标签:
选择排序,包括“直接选择排序”和“堆排序”。
上次我们对比了冒泡排序和快速排序。由于算法不一样,效率也完全不一样。可以快排有他得天独厚的优势。
今天我们再来看一下直接选择排序,让他跟堆排序进行一次VS ,也让我们也感受一下他们的优劣。
1.直接选择排序:
先上图:
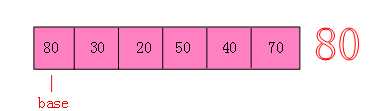
说实话,直接选择排序最类似于人的本能思想,比如把大小不一的玩具让三岁小毛孩对大小排个序,
那小孩首先会在这么多玩具中找到最小的放在第一位,然后找到次小的放在第二位,以此类推。。。。。。
小孩子多聪明啊,这么小就知道了直接选择排序。
对的,小孩子给我们上了一课,
第一步: 我们拿80作为参照物(base),在80后面找到一个最小数20,然后将80跟20交换。
第二步: 第一位数已经是最小数字了,然后我们推进一步在30后面找一位最小数,发现自己最小,不用交换。
第三步:........
最后我们排序完毕。大功告成。
C++ 源程序:
1 #include<iostream> 2 #include <ctime> //使用了time() 函数 3 #include <cstdlib> //使用了srand()函数 4 5 const int N=20005; 6 int a[N]; 7 using namespace std; 8 9 //选择排序 10 void SelectionSort(int *a,int n) 11 { 12 //要遍历的次数 13 for (int i = 1; i < n; i++) 14 { 15 //假设tempIndex的下标的值最小 16 int tempIndex = i; 17 18 for (int j = i + 1; j <= n; j++) 19 { 20 //如果tempIndex下标的值大于j下标的值,则记录较小值下标j 21 if (a[tempIndex] > a[j]) 22 tempIndex = j; 23 } 24 25 //最后将假想最小值跟真的最小值进行交换 26 int tempData = a[tempIndex]; 27 a[tempIndex] = a[i]; 28 a[i] = tempData; 29 } 30 return ; 31 } 32 33 int main() 34 { 35 //随机产生n个数存入数组a中 36 int n=21000; 37 srand(int(time(0))); //利用时间函数time(),产生每次不同的随机数种子 38 for(int i=1;i<=n;i++) a[i]=rand(); //随机产生3000个数存于数组a中 (从1开始) 39 clock_t start = clock(); 40 SelectionSort(a,n); //对数组a进行排序(从1开始) 41 clock_t end = clock(); 42 for(int i=1;i<=20;i++) cout<<a[i]<<‘ ‘; //输出前20个数据(已从小到大排序) 43 cout<<endl<<"冒泡排序耗时为:"<<end-start<<"ms"<<endl; 44 return 0; 45 }
经我亲测在1秒中之内,可排序的数据为21000个,原因为选择排序的时间复杂度为O(n2),因此只能排21000个数据,要想排序次数超过万级,就必须更换成新的排序方法。发现选择排序略比冒泡快一点点,时间复杂度为一样,为何,比较次数是一样的,但移动的次数却少了。见程序。故快一点点,实际中这一点点是可忽略的。还是采用其他方法,才能解决十万百万级。
标签:
原文地址:http://www.cnblogs.com/jjzzx/p/5071316.html