标签:
接上次的MemSQL分布式架构介绍(一),原文在这里:http://docs.memsql.com/latest/concepts/distributed_architecture/
1、MemSQL有两种类型的表:
注#官方文档里面说的这个query我理解为是增删改查操作,如理解有误,也请大家指出。
MemSQL在第一次执行一条query时将会编译这条语句并cache到内存中。
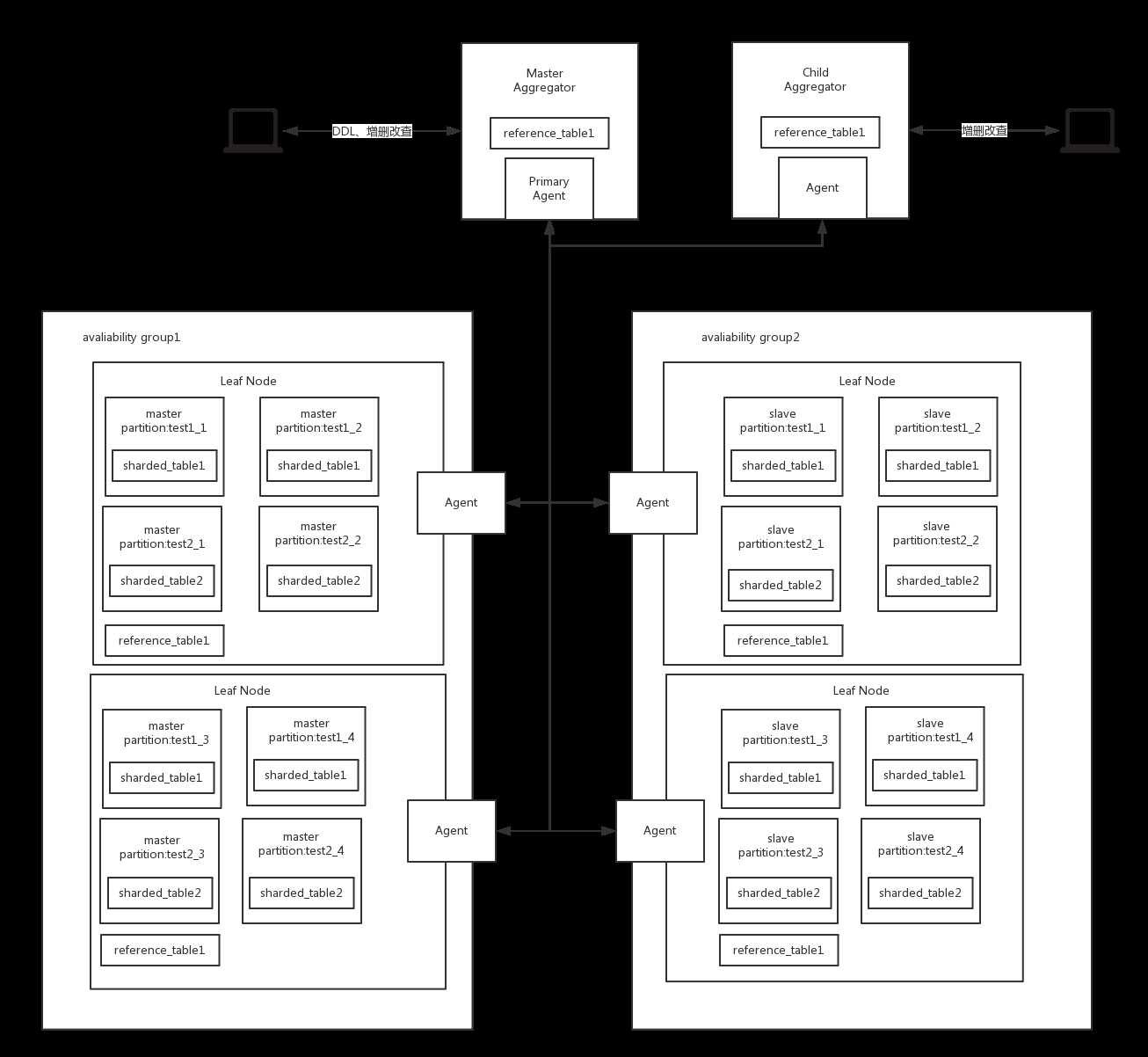
用户的query总是被指向一个汇聚器。DDL的操作或者向reference table写数据时必须通过主汇聚器,而其他的DML语句则可以通过任意的汇聚器。
只对reference table进行的query只会在汇聚器执行。汇聚器将不会发送这些query到叶子节点因为每一个汇聚器节点或者叶子节点都存有reference table的一个拷贝。
对sharded table进行的query包含更多:
一些query会有很多的query转换和汇聚逻辑,但他们都遵循了相同的通用流程。可以在一个query语句中使用EXPLAIN关键字来显示汇聚器和叶子节点之间的执行计划,包括将会发送到叶子节点的重写query。
MemSQL将会在分布表上通过每一行的主键哈希来分布数据(哈希分区表)。由于每个主键是唯一的同时hash函数一般又是统一的,所以集群能够相对均匀地分布数据和最小化数据倾斜(data skew)
在创建数据库的时候,MemSQL会拆分数据库到几个分区中。每个分区都有自己的哈希范围。你能够显式地指定分区数量通过PARTITIONS=X选项。默认的话分区的总数是叶子节点数的8倍。
每一个叶子节点上的分区是通过database实现的。当一个分布表被创建的时候,它会根据database的分区数量被拆分。这个表被保存于分区的数据切片中。二级索引是通过每个分区和每行主键作为唯一索引的前缀来被管理的。
如果你运行的一个query需要查找二级索引,那么汇聚器会fan out这个query到集群中的所有分区,每个分区都会去找这个二级索引。
精确匹配shard key的的Query将会被路由到一个单一的叶子节点(我的理解是insert语句或者可以确定hash值的增删改查语句,因为确定了hash值MemSQL就知道这条记录放在哪里了)。否则的话,汇聚器将会发送这个query到集群中并收集结果。你可以使用EXPLAIN关键字来测试创建的query,并查看叶子节点和query分布策略。
一个高可用组是叶子节点的集合,用于存储冗余数据以确保高可用。每一个高可用组包含了每一个分区的拷贝(一些为master而一些为slave)。目前,MemSQL只支持两个高可用组。你可以设置高可用组的数量通过redundancy_level变量在主汇聚器上。后面我们讨论的是redundancy-2的场景(有就是有两个高可用组的情况)。
每一个在高可用组的叶子节点都有对应的pair节点在其他的高可用组中。当有一个分区失效时,MemSQL将会自动将这个分区的slave分区提升为master分区。
标签:
原文地址:http://www.cnblogs.com/caozhangni/p/5051920.html