标签:
XML:指可扩展标记语言, Extensible Markup Language;类似HTML。XML的设计宗旨是传输数据,而非显示数据。
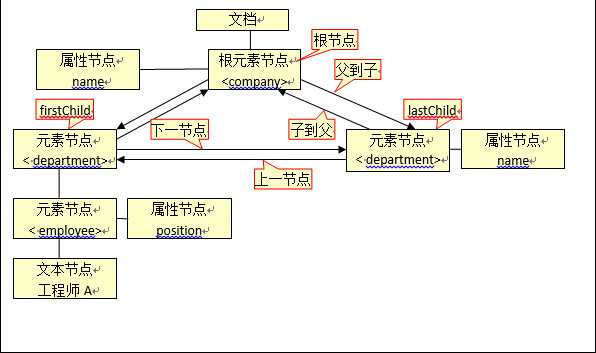
一个xml文档实例:
1 <?xml version="1.0" encoding="UTF-8"?> 2 <company name="Tencent" address="深圳市南山区"> 3 <department deptNo="001" name="development"> 4 <employee id="devHead" position="minister">许刚</employee> 5 <employee position="developer">工程师A</employee> 6 </department> 7 <department deptNo="002" name="education"> 8 <employee position="minister" telephone="1234567">申林</employee> 9 <employee position="trainee">实习生A</employee> 10 </department> 11 </company>
第一行是 XML 声明。它定义 XML 的版本 (1.0) 和所使用的编码.
下一行描述文档的根元素:<company>开始,该根元素具有2个属性“name”,"address"。
最后一行定义根元素的结尾。</company>。
· XML 文档形成一种树结构
· XML 文档必须包含根元素。该元素是所有其他元素的父元素。
· XML 文档中的元素形成了一棵文档树。这棵树从根部开始,并扩展到树的最底端。
所有元素均可拥有子元素:
1 <root> 2 3 <child> 4 5 <subchild>.....</subchild> 6 7 </child> 8 9 </root>
父、子以及同胞等术语用于描述元素之间的关系。父元素拥有子元素。相同层级上的子元素成为同胞(兄弟或姐妹)。
节点:XML文档中的所有节点组成了一个文档树(或节点树)。XML文档中的每个元素、属性、文本等都代表着树中的一个节点。树起始于文档节点,并由此继续伸出枝条,直到处于这棵树最低级别的所有文本节点为止,常用节点类型如下表所示:
|
节点类型 |
附加说明 |
实例 |
|
元素节点(Element) |
XML标记元素 |
<company>…</company> |
|
属性节点(Attribute) |
XML标记元素的属性 |
name=”Tencent” |
|
文本节点(Text) |
包括在XML标记中的文本段 |
工程师A |
|
文档类型节点(DocumentType) |
文档类型声明 |
﹤!DOCTYPE…﹥ |
|
注释节点Comment |
XmlComment类注释节点。 |
<!—文档注释-> |
通过上面的XML文档,我们构建出如下树状文档对象模型:
1 <?xml version="1.0" encoding="UTF-8"?> 2 <bookstore> 3 <book category="COOKING"> 4 <title lang="en">Everyday Italian</title> 5 <author>Giada De Laurentiis</author> 6 <year>2005</year> 7 <price>30.00</price> 8 </book> 9 <book category="CHILDREN"> 10 <title lang="en">Harry Potter</title> 11 <author>J K. Rowling</author> 12 <year>2005</year> 13 <price>29.99</price> 14 </book> 15 <book category="WEB"> 16 <title lang="en">Learning XML</title> 17 <author>Erik T. Ray</author> 18 <year>2003</year> 19 <price>39.95</price> 20 </book> 21 </bookstore>
再如上例xml文档:
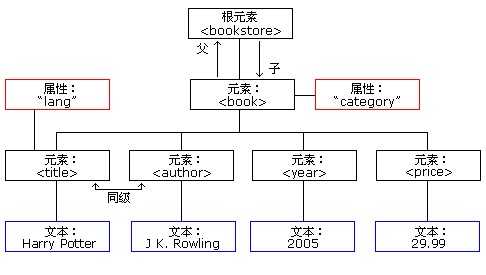
例子中的根元素是 <bookstore>。文档中的所有 <book> 元素都被包含在 <bookstore> 中。<book> 元素有 4 个子元素:<title>、< author>、<year>、<price>。
a). XML 的属性值须加引号。
· 与 HTML 类似,XML 也可拥有属性(名称/值的对)。
· 在 XML 中,XML 的属性值须加引号。
b). XML 文档必须有根元素.XML 文档必须有一个元素是所有其他元素的父元素。该元素称为根元素。
c). XML 标签对大小写敏感.
· XML 元素使用 XML 标签进行定义。
· XML 标签对大小写敏感。在 XML 中,标签 <Letter> 与标签 <letter> 是不同的。必须使用相同的大小写来编写打开标签和关闭标签。
d). XML 中的注释语法:
<!-- This is a comment -->
e). XML 元素 vs. 属性
1 <person sex="female"> 2 <firstname>Anna</firstname> 3 <lastname>Smith</lastname> 4 </person> 5 6 <person> 7 <sex>female</sex> 8 <firstname>Anna</firstname> 9 <lastname>Smith</lastname> 10 </person>
在第一行中,sex 是一个属性。在第7行中,sex 则是一个子元素。两个例子均可提供相同的信息。
xml解析方法有四种:
· DOM(JAXP Crimson 解析器):W3C为HTML和XML分析器制定的标准接口规范,基于树,可随机动态访问和更新文档的内容、结构、样式。
· SAX(simple API for XML):不是W3C的标准,而是由XML-DEV邮件列表成员于1998年为Java语言开发的一种基于事件的简单API。基于事件,逐行解析,顺序访问XML文档,速度快,处理功能简单。
· JDOM:鉴于DOM的低效率,而SAX又不能随机处理XML文档,Jason Hunter与Brett McLaughlin于2000年春天,开始创建一种能充分体现两者优势的API——JDOM(Java-based DOM,基于Java的DOM),它是一个基于Java的对象模型,树状结构,能使读取、操作和写入XML文档,比DOM更高效,比SAX更强大,但由于使用了大量的类而不使用接口导致灵活性降低。
· DOM4J:DOM4J是一个易用的,开源的库,用于XML,XPath,XSLT。它应用于Java平台,采用了Java集合框架并完全支持DOM,SAX,JAXP。它提供了大量的接口,因此比JDOM更具有灵活性。
DOM(Document Object Model文档对象模型),是W3C为HTML和XML分析器制定的标准接口规范。
特点:独立于语言,跨平台(可以在各种编程和脚本语言中使用),需要将整个文档读入内存,在内存中创建文档树,可随即访问文档中的特定节点,对内存的要求比较高,经过测试,访问速度相对于其他解析方式较慢,适用于简单文档的随即处理。
常用的节点属性:
|
属性 |
描述 |
|
nodeName |
结点名称 |
|
nodeValue |
结点内部值,通常只应用于文本结点 |
|
nodeType |
节点类型对应的数字 |
|
parentNode |
如果存在,指向当前结点的父亲结点 |
|
childNodes |
子结点列表 |
|
firstChild |
如果存在,指向当前元素的第一个子结点 |
|
lastChild |
如果存在,指向当前元素的最后一个子结点 |
|
previousSibling |
指向当前结点的前一个兄弟结点 |
|
nextSibling |
指向当前结点的后一个兄弟结点 |
|
attributes |
元素的属性列表 |
常用的节点方法:
|
操作类型 |
方法原型 |
描述 |
|
访问节点 |
getElementById(id) |
根据ID属性查找元素节点 |
|
getElementsByName(name) |
根据name属性查找元素集 |
|
|
getElementsByTagName(tagName) |
根据元素标记名称查找元素集 |
|
|
创建节点 |
createElement(tagName) |
创建元素节点 |
|
createTestNode(string) |
创建文本节点 |
|
|
createAttribute(name) |
创建属性节点 |
|
|
插入和添加节点 |
appendChild(newChild) |
添加子节点到目标节点上 |
|
insertBefore(newChild,targetChild) |
将newChild节点插入到targetChild节点之前 |
|
|
复制节点 |
CloneNode(bool) |
复制该节点,由bool确定是否复制子节点 |
|
删除和替换节点 |
removeChild(childName) |
删除由childName指定的节点 |
|
replaceChild(newChild,oldChild) |
用newChild替换oldChild |
|
|
属性节点操作 |
getAttribute(name) |
返回目标对象指定属性名称为name的属性值 |
|
setAttribute(name,value) |
修改目标节点指定属性名称为name的属性值为value |
|
|
removeAttribute(name) |
删除目标节点指定属性名称为name的属性 |
(1)读取本地xml文档解析为对象的步骤:
* 首先利用DocumentBuilderFactory创建一个DocumentBuilderFactory实例;然后利用DocumentBuilderFactory创建DocumentBuilder
//创建DocumentBuilderFactory工厂实例。
DocumentBuilderFactory dbfactory = DocumentBuilderFactory.newInstance();
//通过文档创建工厂创建文档创建器
DocumentBuilder dBuilder = dbfactory.newDocumentBuilder();
* 然后加载XML文档(Document) : 通过文档创建器DocumentBuilder的parse方法解析参数URL指定的XML文档,并返回一个Document 对象。
Document doc = dBuilder.parse(url);
* 然后获取文档的根结点(Element),
* 然后获取根结点中所有子节点的列表(NodeList),
* 然后使用再获取子节点列表中的需要读取的结点。
实例:
books.xml:
1 <?xml version="1.0" encoding="UTF-8"?> 2 <bookstore> 3 <book category="COOKING"> 4 <title lang="en">Everyday Italian</title> 5 <author>Giada De Laurentiis</author> 6 <year>2005</year> 7 <price>30.0</price> 8 </book> 9 <book category="CHILDREN"> 10 <title lang="en">Harry Potter</title> 11 <author>J K. Rowling</author> 12 <year>2005</year> 13 <price>29.99</price> 14 </book> 15 <book category="WEB"> 16 <title lang="en">Learing XML</title> 17 <author>Erik T. Ray</author> 18 <year>2010</year> 19 <price>48.99</price> 20 </book> 21 </bookstore>
Books抽象类:
1 package demo; 2 3 /** 4 * 根据xml “books”文档,新创建Books类 5 * Created by luts on 2015/12/18. 6 */ 7 public class Books { 8 private String category; 9 private String title; 10 private String language; 11 private String author; 12 private String year; 13 private String price; 14 15 public String getCategory() { 16 return category; 17 } 18 19 public void setCategory(String category) { 20 this.category = category; 21 } 22 23 public String getTitle() { 24 return title; 25 } 26 27 public void setTitle(String title) { 28 this.title = title; 29 } 30 31 public String getLanguage() { 32 return language; 33 } 34 35 public void setLanguage(String language) { 36 this.language = language; 37 } 38 39 public String getAuthor() { 40 return author; 41 } 42 43 public void setAuthor(String author) { 44 this.author = author; 45 } 46 47 public String getYear() { 48 return year; 49 } 50 51 public void setYear(String year) { 52 this.year = year; 53 } 54 55 public String getPrice() { 56 return price; 57 } 58 59 public void setPrice(String price) { 60 this.price = price; 61 } 62 }
DOM解析:
1 package demo; 2 3 import org.w3c.dom.*; 4 import org.xml.sax.SAXException; 5 6 import javax.xml.parsers.DocumentBuilder; 7 import javax.xml.parsers.DocumentBuilderFactory; 8 import javax.xml.parsers.ParserConfigurationException; 9 import java.awt.print.Book; 10 import java.io.FileNotFoundException; 11 import java.io.IOException; 12 import java.util.ArrayList; 13 import java.util.List; 14 15 /** 16 * Created by luts on 2015/12/18. 17 */ 18 public class DOMTest { 19 public static void main(String[] args){ 20 21 List<Books> books = new ArrayList<Books>(); 22 23 Books book = null; 24 25 try { 26 DocumentBuilderFactory dbFactory = DocumentBuilderFactory.newInstance(); 27 DocumentBuilder dBuilder = dbFactory.newDocumentBuilder(); 28 Document document = dBuilder.parse("src/books.xml"); 29 //找到根节点 30 Element root = document.getDocumentElement(); 31 32 System.out.println("------开始解析-------"); 33 NodeList booksList = root.getElementsByTagName("book"); 34 System.out.println("一共有" + booksList.getLength() + "本书"); 35 //遍历book节点的所有节点 36 for (int i = 0; i < booksList.getLength(); i++){ 37 book = new Books(); 38 39 System.out.println("-----现在开始遍历第" +(i + 1) + "本书的内容-----"); 40 //通过item(i)方法获取一个book节点 41 Node nodeBook = booksList.item(i); 42 //获取book节点的所有属性集合 43 NamedNodeMap attrs = nodeBook.getAttributes(); 44 System.out.println("第" + (i + 1) + "本书有"+ attrs.getLength() + "个属性"); 45 46 //遍历book属性 47 for (int j = 0; j < attrs.getLength(); j++){ 48 //通过item(index)方法获取book节点的某一个属性 49 Node attr = attrs.item(j); 50 //获取属性名和属性值 51 System.out.println("属性名:" + attr.getNodeName() + ", 属性值:" + attr.getNodeValue()); 52 book.setCategory(attr.getNodeValue()); 53 54 } 55 56 57 /* 58 //如果book节点有且只有一个category属性,可以通过将book节点进行强制类型转换,转换成Element类型。 59 Element bookElement = (Element) booksList.item(i); 60 //通过getAttribute("category") 61 String attrVaule = bookElement.getAttribute("category"); 62 System.out.println("category的属性值为" + attrVaule); 63 */ 64 65 //解析book节点的子节点 66 NodeList bookchildNode = nodeBook.getChildNodes(); 67 //遍历bookchildNode获取每个节点的节点名和节点值 68 System.out.println("第" + (i +1) + "本书共有" + bookchildNode.getLength() + "个子节点"); 69 70 for (int k = 0; k < bookchildNode.getLength(); k++){ 71 72 //区分text类型的node和element类型的node 73 if (bookchildNode.item(k).getNodeType() == Node.ELEMENT_NODE){ 74 //获取element类型的节点 75 System.out.println("\t第" + (k+1)+ "个节点的节点名:" + bookchildNode.item(k).getNodeName()); 76 //获取element类型的节点值 77 System.out.println("\t节点值:" + bookchildNode.item(k).getFirstChild().getNodeValue()); 78 // System.out.println("--节点值是:" + bookchildNode.item(k).getTextContent()); 79 80 if(bookchildNode.item(k).getNodeName().equals("title")){ 81 book.setTitle(bookchildNode.item(k).getFirstChild().getNodeValue()); 82 Element nodeLang = (Element) (bookchildNode.item(k)); 83 String lang = nodeLang.getAttribute("lang"); 84 book.setLanguage(lang); 85 86 } 87 88 if(bookchildNode.item(k).getNodeName().equals("author")){ 89 book.setAuthor(bookchildNode.item(k).getFirstChild().getNodeValue()); 90 } 91 92 if(bookchildNode.item(k).getNodeName().equals("year")){ 93 book.setYear(bookchildNode.item(k).getFirstChild().getNodeValue()); 94 } 95 96 if(bookchildNode.item(k).getNodeName().equals("price")){ 97 book.setPrice(bookchildNode.item(k).getFirstChild().getNodeValue()); 98 } 99 100 } 101 } 102 103 books.add(book); 104 System.out.println("-----结束遍历第" + (i+1)+"本书的内容------"); 105 106 } 107 System.out.println("------解析完毕!------"); 108 } 109 catch (FileNotFoundException e){ 110 System.out.println(e.getMessage()); 111 }catch (ParserConfigurationException e){ 112 System.out.println(e.getMessage()); 113 }catch (SAXException e){ 114 System.out.println(e.getMessage()); 115 }catch (IOException e){ 116 System.out.println(e.getMessage()); 117 } 118 119 //输出bookList中的book 120 for(int m = 0; m < books.size(); m++){ 121 System.out.println("总共有" + books.size() + "本书"); 122 Books bookElemntTemp = (Books)books.get(m); 123 System.out.println("第"+(m + 1) + "本书的分类:" + bookElemntTemp.getCategory() + ", 作者:" + bookElemntTemp.getAuthor() + "语言: " +bookElemntTemp.getLanguage()); 124 125 } 126 } 127 128 129 130 }
结果:

标签:
原文地址:http://www.cnblogs.com/luts/p/5055495.html