标签:
概述:
在一篇文章中,当要查找一个字符串(由多个字符组成)或者一个字符时,在搜索框中输入,然后进行搜 索,就可得到结果。
但是,当你查找一些复杂格式的字符串时,比如,查找以下字符串时,以"m"开头,紧接着两个任意 字符,再紧接着一个"n"字符
,这时,在搜索框中我们如何输入搜索字符串?通过键盘敲入第一个字符"m"后,紧接着的任意两个字 符,如何敲入?
这个,嗯,嗯,嗯。。。。,我们就会卡壳了。这时候,我们就要使用正则表达式进行 搜索。
正则表达式可以对任意字符串进行搜索、替换等操作。
元字符(metacharacters):
\ : the backslash
^ : the caret
$ : the dollar sign
. : the period or dot
| : the vertical bar or pipe symbol
? : the question mark
* : the asterisk or star
+ : the plus sign
( : the opening parenthesis
) : the closinig parenthesis
[ : the opening square bracket
] : the closing square bracket
{ : the opening curly brace
} : the closing curly brace
以上特殊的字符被称为元字符,在正则表达式中有着特殊的意义。如果你想在文本中这搜索这些元字符,
那么必须在元字符前面添加反斜线( \ ),来告诉正则表达式引擎,把元字符作为普通字符对待。例如:
你要查找:1+1=2,那么你的正则表达式就要写成:1\+1=2
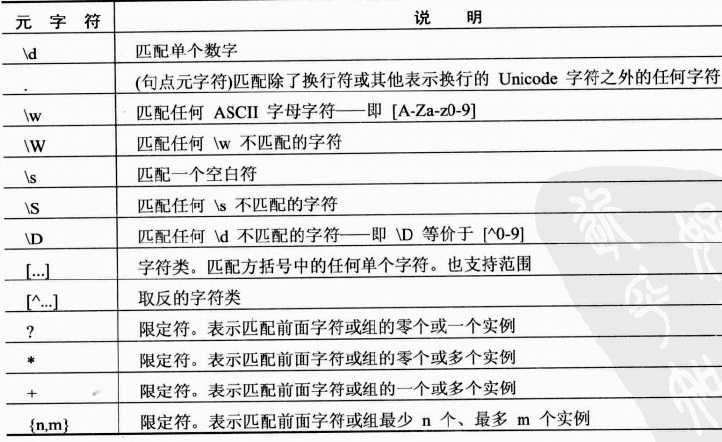
"." 句点元字符
只匹配一个字符。这个字符几乎是任意一个字符,比如字母、标点符号、数字、下划线等,同时也不区分 大小写。
注意,不匹配换行符 "\n", 并且句点字符与 "*" 或者 "+"字符写在一起时,搜索引擎会进行贪婪匹 配。
也就是说它会匹配尽可能的字符,这有可能与你的预期不符。
"\w" 元字符(小写)
只匹配一个字符。这个字符是字母、数字和下划线。
注意,不匹配 标点符号、空白符号
"\W" 元字符(大写)
只匹配一个字符。这个字符是 \w 不匹配的字符,意思与 \w 相反。换句话说,就是匹配任何非字母、 非数字、非下划线的字符
"\d" 元字符(小写)
只匹配一个字符。这个字符是 0 到 9 的数字。
"\D" 元字符(大写)
只匹配一个字符。这个字符是 \d 不匹配的字符,意思与 \d 相反。换句话说,就是匹配任何非数字的 字符
"\s" 元字符(小写)
只匹配一个字符。这个字符是空白字符,包括一个空格符( )、一个制表符(\t)、一个换行符(\n)
"\S" 元字符(小写)
只匹配一个字符。这个字符是 \s 不匹配的字符,意思与 \s 相反,也就是非空白字符
字符类(Character Classes or Character Sets)
字符类就是使用"[]"括起来的一些无序字符,正则表达式引擎在匹配时,从字符类中把一个一个字符抽出
来进行匹配。假如表达式为:Mo[eao]n,那么搜索引擎就会以 "Moen" 或者 "Moan" 或者 "Moon"进行 模式匹配。
字符类有一些简写形式,表示某一个范围的字符,这些字符必须是连续的,比如:
[a-z]表示小写字母 a 到 z,意思与 [abcdefghijklmnopqrstuvwxyz]等价
[r-t]表示小写字母 r 到 t,意思与 [rst]等价
[A-Z]表示小写字母 A 到 Z,意思与 [ABCDEFGHIJKLMNOPQRSTUVWXYZ]等价
[0-9]表示数字,意思与 [0123456789]等价
"^" 元字符
当"^" 元字符出现在字符类的第一个位置时,表示取反的意思,例如:
[^acm] ,表示匹配非 a 或 c 或 m 的字符。
当"^" 元字符出现在字符类的其他位置时,表示普通的"^"字符,例如:
[a^cm] ,表示匹配 a 或 ^ 或 c 或 m 的字符。
当"^" 元字符出现在非字符类时,表示匹配一个字符串或一行的开始位置
"$" 元字符
匹配一个字符串或一行的结束位置
"\b" 元字符
匹配一个单词的边界(出现在一个单词的开始或者结束位置)
"\<" 和 "\>" 元字符
匹配一个单词的开始和结束位置
"()"分组介绍
使用小括号"(abc)、(abc|abcdg)"括起来的字符串就称为一个分组。
分组有一些隐式变量($1、$2、$3 等),可供随后的替换、重复等操作使用,例如:
正则表达式为:"((\w(\d{2}))(( )(\d{2})))"
搜索的文本内容为:"A22 33"
那么执行匹配之后的结果如下:
$1, 引用的分组为 "((\w(\d{2}))(( )(\d{2})))" , 匹配结果为:"A22 33"
$2, 引用的分组为 "(\w(\d{2}))", 匹配结果为:"A22"
$3, 引用的分组为 "(\d{2})", 匹配结果为:"22"
$4, 引用的分组为 "(( )(\d{2}))", 匹配结果为:" 33"
$5, 引用的分组为 "( )", 匹配结果为:" "
$6, 引用的分组为 "(\d{2})", 匹配结果为:"33"
反向引用在分组中的应用
有时候需要查找重复单词的操作,这时候就需要反向引用操作。反向引用,意思是引用前面匹配的分组。
例如:"M(o)\1n lig(h|e)t",第一个分组是"(o)",其后的 "\1" 表示反响引用第一个分组的匹配结果
反向引用的格式:一个反斜线加一个数字,比如 "\2" 表示引用第二个分组
"?:" 在分组中的应用
表示正则表达式引擎在返回最终的匹配结果时,删除"?:"所在分组的匹配结果。去掉不需要的匹配项。
例如,"(The)(?:[ea])(on)",匹配的结果如下,
$1, 引用的分组为 "(The)"
$2, 引用的分组为 "(on)"
向前查找和向后查找
注意,此应用的关键在于,出现在指定匹配项之后的字符序列不会被正则表达式引擎返回。
(?: ...) , 非捕获组
(?= ...) , 肯定式向前查找
(?! ...) , 否定式向前查找
(?<= ...) , 肯定式向后查找
(?<! ...) , 否定式向后查找
POSIX 字符类,[:alnum:] 等价于 [A-Za-z0-9],[:digit:] 等价于 [0-9], JS 中不支持此写法
JavaScript 支持的元字符
JavaScript 正则表达式有两种写法
1、 var reg = new RegExp(param1[, param2]);
param1 参数表示正则表达式的模式
param2 参数是可选的,值为“gmi”中的一个或者多个,
g 表示 global, 进行全局匹配
m 表示 multiline,进行多行匹配
i 表示 ignoreCase, 匹配时不区分大小写
2、var reg = /[abc]{3}/[gmi];
JavaScript 正则表达式对象的主要方法
1、test()
测试一个字符串是否与模式匹配?只要存在一次匹配就返回 true;没有匹配项返回 false;
2、exec()
从一个字符串中获取匹配项。
JavaScript 中的 string 对象有三个方法与正则表达式配合使用
1、match()
获取匹配项,与 exec()方法功能相同
2、search()
查找是否存在匹配项?与 test() 方法功能相同
3、replace() 有两个参数,
第一个参数是 RegExp 对象,
第二个参数是一个字符串,用来替换查找出来的匹配项
标签:
原文地址:http://www.cnblogs.com/bylion/p/5047069.html