标签:
K-means算法是最为经典的基于划分的聚类方法,是十大经典数据挖掘算法之一。K-means算法的基本思想是:以空间中k个点为中心进行聚类,对最靠近他们的对象归类。通过迭代的方法,逐次更新各聚类中心的值,直至得到最好的聚类结果。该算法接受参数 k ;然后将事先输入的n个数据对象划分为 k个聚类以便使得所获得的聚类满足:同一聚类中的对象相似度较高;而不同聚类中的对象相似度较小。聚类相似度是利用各聚类中对象的均值所获得一个“中心对象”(引力中心)来进行计算的。
算法描述:
,暂且抛开原始数据是什么形式,假设我们已经将其映射到了一个欧几里德空间上,映射到欧几里得空间上,样例:
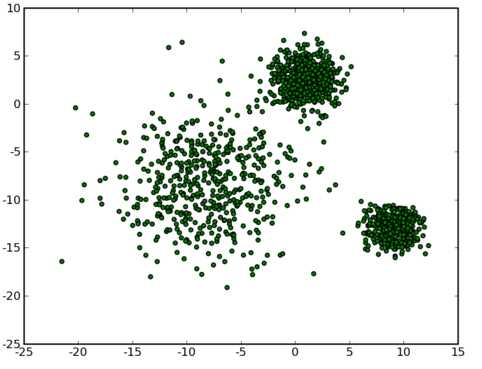
从数据点的大致形状可以看出它们大致聚为三个聚类 ,其中两个紧凑一些,剩下那个松散一些。我们的目的是为这些数据分组,以便能区分出属于不同的簇的数据,如果按照分组给它们标上不同的颜色,就是这个样子:
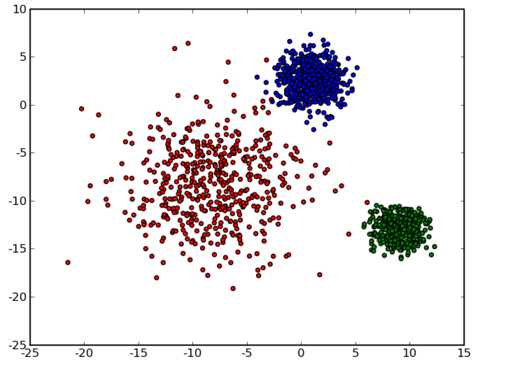
算法的流程:
首先从n个数据对象任意选择 k 个对象作为初始聚类中心;而对于所剩下其它对象,则根据它们与这些聚类中心的相似度(距离),分别将它们分配给与其最相似的(聚类中心所代表的)聚类;然后再计算每个所获新聚类的聚类中心(该聚类中所有对象的均值);不断重复这一过程直到标准测度函数开始收敛为止。一般都采用均方差作为标准测度函数. k个聚类具有以下特点:各聚类本身尽可能的紧凑,而各聚类之间尽可能的分开。
那么样例模板:

package main.asiainfo.coc.sparkMLlib
import org.apache.spark.mllib.clustering.KMeans
import org.apache.spark.mllib.linalg.Vectors
import org.apache.spark.{SparkConf, SparkContext}
/**
* Created by root on 12/15/15.
*/
object kmeans {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local").setAppName("cocapp")
val sc = new SparkContext(sparkConf)
// 装载数据集
val data = sc.textFile("/usr/local/spark-1.4.0-bin-2.5.0-cdh5.2.1/ysy.txt")
val parsedData = data.map(s => Vectors.dense(s.split(‘ ‘).map(_.toDouble)))
// 将数据集聚类,2个类,20次迭代,进行模型训练形成数据模型
val numClusters = 2
val numIterations = 20
val model = KMeans.train(parsedData, numClusters, numIterations)
// 打印数据模型的中心点
println("Cluster centers:")
for (c <- model.clusterCenters) {
println(" " + c.toString)
}
// 使用误差平方之和来评估数据模型
val cost = model.computeCost(parsedData)
println("Within Set Sum of Squared Errors = " + cost)
// 交叉评估1,只返回结果
val testdata = data.map(s => Vectors.dense(s.split(‘ ‘).map(_.toDouble)))
val result1 = model.predict(testdata)
result1.foreach(println)
println("-----------------------")
// 交叉评估2,返回数据集和结果
val result2 = data.map {
line =>
val linevectore = Vectors.dense(line.split(‘ ‘).map(_.toDouble))
val prediction = model.predict(linevectore)
line + " " + prediction
}
result2.foreach(println)
sc.stop()
}
}
数据模型的中心点:
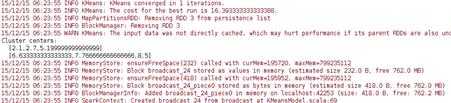
使用误差平方之和来评估数据模型:

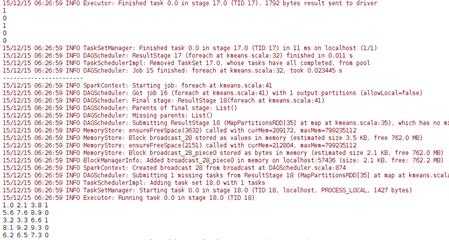
交叉评估1和2:
Kmeans算法学习与SparkMlLib Kmeans算法尝试
标签:
原文地址:http://www.cnblogs.com/yangsy0915/p/5049753.html