标签:
\w Matches any word character.
\W Matches any non-word character.
如果是在java中的话,需要双引号 \\w 才可以;而且这里需要注意大小写区分
\s 是代表空格
The * character is a quantifier that means "zero or more times".
There is also a + quantifier meaning "one or more times",
a ? quantifier meaning "zero or one time",
Chinese and Japanese don‘t use the regular space character ‘ ‘. The languages use their own that is the same width as the characters. This is the character here ‘ ‘, you should write a manual trim function to check for that character at the beginning and end of the string.
You may be able to directly use the character if you convert your code file to unicode (if java will allow). Otherwise you will need to find the unicode character code for ‘ ‘ and check if the character code is at the beginning or end of the string.
The following link tells us that the ideographic space is 0xe38080 in UTF-8 and 0x3000 in UTF-16, and that Java‘s Character.isSpaceChar() function will return true. I would have thought String.trim() would have used this property to determine whether or not to trim though.
然后比如给定一个汉字,返回编码gurva
》》》》在Java中,String的getBytes()方法是得到一个操作系统默认的编码格式的字节数组。这个表示在不通OS下,返回的东西不一样!(所以不建议使用)
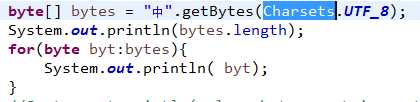
》》》》String.getBytes(String decode)方法会根据指定的decode编码返回某字符串在该编码下的byte数组表示,注意这个编码decode写的时候注意Charsets.UTF_8
如
byte[] b_gbk = "中".getBytes("GBK");
byte[] b_utf8 = "中".getBytes("UTF-8");
byte[] b_iso88591 = "中".getBytes("ISO8859-1");
将分别返回“中”这个汉字在GBK、UTF-8和ISO8859-1编码下的byte数组表示,此时b_gbk的长度为2,b_utf8的长度为3,b_iso88591的长度为1。
而与getBytes相对的,可以通过new String(byte[], decode)的方式来还原这个“中”字时,这个new
String(byte[], decode)实际是使用decode指定的编码来将byte[]解析成字符串。
String s_gbk = new String(b_gbk,"GBK");
String s_utf8 = new String(b_utf8,"UTF-8");
String s_iso88591 = new String(b_iso88591,"ISO8859-1");
标签:
原文地址:http://www.cnblogs.com/amazement/p/5057675.html