标签:
最近在做一个分布式调用链跟踪系统,
在两个地方采用了flume ,一个是宿主系统 ,用flume agent进行日志搜集。 一个是从kafka拉日志分析后写入hbase.
后面这个flume(从kafka拉日志分析后写入flume)用了3台 , 系统上线以后 ,线上抛了一个这样的异常:
Caused by: org.apache.flume.ChannelException: Put queue for MemoryTransaction of capacity 100 full, consider committing more frequently, increasing capacity or increasing thread count
at org.apache.flume.channel.MemoryChannel$MemoryTransaction.doPut(MemoryChannel.java:84)
at org.apache.flume.channel.BasicTransactionSemantics.put(BasicTransactionSemantics.java:93)
at org.apache.flume.channel.BasicChannelSemantics.put(BasicChannelSemantics.java:80)
at org.apache.flume.channel.ChannelProcessor.processEventBatch(ChannelProcessor.java:189)
从异常信息直观理解是MemoryChannel的事务的Put队列满了,为什么会这样呢?
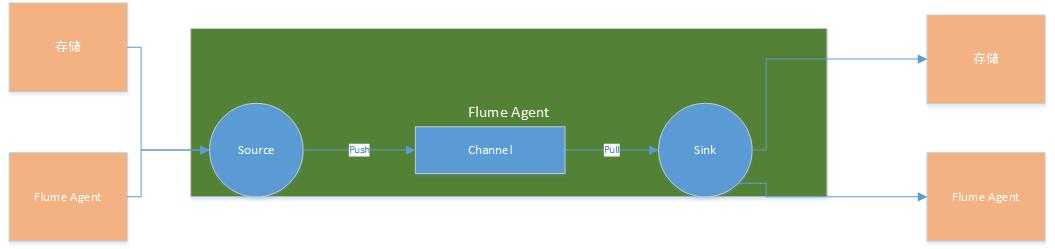
我们先从Flume的体系结构说起,Flume是apache一个负责日志采集和传输的开源工具,它的特点是能够很灵活的通过配置实现不同数据存储之间的数据转换,通过简单的agent还能实现一个日志搜集平台(后面另写文章来进行总结),
它有三个最主要的组件:
Source : 负责从数据源获取数据,包含两种类型的Source . EventDrivenSource 和 PollableSource , 前者指的是事件驱动型数据源,故名思议,就是需要外部系统主动送数据 ,比如AvroSource ,ThriftSource ; 而PollableSource 指的是需要主动从数据源拉取数据 ,比如KafkaSource ,Source 获取到数据以后向Channel 写入Event, Flume的 Event包含headers和body两部分,前者是键值对组成的Map .
Sink : 负责从Channel拉取Event , 写入下游存储或者对接其他Agent.
Channel:用于实现Source和Sink之间的数据缓冲, 主要有文件通道和内存通道两类。
Flume的架构图如下:
而我的flume 配置如下:
a1.sources = kafkasource
a1.sinks = hdfssink hbasesink
a1.channels = hdfschannel hbasechannel
a1.sources.kafkasource.channels = hdfschannel hbasechannel
a1.sinks.hdfssink.channel = hdfschannel
a1.sinks.hbasesink.channel = hbasechannel
a1.sources.kafkasource.type = org.apache.flume.source.kafka.KafkaSource
a1.sources.kafkasource.zookeeperConnect = zk1:2181,zk2:2181,zk3:2181
a1.sources.kafkasource.topic = nagual_topic
a1.sources.kafkasource.groupId = flume
a1.sources.kafkasource.kafka.consumer.timeout.ms = 500
a1.sinks.hdfssink.type = hdfs
a1.sinks.hdfssink.hdfs.path = hdfs://namenode:8020/flume/kafka_events/%y-%m-%d/%H%M
a1.sinks.hdfssink.hdfs.filePrefix = events-prefix
a1.sinks.hdfssink.hdfs.round = true
a1.sinks.hdfssink.hdfs.roundValue = 10
a1.sinks.hdfssink.hdfs.roundUnit = minute
a1.sinks.hdfssink.hdfs.fileType = SequenceFile
a1.sinks.hdfssink.hdfs.writeFormat = Writable
a1.sinks.hdfssink.hdfs.rollInterval = 60
a1.sinks.hdfssink.hdfs.rollCount = -1
a1.sinks.hdfssink.hdfs.rollSize = -1
a1.sinks.hbasesink.type = hbase
a1.sinks.hbasesink.table = htable_nagual_tracelog
a1.sinks.hbasesink.index_table = htable_nagual_tracelog_index
a1.sinks.hbasesink.serializer =NagualTraceLogEventSerializer
a1.sinks.hbasesink.columnFamily = rpcid
a1.sinks.hbasesink.zookeeperQuorum = zk1:2181,zk2:2181,zk3:2181
a1.channels.hdfschannel.type = memory
a1.channels.hdfschannel.capacity= 10000
a1.channels.hdfschannel.byteCapacityBufferPercentage = 20
a1.channels.hdfschannel.byteCapacity = 536870912
也就是说我的flume agent从kafka拉取日志以后,转换成hbase 的row put操作,中间采用了memchannel , 为什么会出现之前提到的异常呢?花了一个下午的时间,对flume的源码通读了一遍, 基本找到了问题所在 。
我们把源码拆解成以下几个主要步骤来分析:
1、flume 的启动:

如上图所示, 整个flume 启动的主要流程是这样的:
flume_home中的flume-ng启动脚本启动Application , Application创建一个PollingPropertiesFileConfigurationProvider, 这个Provider的作用是启动 一个配置文件的监控线程FileWatcherRunnable ,定时监控配置文件的变更,
一旦配置文件变更,则重新得到SinkRunner, SourceRunner以及channel的配置, 包装成MaterialedConfiguration,通过google guava的eventbus 推送配置变更给Application ,Application启动一个LifeCycleSupervisor,由它来负责监控
SourceRunner ,SinkRunner,Channel的运行情况。而这几个用绿框标识的组件都实现或者继承了LifeCycleAware接口,监控的方式有点意思:通过定时检查这些组件的期望Status是否和当前Status一致, 如果不一致则调用Status对应的方法。
比如在启动的时候,期望SinkRunner的状态是Running ,则调用SinkRunner的Start方法。
启动的顺序是Channel -> SinkRunner -> SourceRunner ( 形象的理解为先有水管,再有水盆, 再开水龙头。)
以我的flume配置文件为例, 使用了MemChannel 。在AbstractConfigurationProvider 配置阶段,会创建好一个LinkedBlockingDeque ( 这个队列是一个全局唯一的有最大长度的双端队列), 而在AbstractConfigurationProvider创建Channel的时候,一种类型的通道又只会被创建一次(具体可以看AbstractConfigurationProvider的getOrCreateChannel方法) ,所以我们也可以理解为什么在Flume的memory channel配置中关于byteCapacity的配置参数会有这么一句话:
Note that if you have multiple memory channels on a single JVM, and they happen to hold the same physical events
也就是说即使配置了多个内存通道, 也共享的是一个双端队列。
未完,待续。
标签:
原文地址:http://www.cnblogs.com/dongqingswt/p/5070776.html