标签:
一、java日志组件
1、common-logging
common-logging是apache提供的一个通用的日志接口。用户可以自由选择第三方的日志组件作为具体实现,像log4j,或者jdk自带的logging, common-logging会通过动态查找的机制,在程序运行时自动找出真正使用的日志库。但由于它使用了ClassLoader寻找和载入底层的日 志库, 导致了象OSGI这样的框架无法正常工作,由于其不同的插件使用自己的ClassLoader。 OSGI的这种机制保证了插件互相独立,然而确使Apache Common-Logging无法工作。当然,common-logging内部有一个Simple logger的简单实现,但是功能很弱。所以使用common-logging,通常都是配合着log4j来使用。使用它的好处就是,代码依赖是common-logging而非log4j, 避免了和具体的日志方案直接耦合,在有必要时,可以更改日志实现的第三方库。
import org.apache.commons.logging.Log; import org.apache.commons.logging.LogFactory; public class A { private static Log logger = LogFactory.getLog(this.getClass()); }
动态查找原理:Log 是一个接口声明。LogFactory 的内部会去装载具体的日志系统,并获得实现该Log 接口的实现类。LogFactory 内部装载日志系统的流程如下:
首先,寻找org.apache.commons.logging.LogFactory 属性配置。
否则,利用JDK1.3 开始提供的service 发现机制,会扫描classpah 下的META-INF/services/org.apache.commons.logging.LogFactory文件,若找到则装载里面的配置,使用里面的配置。
否则,从Classpath 里寻找commons-logging.properties ,找到则根据里面的配置加载。
否则,使用默认的配置:如果能找到Log4j 则默认使用log4j 实现,如果没有则使用JDK14Logger 实现,再没有则使用commons-logging 内部提供的SimpleLog 实现。
从上述加载流程来看,只要引入了log4j 并在classpath 配置了log4j.xml ,则commons-logging 就会使log4j 使用正常,而代码里不需要依赖任何log4j 的代码。
2、slf4j
slf4j全称为Simple Logging Facade for JAVA,java简单日志门面。类似于Apache Common-Logging,是对不同日志框架提供的一个门面封装,可以在部署的时候不修改任何配置即可接入一种日志实现方案。但是,他在编译时静态绑定真正的Log库。使用SLF4J时,如果你需要使用某一种日志实现,那么你必须选择正确的SLF4J的jar包的集合(各种桥接包)。
import org.slf4j.Logger; import org.slf4j.LoggerFactory; public class A { private static Log logger = LogFactory.getLog(this.getClass()); }
slf4j静态绑定原理:SLF4J 会在编译时会绑定import org.slf4j.impl.StaticLoggerBinder; 该类里面实现对具体日志方案的绑定接入。任何一种基于slf4j 的实现都要有一个这个类。如:org.slf4j.slf4j-log4j12-1.5.6: 提供对 log4j 的一种适配实现。注意:如果有任意两个实现slf4j 的包同时出现,那么就可能出现问题。
slf4j 与 common-logging 比较
common-logging通过动态查找的机制,在程序运行时自动找出真正使用的日志库。由于它使用了ClassLoader寻找和载入底层的日志库, 导致了象OSGI这样的框架无法正常工作,因为OSGI的不同的插件使用自己的ClassLoader。 OSGI的这种机制保证了插件互相独立,然而却使Apache Common-Logging无法工作。
slf4j在编译时静态绑定真正的Log库,因此可以再OSGI中使用。另外,SLF4J 支持参数化的log字符串,避免了之前为了减少字符串拼接的性能损耗而不得不写的if(logger.isDebugEnable()),现在你可以直接写:logger.debug(“current user is: {}”, user)。拼装消息被推迟到了它能够确定是不是要显示这条消息的时候,但是获取参数的代价并没有幸免。
Object[] params = {value1, value2, value3};
logger.debug("first value: {}, second value: {} and third value: {}.", params);
3、log4j
Apache的一个开放源代码项目,通过使用Log4j,我们可以控制日志信息输送的目的地是控制台、文件、GUI组件、甚至是套接口服务 器、NT的事件记录器、UNIX Syslog守护进程等;用户也可以控制每一条日志的输出格式;通过定义每一条日志信息的级别,用户能够更加细致地控制日志的生成过程。这些可以通过一个 配置文件来灵活地进行配置,而不需要修改程序代码。
4、logback
Logback是由log4j创始人设计的又一个开源日记组件。logback当前分成三个模块:logback-core,logback- classic和logback-access。logback-core是其它两个模块的基础模块。logback-classic是log4j的一个 改良版本。此外logback-classic完整实现SLF4J API使你可以很方便地更换成其它日记系统如log4j或JDK14 Logging。logback-access访问模块与Servlet容器集成提供通过Http来访问日记的功能。
Log4j 与 LogBack 比较
LogBack作为一个通用可靠、快速灵活的日志框架,将作为Log4j的替代和SLF4J组成新的日志系统的完整实现。LOGBack声称具有极佳的性能,“ 某些关键操作,比如判定是否记录一条日志语句的操作,其性能得到了显著的提高。这个操作在LogBack中需要3纳秒,而在Log4J中则需要30纳秒。 LogBack创建记录器(logger)的速度也更快:13微秒,而在Log4J中需要23微秒。更重要的是,它获取已存在的记录器只需94纳秒,而 Log4J需要2234纳秒,时间减少到了1/23。跟JUL相比的性能提高也是显著的”。 另外,LOGBack的所有文档是全面免费提供的,不象Log4J那样只提供部分免费文档而需要用户去购买付费文档。
使用slf4j+logback的优势:
如果在单纯的logging环境中,使用SLF4J意义不大。如果想在各种logger API中切换,SELF4J是理想选择,另外在新的项目中,使用SLF4J+Logback是比较好的日志框架选型。
logback.xml的配置
<?xml version="1.0" encoding="UTF-8"?> <configuration> <!-- log output to file --> <appender name="ROLLING" class="ch.qos.logback.core.rolling.RollingFileAppender"> <rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy"> <!-- 按天回滚 daily --> <!-- log.dir 在maven profile里配置 --> <fileNamePattern>${ms.log.home}/ms-api-%d{yyyy-MM-dd}.log </fileNamePattern> <!-- 日志最大的历史 7天 --> <maxHistory>7</maxHistory> </rollingPolicy> <encoder> <pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger{36} [%file:%line] - %msg%n</pattern> </encoder> </appender> <appender name="API_QUERY_MONITOR" class="ch.qos.logback.core.rolling.RollingFileAppender"> <rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy"> <!-- 按天回滚 daily --> <!-- log.dir 在maven profile里配置 --> <fileNamePattern>${ms.log.home}/ms-api-query-%d{yyyy-MM-dd}.log </fileNamePattern> <!-- 日志最大的历史 7天 --> <maxHistory>2</maxHistory> </rollingPolicy> <encoder> <pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger{36} [%file:%line] - %msg%n</pattern> </encoder> </appender> <!-- log output to console --> <appender name="STDOUT" class="ch.qos.logback.core.ConsoleAppender"> <encoder> <pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger{36}[%file:%line] - %msg%n</pattern> </encoder> </appender> <!-- Perf4J appenders --> <!-- This AsyncCoalescingStatisticsAppender groups StopWatch log messages into GroupedTimingStatistics messages which it sends on the file appender defined below --> <!-- This file appender is used to output aggregated performance statistics --> <appender name="perf4jFileAppender" class="ch.qos.logback.core.rolling.RollingFileAppender"> <File>${ms.log.home}/ms-performance.log</File> <encoder> <!-- <Pattern>%date %-5level [%thread] %logger{36} [%file:%line] %msg%n </Pattern> --> <Pattern>%date %-5level [%file:%line] %msg%n</Pattern> </encoder> <rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy"> <FileNamePattern>${ms.log.home}/ms-performance.%d{yyyy-MM-dd}.log </FileNamePattern> <maxHistory>2</maxHistory> </rollingPolicy> </appender> <appender name="CoalescingStatistics" class="org.perf4j.logback.AsyncCoalescingStatisticsAppender"> <param name="TimeSlice" value="60000" /> <appender-ref ref="perf4jFileAppender" /> </appender> <!-- Loggers --> <!-- The Perf4J logger. Note that org.perf4j.TimingLogger is the value of the org.perf4j.StopWatch.DEFAULT_LOGGER_NAME constant. Also, note that additivity is set to false, which is usually what is desired - this means that timing statements will only be sent to this logger and NOT to upstream loggers. --> <logger name="org.perf4j.TimingLogger" additivity="false"> <level value="INFO" /> <appender-ref ref="CoalescingStatistics" /> </logger> <logger name="com.wy.api.out.OutApi" level="debug"> <appender-ref ref="ROLLING" /> </logger> <logger name="com.wy.util.PlayerDataUtil" level="info"> <appender-ref ref="ROLLING" /> </logger> <logger name="com.wy.QueryServiceImpl" level="info"> <appender-ref ref="REMOTE_QUERY_MONITOR" /> </logger> <root level="info"> <appender-ref ref="ROLLING" /> </root> </configuration>
二、如何记录日志
1、日志级别
在记录日志时,大家都会要选择合理的日志级别、合理的控制日志内容。我们都知道debug级别日志在生产环境中是不会输出到文件中的,但是也可能带来不小的开销。我们看下Log4j2.x性能文档中一组对比:
logger.debug("Entry number: " + i + " is " + String.valueOf(entry[i]));
logger.debug("Entry number: {} is {}", i, entry[i]);
上面两条语句在日志输出上的效果是一样的,但是在关闭DEBUG日志时,它们的开销就不一样了,主要的影响在于字符串转换和字符串拼接上,无论是否生效,前者都会将变量转换为字符串并进行拼接,而后者则只会在需要时执行这些操作。Log4J官方的测试结论是两者在性能上能相差两个数量级。试想一下,如果某个对象的toString()方法里用了ToStringBuilder来反射输出几十个属性时,这时能省下多少资源。
因此,某些仍在使用Apache Commons Logging(它们不支持{}模板的写法)、Log4J 1.x或LogBack时,采用模版的方式。
2、日志内容
日志中一般都会记录日期、线程名、类信息、MDC变量、日志消息等等,根据Takipi的测试,如果在日志中加入class,性能会急剧下降,比起LogBack的默认配置,吞吐量的降幅在6成左右。如果一定要打印类信息,可以考虑用类名来命名Logger。
在分布式系统中,一个请求可能会经过多个不同的子系统,这时最好生成一个UUID附在请求中,每个子系统在打印日志时都将该UUID放在MDC里,便于后续查询相关的日志。
3、Appender
同步写的Appender在高并发大流量的系统里多少有些力不从心,这时就该使用AsyncAppender了,同样是使用LogBack:
在10线程并发下,输出200字符的INFO日志,AsyncAppender的吞吐量最高能是FileAppender的3.7倍。在不丢失日志的情况下,同样使用AsyncAppender,队列长度对性能也会有一定影响。
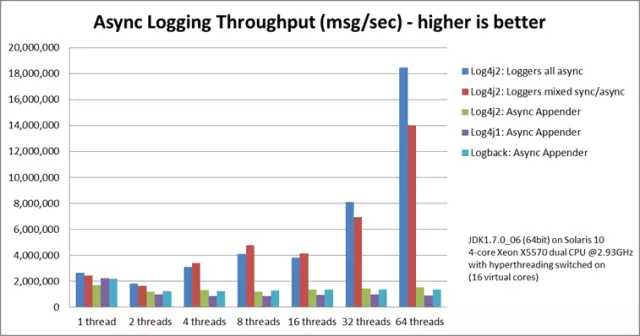
如果使用Log4J 2.x,那么除了有AsyncAppender,还可以考虑性能更高的异步Logger,由于底层用了Disruptor,没有锁的开销,性能更为惊人。根据Log4J 2.x的官方测试,同样使用Log4J 2.x:
64线程下,异步Logger比异步Appender快12倍,比同步Logger快68倍。
同样是异步,不同的库之间也会有差异:
同等硬件环境下,Log4J 2.x全部使用异步Logger会比LogBack的AsyncAppender快12倍,比Log4J 1.x的异步Appender快19倍。
如果一定要用同步的Appender,那么可以考虑使用ConsoleAppender,然后将STDOUT重定向到文件里,这样大约也能有10%左右的性能提升。
Log4J 2.x的异步Logger性能强悍,但也有不同的声音,觉得这只是个看上去很优雅,只能当成一个玩具。关于这个问题,还是留给读者自己来思考吧。
如何记录线程名称
往往日志中线程名称大部分类似 “http-nio-8080-exec-3″,这个是线程池或者容器给它们取的。线程名称是你日志中主要标记,你必须确保正确地使用它。这就意味着给线程取的名称必须结合上下文,例如servlet的名称或者任务此刻的意义,还有一些动态的上下文环境,例如一个用户或消息ID。与logid有异曲同工之妙,下文中会有说明。
因此,代码的入口处应该像下面这样:
Thread.currentThread().setName(ProcessTask.class.getName() + “: “+ message.getID);
一个更高级的写法是加载一个线程本地变量到当前线程中,并且配置一个自定义日志(appender),自动把这个变量加入到每一条日志记录中
分布式标识
在分布式的服务中,当我们的一个服务执行,可能会跨越多个服务。一旦服务执行失败了我们要知道是哪个环节出了问题。很多日志分析工具可以帮你进行日志归类,前提是你日志中带有它们可以用来做分类的唯一ID。(校对注:当A应用调用B应用接口时,而B应用的接口实现又需要调用应用C的接口时,一旦报错很难定位这个请求到底是在调用哪个应用时报错的?所以就使用一个唯一ID把这个请求链路串起来。)
这意味着每一个操作进入到你的系统中都应该有一个唯一的ID,用这个ID直到它执行完成。注意,那些持久化标示符,例如用户的ID在这里可能不是很好的选择,因为一个用户可能有多个操作发生在同一个日志中,这会使得隔离出一个特定的操作流变得更难。UUID在这边是一个很好的选择,这个值可以被作为线程的名称或者作为一个TLS-线程本地存储。
很多情况下,外部API调用失败的原因是提供的入参是未预知的。把那些输入参数现成的记录在日志中是你修复代码的关键。
这个点上你可能会选择不记录错误日志,但是必须记录抛出的异常,这是对的。在这种情况下,只需要尽可能多的收集传递给调用的相关参数,并且把他们格式化到异常错误信息中。
只需要却表异常被捕获,并且和调用栈一起被高日志级别记录。
try { return s3client.generatePresignedUrl(request); } catch (Exception e) { String err = String.format(“Error generating request: %s bucket: %s key: %s. method: %s", request, bucket, path, method); log.error(err, e); //you can also throw a nested exception here with err instead. }
标签:
原文地址:http://www.cnblogs.com/exceptioneye/p/5021664.html