date(2015, 12, 9)
>>> datetime.date(datetime.now()).replace(day=10)
datetime.date(2015, 12, 10)
datetime.timedelta
import datetime
>>> print datetime.datetime.now() - datetime.timedelta(days=5) --weeks hours minutes seconds
2015-12-04 15:30:39.536391
>>>
参考:http://www.jb51.net/article/31129.htm
shutil
高级的文件、文件夹、压缩包处理模块(都在什么情况下使用?)
shutil.copyfileobj(fsrc,fdes[,length]) --拷贝文件内容 这里的fsrc fdesc是文件句柄
shutil.copyfile(src,dst) ――拷贝文件 这里的src dst是文件名
shutil.copymode(src,dst) 仅拷贝权限,内容、组、用户均不变
shutil.copystat(src,dst) 仅拷贝状态信息,包括 mode bits,atime,mtime,flags
shutil.copy(src,dst) 拷贝文件和权限
shutil.copy2(src,dst) 拷贝文件和状态信息
shutil.ignore_patterns(*patterns)
shutil.copytree(src,dst,symlinks=False,ignore=None) 递归的去拷贝文件夹(有空研究一下ignore的用法)
shutil.rmtree(path[,ignore_errors[,onerror]]) 递归的删除文件夹 --相当于 rm –r
shutil.move(src,dst) 递归的移动一个文件或者文件夹去另一个地方,相当于mv,如果dst文件夹已存在,就将src移动到dst下
make_archive(base_name, format, root_dir=None, base_dir=None, verbose=0, dry_run=0, owner=None, group=None, logger=None) 创建压缩包并返回文件路径,
base_name 压缩包的文件名
format 压缩包格式 zip tar bztar gztar
root_dir 要压缩的文件夹路径 默认为当前目录
base_dir 要开始压缩的起始路径
owner,group是创建压缩包时用户和组,默认为当前的
logger 用于记录日志,通常是logging.logger的对象
其实是调用ZipFile和TarFile来处理的
面向对象
class Person(object): --类
def __init__(self,name): --初始化函数
self.name = name --
print ‘---àcreate :’,name
def say_name(self): --方法
print ‘my name is %s’ %self.name
p1 = Person(‘gf1’) --实例化
p2 = Person(‘gf2’)
p1.say_name() --person.say_name(p1)
p2.say_name() --person.say_name(p2)
代码重用
标签:python 模块 sys os time re shutil
原文地址:http://120662.blog.51cto.com/110662/1721312