标签:
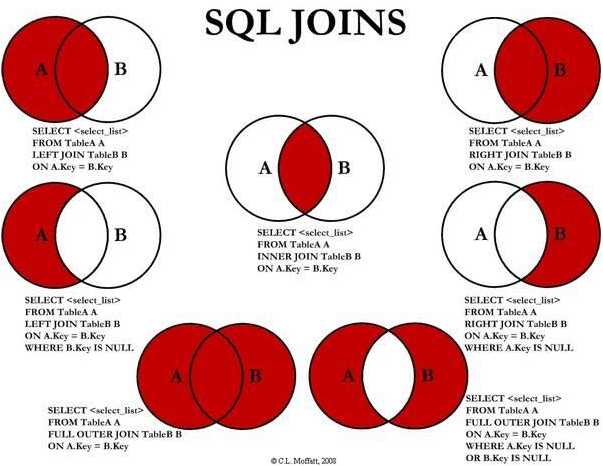
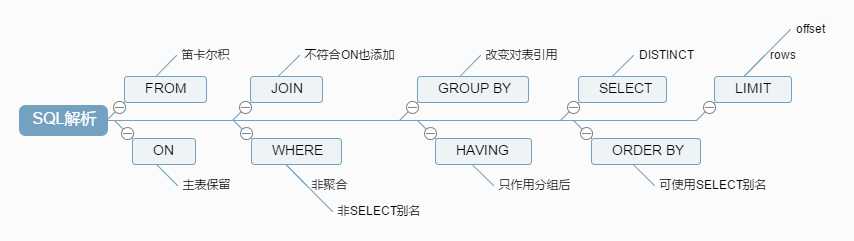
SELECT DISTINCT < select_list > FROM < left_table > < join_type > JOIN < right_table > ON < join_condition > WHERE < where_condition > GROUP BY < group_by_list > HAVING < having_condition > ORDER BY < order_by_condition > LIMIT < limit_number >
1 FROM <left_table> 2 ON <join_condition> 3 <join_type> JOIN <right_table> 4 WHERE <where_condition> 5 GROUP BY <group_by_list> 6 HAVING <having_condition> 7 SELECT 8 DISTINCT <select_list> 9 ORDER BY <order_by_condition> 10 LIMIT <limit_number>
create database testQuery
CREATE TABLE table1 ( uid VARCHAR(10) NOT NULL, name VARCHAR(10) NOT NULL, PRIMARY KEY(uid) )ENGINE=INNODB DEFAULT CHARSET=UTF8; CREATE TABLE table2 ( oid INT NOT NULL auto_increment, uid VARCHAR(10), PRIMARY KEY(oid) )ENGINE=INNODB DEFAULT CHARSET=UTF8;
INSERT INTO table1(uid,name) VALUES(‘aaa‘,‘mike‘),(‘bbb‘,‘jack‘),(‘ccc‘,‘mike‘),(‘ddd‘,‘mike‘); INSERT INTO table2(uid) VALUES(‘aaa‘),(‘aaa‘),(‘bbb‘),(‘bbb‘),(‘bbb‘),(‘ccc‘),(NULL);
SELECT a.uid, count(b.oid) AS total FROM table1 AS a LEFT JOIN table2 AS b ON a.uid = b.uid WHERE a. NAME = ‘mike‘ GROUP BY a.uid HAVING count(b.oid) < 2 ORDER BY total DESC LIMIT 1;
mysql> select * from table1,table2; +-----+------+-----+------+ | uid | name | oid | uid | +-----+------+-----+------+ | aaa | mike | 1 | aaa | | bbb | jack | 1 | aaa | | ccc | mike | 1 | aaa | | ddd | mike | 1 | aaa | | aaa | mike | 2 | aaa | | bbb | jack | 2 | aaa | | ccc | mike | 2 | aaa | | ddd | mike | 2 | aaa | | aaa | mike | 3 | bbb | | bbb | jack | 3 | bbb | | ccc | mike | 3 | bbb | | ddd | mike | 3 | bbb | | aaa | mike | 4 | bbb | | bbb | jack | 4 | bbb | | ccc | mike | 4 | bbb | | ddd | mike | 4 | bbb | | aaa | mike | 5 | bbb | | bbb | jack | 5 | bbb | | ccc | mike | 5 | bbb | | ddd | mike | 5 | bbb | | aaa | mike | 6 | ccc | | bbb | jack | 6 | ccc | | ccc | mike | 6 | ccc | | ddd | mike | 6 | ccc | | aaa | mike | 7 | NULL | | bbb | jack | 7 | NULL | | ccc | mike | 7 | NULL | | ddd | mike | 7 | NULL | +-----+------+-----+------+ 28 rows in set (0.00 sec)
mysql> SELECT -> * -> FROM -> table1, -> table2 -> WHERE -> table1.uid = table2.uid -> ; +-----+------+-----+------+ | uid | name | oid | uid | +-----+------+-----+------+ | aaa | mike | 1 | aaa | | aaa | mike | 2 | aaa | | bbb | jack | 3 | bbb | | bbb | jack | 4 | bbb | | bbb | jack | 5 | bbb | | ccc | mike | 6 | ccc | +-----+------+-----+------+ 6 rows in set (0.00 sec)
mysql> SELECT -> * -> FROM -> table1 AS a -> LEFT OUTER JOIN table2 AS b ON a.uid = b.uid; +-----+------+------+------+ | uid | name | oid | uid | +-----+------+------+------+ | aaa | mike | 1 | aaa | | aaa | mike | 2 | aaa | | bbb | jack | 3 | bbb | | bbb | jack | 4 | bbb | | bbb | jack | 5 | bbb | | ccc | mike | 6 | ccc | | ddd | mike | NULL | NULL | +-----+------+------+------+ 7 rows in set (0.00 sec)
mysql> SELECT -> * -> FROM -> table1 AS a -> LEFT OUTER JOIN table2 AS b ON a.uid = b.uid -> WHERE -> a. NAME = ‘mike‘; +-----+------+------+------+ | uid | name | oid | uid | +-----+------+------+------+ | aaa | mike | 1 | aaa | | aaa | mike | 2 | aaa | | ccc | mike | 6 | ccc | | ddd | mike | NULL | NULL | +-----+------+------+------+ 4 rows in set (0.00 sec)
mysql> SELECT -> * -> FROM -> table1 AS a -> LEFT OUTER JOIN table2 AS b ON a.uid = b.uid -> WHERE -> a. NAME = ‘mike‘ -> GROUP BY -> a.uid; +-----+------+------+------+ | uid | name | oid | uid | +-----+------+------+------+ | aaa | mike | 1 | aaa | | ccc | mike | 6 | ccc | | ddd | mike | NULL | NULL | +-----+------+------+------+ 3 rows in set (0.00 sec)
mysql> SELECT -> * -> FROM -> table1 AS a -> LEFT OUTER JOIN table2 AS b ON a.uid = b.uid -> WHERE -> a. NAME = ‘mike‘ -> GROUP BY -> a.uid -> HAVING -> count(b.oid) < 2; +-----+------+------+------+ | uid | name | oid | uid | +-----+------+------+------+ | ccc | mike | 6 | ccc | | ddd | mike | NULL | NULL | +-----+------+------+------+ 2 rows in set (0.00 sec)
mysql> SELECT -> a.uid, -> count(b.oid) AS total -> FROM -> table1 AS a -> LEFT OUTER JOIN table2 AS b ON a.uid = b.uid -> WHERE -> a. NAME = ‘mike‘ -> GROUP BY -> a.uid -> HAVING -> count(b.oid) < 2; +-----+-------+ | uid | total | +-----+-------+ | ccc | 1 | | ddd | 0 | +-----+-------+ 2 rows in set (0.00 sec)
mysql> SELECT -> a.uid, -> count(b.oid) AS total -> FROM -> table1 AS a -> LEFT OUTER JOIN table2 AS b ON a.uid = b.uid -> WHERE -> a. NAME = ‘mike‘ -> GROUP BY -> a.uid -> HAVING -> count(b.oid) < 2 -> ORDER BY -> total DESC; +-----+-------+ | uid | total | +-----+-------+ | ccc | 1 | | ddd | 0 | +-----+-------+ 2 rows in set (0.00 sec)
mysql> SELECT -> a.uid, -> count(b.oid) AS total -> FROM -> table1 AS a -> LEFT JOIN table2 AS b ON a.uid = b.uid -> WHERE -> a. NAME = ‘mike‘ -> GROUP BY -> a.uid -> HAVING -> count(b.oid) < 2 -> ORDER BY -> total DESC -> LIMIT 1; +-----+-------+ | uid | total | +-----+-------+ | ccc | 1 | +-----+-------+ 1 row in set (0.00 sec)
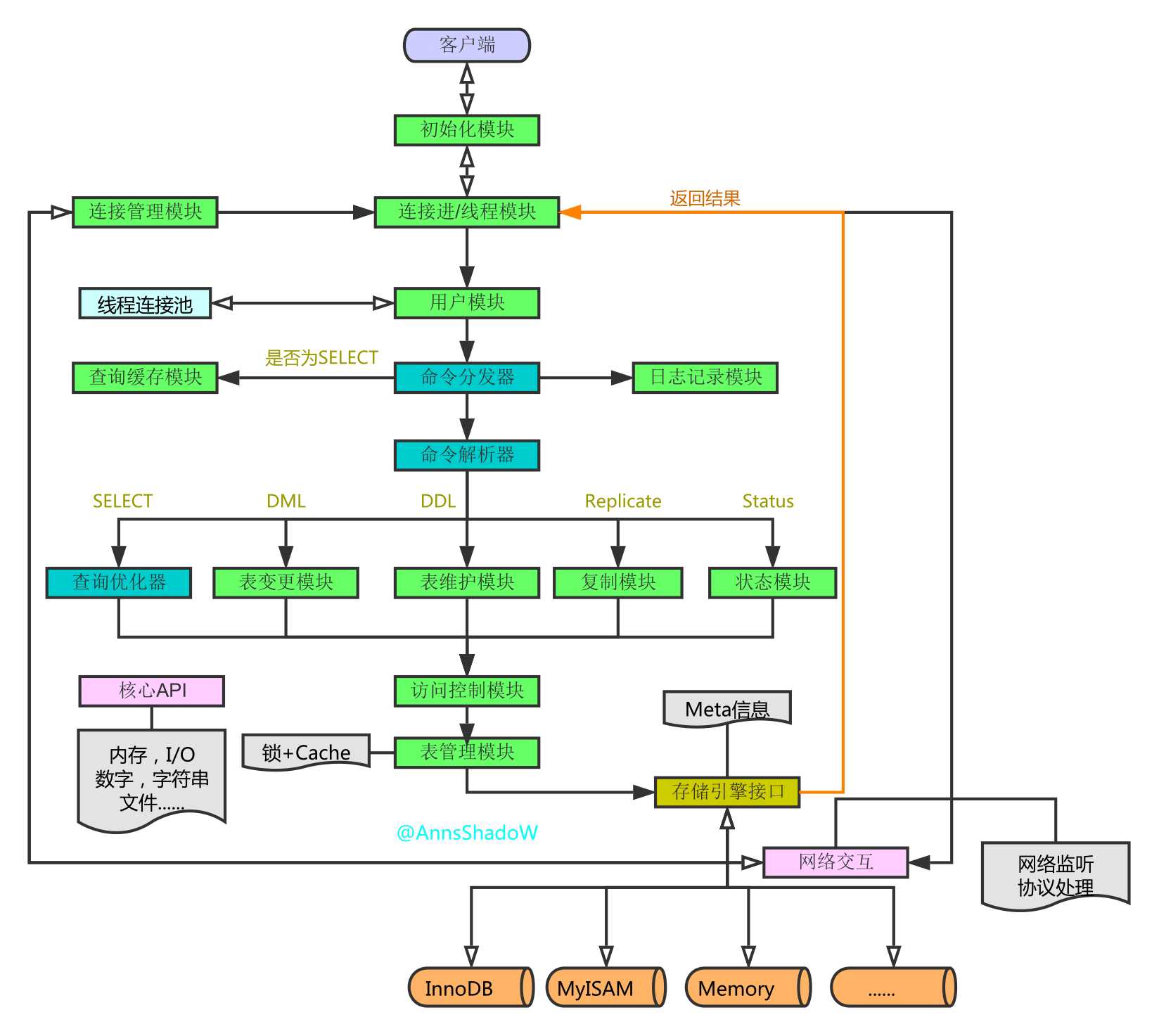
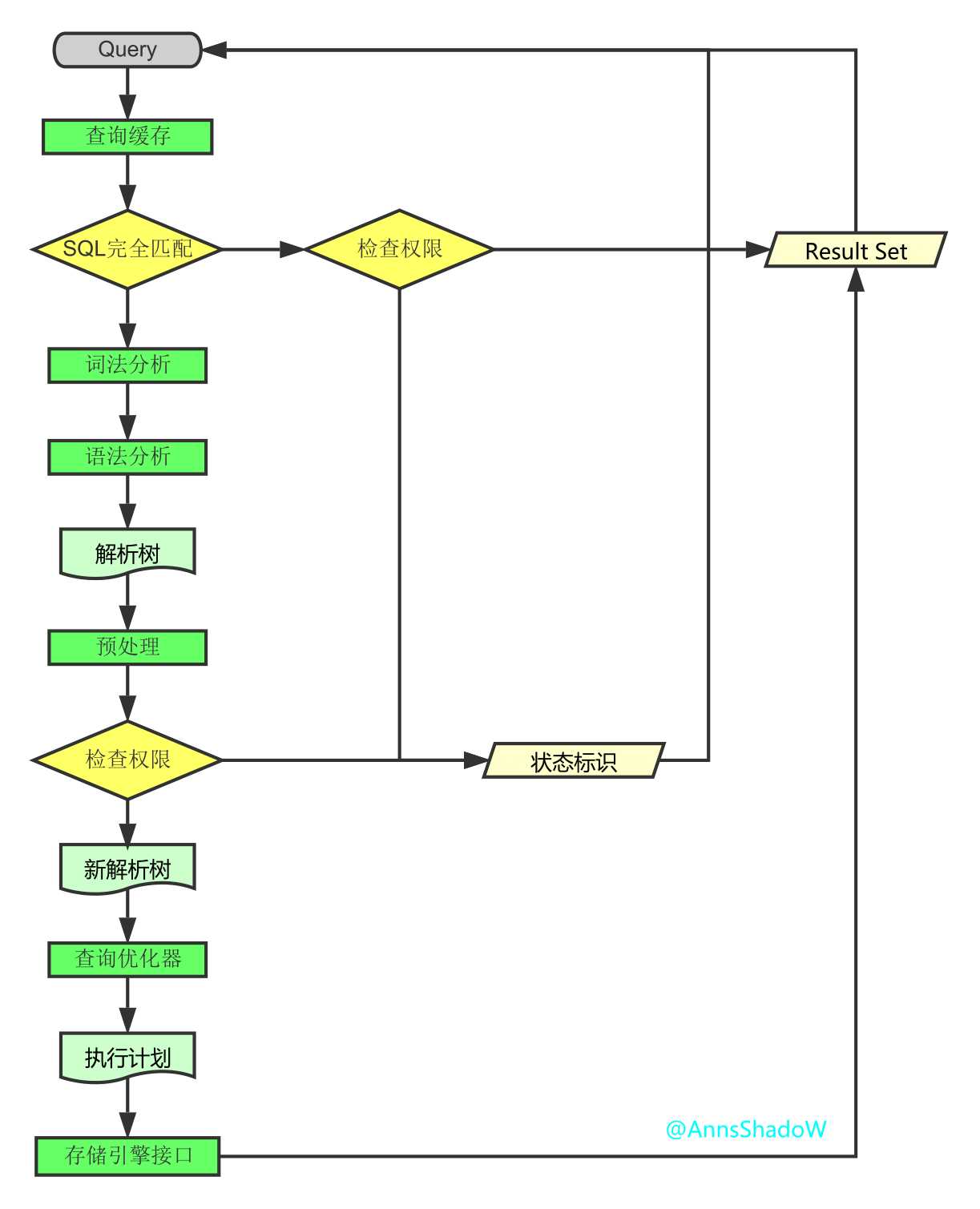
步步深入:MySQL架构总览->查询执行流程->SQL解析顺序
标签:
原文地址:http://www.cnblogs.com/annsshadow/p/5037667.html