标签:
1,web工作原理
2,http协议
3,浏览器缓存
4,cookie和session
--------------------------------------------------------------------------------------------------------------------------------
1,web工作原理
平时用浏览器,输入网址后回车,页面响应我们想要浏览的内容,简单操作的背后蕴涵了什么原理?
当输入url回车后,客户端(浏览器)会去请求DNS服务器,通过DNS获取域名对应的IP地址,然后通过这个地址找到对应的服务器,要求建立TCP连接,建立连接,客户端发送httpRequest(请求包)后,服务器接收并开始处理请求,调用自身服务,返回httpResponse(响应包),客户端收到响应包后开始渲染body主体,等到全部接收,断开与该服务器端的TCP连接。
URL:是统一资源定位符的英文缩写。包含协议,http服务器IP或者域名,端口号等。
DNS:域名系统的缩写。它是用于TCP/IP网络,从事将主机名或者域名翻译成IP地址的工作。
DNS的工作模式
总的来说,浏览器最后发起请求时基于IP来和服务器交互的。
-----------------------------------------------------------------------------------------------------------------------------------
HTTP协议详解
HTTP超文本传输协议是一种通过Internet发送与接收数据的协议,客户端发出一个请求,服务器响应这个请求。,它建立在TCP协议之上,一般采用TCP的80端口。
HTTP协议是无状态的,同一个客户端的这次请求和上次请求是没有对应关系,对HTTP服务器来说,它并不知道这两个请求是否来自同一个客户端。
url
http url的格式如右: http://host[":"port][abs_path]
HTTP协议详解之请求篇
http请求由三部分组成,分别是:请求行、消息报头、请求正文
GET /domains/example/ HTTP/1.1 //请求行: 请求方法 请求URI HTTP协议/协议版本 Host:www.iana.org //服务端的主机名 User-Agent:Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.4 (KHTML, like Gecko) Chrome/22.0.1229.94 Safari/537.4 //告诉HTTP服务器, 客户端使用的操作系统和浏览器的名称和版本 Accept:text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8 //客户端能接收的mine Accept-Encoding:gzip,deflate,sdch //是否支持流压缩 Accept-Charset:UTF-8,*;q=0.5 //客户端字符编码集 //空行,用于分割请求头和消息体 //消息体,请求资源参数,例如POST传递的参数
请求行的请求方法
请求方法有多种,最基本的有4种,分别是GET,POST,PUT,DELETE,对应资源的查,改,增,删4个操作。
主要看看GET和POST的区别:
HTTP协议详解之响应篇
HTTP响应也是由三个部分组成,分别是:状态行、消息报头、响应正文
HTTP/1.1 200 OK //状态行:HTTP协议版本号 状态码 状态消息 Server: nginx/1.0.8 //服务器使用的WEB软件名及版本 Date:Date: Tue, 30 Oct 2012 04:14:25 GMT //发送时间 Content-Type: text/html //服务器发送信息的类型 Transfer-Encoding: chunked //表示发送HTTP包是分段发的 Connection: keep-alive //保持连接状态 Content-Length: 90 //主体内容长度 //空行 用来分割消息头和主体 <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN"... //消息体
状态码
状态码用来告诉客户端,服务器是否产生了预期的Response。状态代码由三位数字组成,第一个数字是响应类别,有五种可能值:
1XX 提示信息 - 表示请求已被成功接收,继续处理
2XX 成功 - 表示请求已被成功接收,理解,接受
3XX 重定向 - 要完成请求必须进行更进一步的处理
4XX 客户端错误 - 请求有语法错误或请求无法实现
5XX 服务器端错误 - 服务器未能实现合法的请求
常见状态代码:
200 OK //客户端请求成功
400 Bad Request //客户端请求有语法错误,不能被服务器所理解
401 Unauthorized //请求未经授权,这个状态代码必须和WWW-Authenticate报头域一起使用
403 Forbidden //服务器收到请求,但是拒绝提供服务
404 Not Found //请求资源不存在,eg:输入了错误的URL
500 Internal Server Error //服务器发生不可预期的错误
503 Server Unavailable //服务器当前不能处理客户端的请求,一段时间后,可能恢复正常
Connection:keep-alive
从HTTP/1.1起,默认都开启了Keep-Alive,保持连接特性,简单地说,当一个网页打开完成后,客户端和服务器之间用于传输HTTP数据的TCP连接不会关闭,如果客户端再次访问这个服务器上的网页,会继续使用这一条已经建立的连接
Keep-Alive不会永久保持连接,它有一个保持时间,可以在不同服务器软件(如Apache)中设置这个时间。
-------------------------------------------------------------------------------------------------------------------------------------
浏览器缓存
是把页面信息保存到用户本地磁盘里,包括html缓存和图片js,css等资源的缓存。
缓存的优点:
缓存工作原理:
页面缓存状态是由http header决定的,一个浏览器请求信息,一个是服务器响应信息。主要包括Pragma: no-cache、Cache-Control、 Expires、 Last-Modified、If-Modified-Since。
原理主要分三步:
原理图:
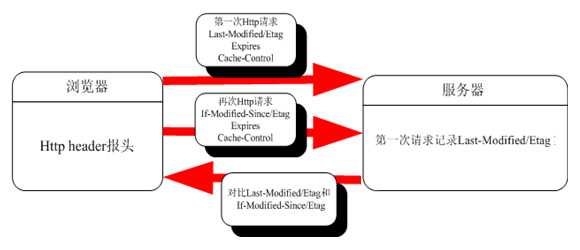
流程图:

与缓存相关的HTTP扩展消息头
Expires:设置页面过期时间,格林威治时间GMT
Cache-Control:更细致的控制缓存的内容
Last-Modified:请求对象最后一次的修改时间 用来判断缓存是否过期 通常由文件的时间信息产生
ETag:响应中资源的校验值,在服务器上某个时段是唯一标识的。ETag是一个可以 与Web资源关联的记号(token),和Last-Modified功能差不多,也是一个标识符,一般和Last-Modified一起使用,加强服务器判断的准确度。
Date:服务器的时间
If-Modified-Since:客户端存取的该资源最后一次修改的时间,用来和服务器端的Last-Modified做比较
If-None-Match:客户端存取的该资源的检验值,同ETag。
Cache-Control的主要参数
Cache-Control: private/public Public 响应会被缓存,并且在多用户间共享。 Private 响应只能够作为私有的缓存,不能再用户间共享。
Cache-Control: no-cache:不进行缓存
Cache-Control: max-age=x:缓存时间 以秒为单位
Cache-Control: must-revalidate:如果页面是过期的 则去服务器进行获取。
主要通过修改服务器的配置来实现缓存。
------------------------------------------------------------------------------------------------------------------------------------
cookie和session
因为HTTP协议是无状态的,所以用户的每一次请求都是无状态的,我们不知道在整个Web操作过程中哪些连接与该用户有关,如何解决这个问题?Web经典的解决方案是cookie和session,cookie是一种客户端机制,把用户数据保存在客户端,而session是一种服务器端的机制。
cookie
Cookie是由浏览器维持的,在本地计算机保存一些用户操作的历史信息(当然包括登录信息),并在用户再次访问该站点时浏览器通过HTTP协议将本地cookie内容发送给服务器,从而完成验证,或继续上一步操作。
cookie是有时间限制的,根据生命期不同分成两种:会话cookie和持久cookie;
会话cookie:
如果不设置过期时间,只要关闭浏览器窗口,cookie就消失了。这种生命期为浏览会话期的cookie被称为会话cookie。会话cookie一般保存在内存里。
持久cookie:
浏览器就会把cookie保存到硬盘上,关闭后再次打开浏览器,这些cookie依然有效直到超过设定的过期时间。存储在硬盘上的cookie可以在不同的浏览器进程间共享,比如两个IE窗口。而对于保存在内存的cookie,不同的浏览器有不同的处理方式。
ession机制是一种服务器端的机制,服务器使用一种类似于散列表的结构(也可能就是使用散列表)来保存信息,每一个网站访客都会被分配给一个唯一的标志符,即sessionID。
程序需要为某个客户端的请求创建一个session的时候,服务器首先检查这个客户端的请求里是否包含了一个sessionID,如果有则说明以前已经为此客户创建过session,服务器就按照sessionID把这个session检索出来使用。如果没有,则为此客户创建一个session并且同时生成一个与此session相关联的sessionID,将这个sessionID放在本次响应中返回给客户端保存在cookie里。
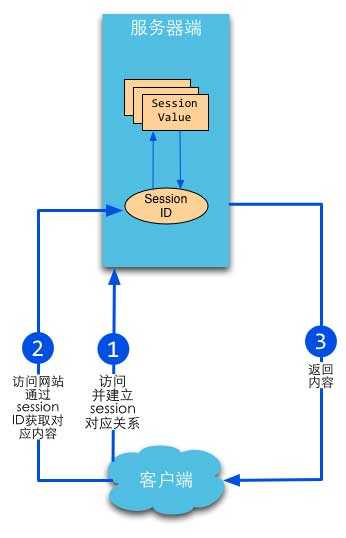
总的来说,session通过cookie,在客户端保存sessionID,而将用户的其他会话消息保存在服务端的session对象中。而cookie需要将所有信息都保存在客户端。
标签:
原文地址:http://www.cnblogs.com/ytb-wpq/p/5036946.html