标签:
Spark SQL是Spark的一个组件,用于结构化数据的计算。Spark SQL提供了一个称为DataFrames的编程抽象,DataFrames可以充当分布式SQL查询引擎。
DataFrame是一个分布式的数据集合,该数据集合以命名列的方式进行整合。DataFrame可以理解为关系数据库中的一张表,也可以理解为R/Python中的一个data frame。DataFrames可以通过多种数据构造,例如:结构化的数据文件、hive中的表、外部数据库、Spark计算过程中生成的RDD等。
DataFrame的API支持4种语言:Scala、Java、Python、R。
Spark SQL程序的主入口是SQLContext类或它的子类。创建一个基本的SQLContext,你只需要SparkContext,创建代码示例如下:
val sc: SparkContext // An existing SparkContext.
val sqlContext = new org.apache.spark.sql.SQLContext(sc)JavaSparkContext sc = ...; // An existing JavaSparkContext.
SQLContext sqlContext = new org.apache.spark.sql.SQLContext(sc);除了基本的SQLContext,也可以创建HiveContext。SQLContext和HiveContext区别与联系为:
HiveContext包装了Hive的依赖包,把HiveContext单独拿出来,可以在部署基本的Spark的时候就不需要Hive的依赖包,需要使用HiveContext时再把Hive的各种依赖包加进来。
SQL的解析器可以通过配置spark.sql.dialect参数进行配置。在SQLContext中只能使用Spark SQL提供的”sql“解析器。在HiveContext中默认解析器为”hiveql“,也支持”sql“解析器。
使用SQLContext,spark应用程序(Application)可以通过RDD、Hive表、JSON格式数据等数据源创建DataFrames。下面是基于JSON文件创建DataFrame的示例:
val sc: SparkContext // An existing SparkContext.
val sqlContext = new org.apache.spark.sql.SQLContext(sc)
val df = sqlContext.read.json("examples/src/main/resources/people.json")
// Displays the content of the DataFrame to stdout
df.show()JavaSparkContext sc = ...; // An existing JavaSparkContext.
SQLContext sqlContext = new org.apache.spark.sql.SQLContext(sc);
DataFrame df = sqlContext.read().json("examples/src/main/resources/people.json");
// Displays the content of the DataFrame to stdout
df.show();
DataFrames支持Scala、Java和Python的操作接口。下面是Scala和Java的几个操作示例:
val sc: SparkContext // An existing SparkContext.
val sqlContext = new org.apache.spark.sql.SQLContext(sc)
// Create the DataFrame
val df = sqlContext.read.json("examples/src/main/resources/people.json")
// Show the content of the DataFrame
df.show()
// age name
// null Michael
// 30 Andy
// 19 Justin
// Print the schema in a tree format
df.printSchema()
// root
// |-- age: long (nullable = true)
// |-- name: string (nullable = true)
// Select only the "name" column
df.select("name").show()
// name
// Michael
// Andy
// Justin
// Select everybody, but increment the age by 1
df.select(df("name"), df("age") + 1).show()
// name (age + 1)
// Michael null
// Andy 31
// Justin 20
// Select people older than 21
df.filter(df("age") > 21).show()
// age name
// 30 Andy
// Count people by age
df.groupBy("age").count().show()
// age count
// null 1
// 19 1
// 30 1JavaSparkContext sc // An existing SparkContext.
SQLContext sqlContext = new org.apache.spark.sql.SQLContext(sc)
// Create the DataFrame
DataFrame df = sqlContext.read().json("examples/src/main/resources/people.json");
// Show the content of the DataFrame
df.show();
// age name
// null Michael
// 30 Andy
// 19 Justin
// Print the schema in a tree format
df.printSchema();
// root
// |-- age: long (nullable = true)
// |-- name: string (nullable = true)
// Select only the "name" column
df.select("name").show();
// name
// Michael
// Andy
// Justin
// Select everybody, but increment the age by 1
df.select(df.col("name"), df.col("age").plus(1)).show();
// name (age + 1)
// Michael null
// Andy 31
// Justin 20
// Select people older than 21
df.filter(df.col("age").gt(21)).show();
// age name
// 30 Andy
// Count people by age
df.groupBy("age").count().show();
// age count
// null 1
// 19 1
// 30 1详细的DataFrame API请参考 API Documentation。
除了简单列引用和表达式,DataFrames还有丰富的library,功能包括string操作、date操作、常见数学操作等。详细内容请参考 DataFrame Function Reference。
Spark Application可以使用SQLContext的sql()方法执行SQL查询操作,sql()方法返回的查询结果为DataFrame格式。代码如下:
val sqlContext = ... // An existing SQLContext
val df = sqlContext.sql("SELECT * FROM table")SQLContext sqlContext = ... // An existing SQLContext
DataFrame df = sqlContext.sql("SELECT * FROM table")
Spark SQL支持两种RDDs转换为DataFrames的方式:
Spark SQL支持将JavaBean的RDD自动转换成DataFrame。通过反射获取Bean的基本信息,依据Bean的信息定义Schema。当前Spark SQL版本(Spark 1.5.2)不支持嵌套的JavaBeans和复杂数据类型(如:List、Array)。创建一个实现Serializable接口包含所有属性getters和setters的类来创建一个JavaBean。通过调用createDataFrame并提供JavaBean的Class object,指定一个Schema给一个RDD。示例如下:
public static class Person implements Serializable {
private String name;
private int age;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
}// sc is an existing JavaSparkContext.
SQLContext sqlContext = new org.apache.spark.sql.SQLContext(sc);
// Load a text file and convert each line to a JavaBean.
JavaRDD<Person> people = sc.textFile("examples/src/main/resources/people.txt").map(
new Function<String, Person>() {
public Person call(String line) throws Exception {
String[] parts = line.split(",");
Person person = new Person();
person.setName(parts[0]);
person.setAge(Integer.parseInt(parts[1].trim()));
return person;
}
});
// Apply a schema to an RDD of JavaBeans and register it as a table.
DataFrame schemaPeople = sqlContext.createDataFrame(people, Person.class);
schemaPeople.registerTempTable("people");
// SQL can be run over RDDs that have been registered as tables.
DataFrame teenagers = sqlContext.sql("SELECT name FROM people WHERE age >= 13 AND age <= 19")
// The results of SQL queries are DataFrames and support all the normal RDD operations.
// The columns of a row in the result can be accessed by ordinal.
List<String> teenagerNames = teenagers.javaRDD().map(new Function<Row, String>() {
public String call(Row row) {
return "Name: " + row.getString(0);
}
}).collect();
当JavaBean不能被预先定义的时候,编程创建DataFrame分为三步:
示例如下:
import org.apache.spark.api.java.function.Function;
// Import factory methods provided by DataTypes.
import org.apache.spark.sql.types.DataTypes;
// Import StructType and StructField
import org.apache.spark.sql.types.StructType;
import org.apache.spark.sql.types.StructField;
// Import Row.
import org.apache.spark.sql.Row;
// Import RowFactory.
import org.apache.spark.sql.RowFactory;
// sc is an existing JavaSparkContext.
SQLContext sqlContext = new org.apache.spark.sql.SQLContext(sc);
// Load a text file and convert each line to a JavaBean.
JavaRDD<String> people = sc.textFile("examples/src/main/resources/people.txt");
// The schema is encoded in a string
String schemaString = "name age";
// Generate the schema based on the string of schema
List<StructField> fields = new ArrayList<StructField>();
for (String fieldName: schemaString.split(" ")) {
fields.add(DataTypes.createStructField(fieldName, DataTypes.StringType, true));
}
StructType schema = DataTypes.createStructType(fields);
// Convert records of the RDD (people) to Rows.
JavaRDD<Row> rowRDD = people.map(
new Function<String, Row>() {
public Row call(String record) throws Exception {
String[] fields = record.split(",");
return RowFactory.create(fields[0], fields[1].trim());
}
});
// Apply the schema to the RDD.
DataFrame peopleDataFrame = sqlContext.createDataFrame(rowRDD, schema);
// Register the DataFrame as a table.
peopleDataFrame.registerTempTable("people");
// SQL can be run over RDDs that have been registered as tables.
DataFrame results = sqlContext.sql("SELECT name FROM people");
// The results of SQL queries are DataFrames and support all the normal RDD operations.
// The columns of a row in the result can be accessed by ordinal.
List<String> names = results.javaRDD().map(new Function<Row, String>() {
public String call(Row row) {
return "Name: " + row.getString(0);
}
}).collect();
Spark SQL的DataFrame接口支持多种数据源的操作。一个DataFrame可以进行RDDs方式的操作,也可以被注册为临时表。把DataFrame注册为临时表之后,就可以对该DataFrame执行SQL查询。Data Sources这部分首先描述了对Spark的数据源执行加载和保存的常用方法,然后对内置数据源进行深入介绍。
Spark SQL的默认数据源为Parquet格式。数据源为Parquet文件时,Spark SQL可以方便的执行所有的操作。修改配置项spark.sql.sources.default,可修改默认数据源格式。读取Parquet文件示例如下:
val df = sqlContext.read.load("examples/src/main/resources/users.parquet")
df.select("name", "favorite_color").write.save("namesAndFavColors.parquet")DataFrame df = sqlContext.read().load("examples/src/main/resources/users.parquet");
df.select("name", "favorite_color").write().save("namesAndFavColors.parquet");
当数据源格式不是parquet格式文件时,需要手动指定数据源的格式。数据源格式需要指定全名(例如:org.apache.spark.sql.parquet),如果数据源格式为内置格式,则只需要指定简称(json,parquet,jdbc)。通过指定的数据源格式名,可以对DataFrames进行类型转换操作。示例如下:
val df = sqlContext.read.format("json").load("examples/src/main/resources/people.json")
df.select("name", "age").write.format("parquet").save("namesAndAges.parquet")DataFrame df = sqlContext.read().format("json").load("examples/src/main/resources/people.json");
df.select("name", "age").write().format("parquet").save("namesAndAges.parquet");
可以采用SaveMode执行存储操作,SaveMode定义了对数据的处理模式。需要注意的是,这些保存模式不使用任何锁定,不是原子操作。此外,当使用Overwrite方式执行时,在输出新数据之前原数据就已经被删除。SaveMode详细介绍如下表:

当使用HiveContext时,可以通过saveAsTable方法将DataFrames存储到表中。与registerTempTable方法不同的是,saveAsTable将DataFrame中的内容持久化到表中,并在HiveMetastore中存储元数据。存储一个DataFrame,可以使用SQLContext的table方法。table先创建一个表,方法参数为要创建的表的表名,然后将DataFrame持久化到这个表中。
默认的saveAsTable方法将创建一个“managed table”,表示数据的位置可以通过metastore获得。当存储数据的表被删除时,managed table也将自动删除。
Parquet是一种支持多种数据处理系统的柱状的数据格式,Parquet文件中保留了原始数据的模式。Spark SQL提供了Parquet文件的读写功能。
读取Parquet文件示例如下:
// sqlContext from the previous example is used in this example.
// This is used to implicitly convert an RDD to a DataFrame.
import sqlContext.implicits._
val people: RDD[Person] = ... // An RDD of case class objects, from the previous example.
// The RDD is implicitly converted to a DataFrame by implicits, allowing it to be stored using Parquet.
people.write.parquet("people.parquet")
// Read in the parquet file created above. Parquet files are self-describing so the schema is preserved.
// The result of loading a Parquet file is also a DataFrame.
val parquetFile = sqlContext.read.parquet("people.parquet")
//Parquet files can also be registered as tables and then used in SQL statements.
parquetFile.registerTempTable("parquetFile")
val teenagers = sqlContext.sql("SELECT name FROM parquetFile WHERE age >= 13 AND age <= 19")
teenagers.map(t => "Name: " + t(0)).collect().foreach(println)// sqlContext from the previous example is used in this example.
DataFrame schemaPeople = ... // The DataFrame from the previous example.
// DataFrames can be saved as Parquet files, maintaining the schema information.
schemaPeople.write().parquet("people.parquet");
// Read in the Parquet file created above. Parquet files are self-describing so the schema is preserved.
// The result of loading a parquet file is also a DataFrame.
DataFrame parquetFile = sqlContext.read().parquet("people.parquet");
// Parquet files can also be registered as tables and then used in SQL statements.
parquetFile.registerTempTable("parquetFile");
DataFrame teenagers = sqlContext.sql("SELECT name FROM parquetFile WHERE age >= 13 AND age <= 19");
List<String> teenagerNames = teenagers.javaRDD().map(new Function<Row, String>() {
public String call(Row row) {
return "Name: " + row.getString(0);
}
}).collect();
对表进行分区是对数据进行优化的方式之一。在分区的表内,数据通过分区列将数据存储在不同的目录下。Parquet数据源现在能够自动发现并解析分区信息。例如,对人口数据进行分区存储,分区列为gender和country,使用下面的目录结构:
path
└── to
└── table
├── gender=male
│ ├── ...
│ │
│ ├── country=US
│ │ └── data.parquet
│ ├── country=CN
│ │ └── data.parquet
│ └── ...
└── gender=female
├── ...
│
├── country=US
│ └── data.parquet
├── country=CN
│ └── data.parquet
└── ...通过传递path/to/table给 SQLContext.read.parquet或SQLContext.read.load,Spark SQL将自动解析分区信息。返回的DataFrame的Schema如下:
root
|-- name: string (nullable = true)
|-- age: long (nullable = true)
|-- gender: string (nullable = true)
|-- country: string (nullable = true)需要注意的是,数据的分区列的数据类型是自动解析的。当前,支持数值类型和字符串类型。自动解析分区类型的参数为:spark.sql.sources.partitionColumnTypeInference.enabled,默认值为true。如果想关闭该功能,直接将该参数设置为disabled。此时,分区列数据格式将被默认设置为string类型,不再进行类型解析。
像ProtocolBuffer、Avro和Thrift那样,Parquet也支持Schema evolution(Schema演变)。用户可以先定义一个简单的Schema,然后逐渐的向Schema中增加列描述。通过这种方式,用户可以获取多个有不同Schema但相互兼容的Parquet文件。现在Parquet数据源能自动检测这种情况,并合并这些文件的schemas。
因为Schema合并是一个高消耗的操作,在大多数情况下并不需要,所以Spark SQL从1.5.0开始默认关闭了该功能。可以通过下面两种方式开启该功能:
示例如下:
// sqlContext from the previous example is used in this example.
// This is used to implicitly convert an RDD to a DataFrame.
import sqlContext.implicits._
// Create a simple DataFrame, stored into a partition directory
val df1 = sc.makeRDD(1 to 5).map(i => (i, i * 2)).toDF("single", "double")
df1.write.parquet("data/test_table/key=1")
// Create another DataFrame in a new partition directory,
// adding a new column and dropping an existing column
val df2 = sc.makeRDD(6 to 10).map(i => (i, i * 3)).toDF("single", "triple")
df2.write.parquet("data/test_table/key=2")
// Read the partitioned table
val df3 = sqlContext.read.option("mergeSchema", "true").parquet("data/test_table")
df3.printSchema()
// The final schema consists of all 3 columns in the Parquet files together
// with the partitioning column appeared in the partition directory paths.
// root
// |-- single: int (nullable = true)
// |-- double: int (nullable = true)
// |-- triple: int (nullable = true)
// |-- key : int (nullable = true)
当向Hive metastore中读写Parquet表时,Spark SQL将使用Spark SQL自带的Parquet SerDe(SerDe:Serialize/Deserilize的简称,目的是用于序列化和反序列化),而不是用Hive的SerDe,Spark SQL自带的SerDe拥有更好的性能。这个优化的配置参数为spark.sql.hive.convertMetastoreParquet,默认值为开启。
从表Schema处理的角度对比Hive和Parquet,有两个区别:
由于这两个区别,当将Hive metastore Parquet表转换为Spark SQL Parquet表时,需要将Hive metastore schema和Parquet schema进行一致化。一致化规则如下:
Spark SQL缓存了Parquet元数据以达到良好的性能。当Hive metastore Parquet表转换为enabled时,表修改后缓存的元数据并不能刷新。所以,当表被Hive或其它工具修改时,则必须手动刷新元数据,以保证元数据的一致性。示例如下:
// sqlContext is an existing HiveContext
sqlContext.refreshTable("my_table")// sqlContext is an existing HiveContext
sqlContext.refreshTable("my_table")
配置Parquet可以使用SQLContext的setConf方法或使用SQL执行SET key=value命令。详细参数说明如下:
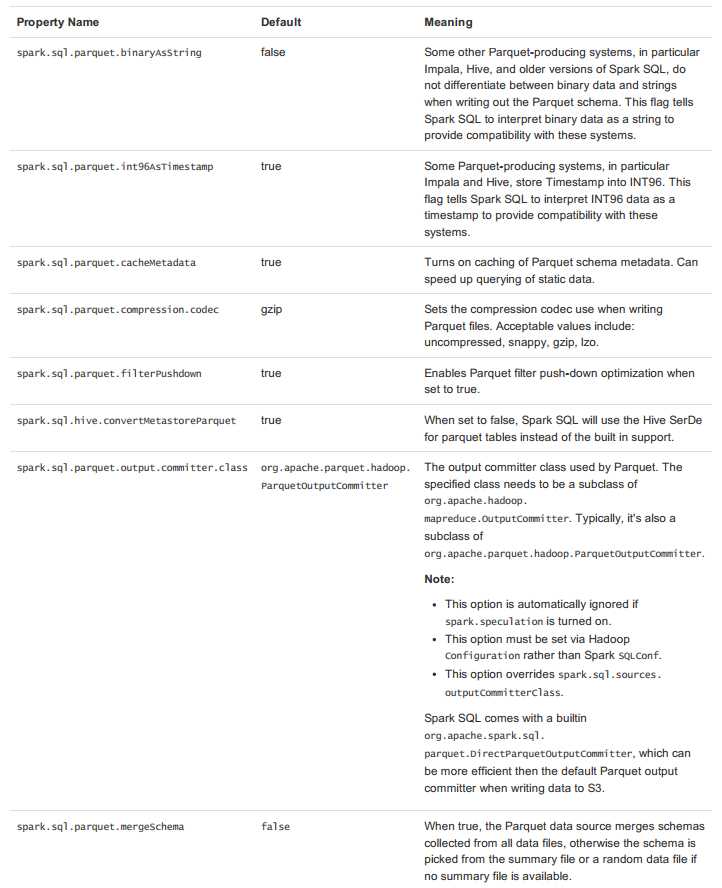
Spark SQL能自动解析JSON数据集的Schema,读取JSON数据集为DataFrame格式。读取JSON数据集方法为SQLContext.read().json()。该方法将String格式的RDD或JSON文件转换为DataFrame。
需要注意的是,这里的JSON文件不是常规的JSON格式。JSON文件每一行必须包含一个独立的、自满足有效的JSON对象。如果用多行描述一个JSON对象,会导致读取出错。读取JSON数据集示例如下:
// sc is an existing SparkContext.
val sqlContext = new org.apache.spark.sql.SQLContext(sc)
// A JSON dataset is pointed to by path.
// The path can be either a single text file or a directory storing text files.
val path = "examples/src/main/resources/people.json"
val people = sqlContext.read.json(path)
// The inferred schema can be visualized using the printSchema() method.
people.printSchema()
// root
// |-- age: integer (nullable = true)
// |-- name: string (nullable = true)
// Register this DataFrame as a table.
people.registerTempTable("people")
// SQL statements can be run by using the sql methods provided by sqlContext.
val teenagers = sqlContext.sql("SELECT name FROM people WHERE age >= 13 AND age <= 19")
// Alternatively, a DataFrame can be created for a JSON dataset represented by
// an RDD[String] storing one JSON object per string.
val anotherPeopleRDD = sc.parallelize(
"""{"name":"Yin","address":{"city":"Columbus","state":"Ohio"}}""" :: Nil)
val anotherPeople = sqlContext.read.json(anotherPeopleRDD)// sc is an existing JavaSparkContext.
SQLContext sqlContext = new org.apache.spark.sql.SQLContext(sc);
// A JSON dataset is pointed to by path.
// The path can be either a single text file or a directory storing text files.
DataFrame people = sqlContext.read().json("examples/src/main/resources/people.json");
// The inferred schema can be visualized using the printSchema() method.
people.printSchema();
// root
// |-- age: integer (nullable = true)
// |-- name: string (nullable = true)
// Register this DataFrame as a table.
people.registerTempTable("people");
// SQL statements can be run by using the sql methods provided by sqlContext.
DataFrame teenagers = sqlContext.sql("SELECT name FROM people WHERE age >= 13 AND age <= 19");
// Alternatively, a DataFrame can be created for a JSON dataset represented by
// an RDD[String] storing one JSON object per string.
List<String> jsonData = Arrays.asList(
"{\"name\":\"Yin\",\"address\":{\"city\":\"Columbus\",\"state\":\"Ohio\"}}");
JavaRDD<String> anotherPeopleRDD = sc.parallelize(jsonData);
DataFrame anotherPeople = sqlContext.read().json(anotherPeopleRDD);
Spark SQL支持对Hive的读写操作。需要注意的是,Hive所依赖的包,没有包含在Spark assembly包中。增加Hive时,需要在Spark的build中添加 -Phive 和 -Phivethriftserver配置。这两个配置将build一个新的assembly包,这个assembly包含了Hive的依赖包。注意,必须上这个心的assembly包到所有的worker节点上。因为worker节点在访问Hive中数据时,会调用Hive的 serialization and deserialization libraries(SerDes),此时将用到Hive的依赖包。
Hive的配置文件为conf/目录下的hive-site.xml文件。在YARN上执行查询命令之前,lib_managed/jars目录下的datanucleus包和conf/目录下的hive-site.xml必须可以被driverhe和所有的executors所访问。确保被访问,最方便的方式就是在spark-submit命令中通过--jars选项和--file选项指定。
操作Hive时,必须创建一个HiveContext对象,HiveContext继承了SQLContext,并增加了对MetaStore和HiveQL的支持。除了sql方法,HiveContext还提供了一个hql方法,hql方法可以执行HiveQL语法的查询语句。示例如下:
// sc is an existing SparkContext.
val sqlContext = new org.apache.spark.sql.hive.HiveContext(sc)
sqlContext.sql("CREATE TABLE IF NOT EXISTS src (key INT, value STRING)")
sqlContext.sql("LOAD DATA LOCAL INPATH ‘examples/src/main/resources/kv1.txt‘ INTO TABLE src")
// Queries are expressed in HiveQL
sqlContext.sql("FROM src SELECT key, value").collect().foreach(println)// sc is an existing JavaSparkContext.
HiveContext sqlContext = new org.apache.spark.sql.hive.HiveContext(sc.sc);
sqlContext.sql("CREATE TABLE IF NOT EXISTS src (key INT, value STRING)");
sqlContext.sql("LOAD DATA LOCAL INPATH ‘examples/src/main/resources/kv1.txt‘ INTO TABLE src");
// Queries are expressed in HiveQL.
Row[] results = sqlContext.sql("FROM src SELECT key, value").collect();
Spark SQL经常需要访问Hive metastore,Spark SQL可以通过Hive metastore获取Hive表的元数据。从Spark 1.4.0开始,Spark SQL只需简单的配置,就支持各版本Hive metastore的访问。注意,涉及到metastore时Spar SQL忽略了Hive的版本。Spark SQL内部将Hive反编译至Hive 1.2.1版本,Spark SQL的内部操作(serdes, UDFs, UDAFs, etc)都调用Hive 1.2.1版本的class。版本配置项见下面表格:
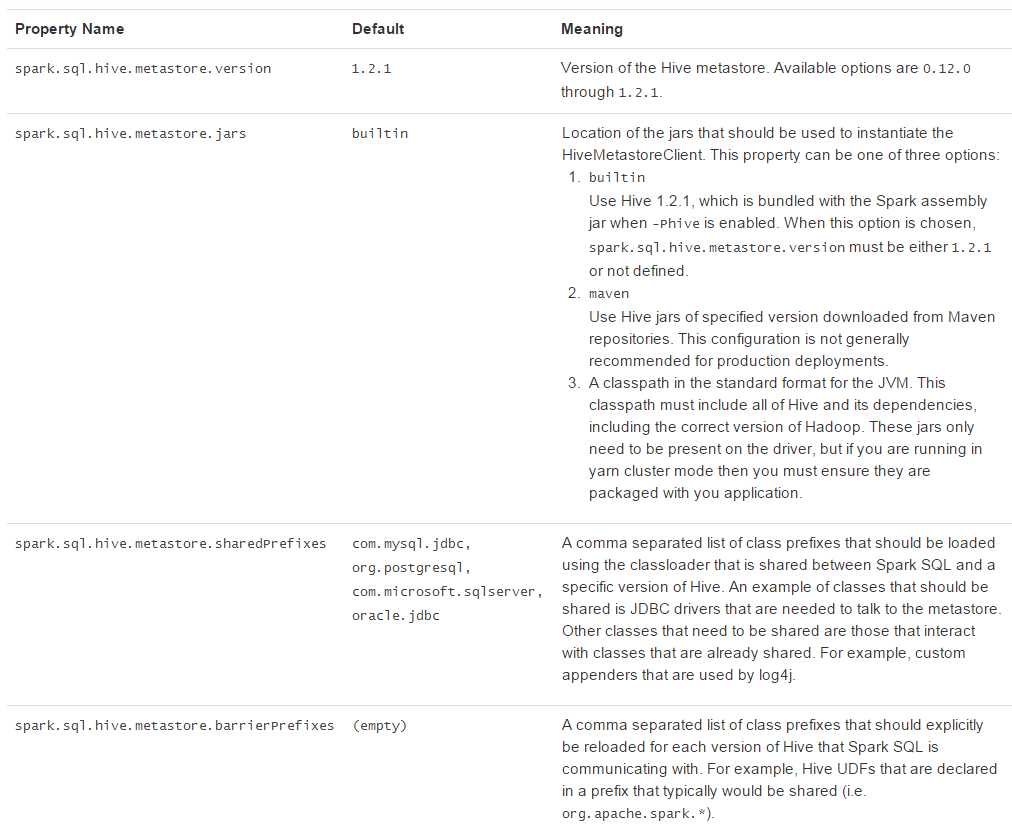
Spark SQL支持使用JDBC访问其他数据库。当时用JDBC访问其它数据库时,最好使用JdbcRDD。使用JdbcRDD时,Spark SQL操作返回的DataFrame会很方便,也会很方便的添加其他数据源数据。JDBC数据源因为不需要用户提供ClassTag,所以很适合使用Java或Python进行操作。
使用JDBC访问数据源,需要在spark classpath添加JDBC driver配置。例如,从Spark Shell连接postgres的配置为:
SPARK_CLASSPATH=postgresql-9.3-1102-jdbc41.jar bin/spark-shell远程数据库的表,可用DataFrame或Spark SQL临时表的方式调用数据源API。支持的参数有:
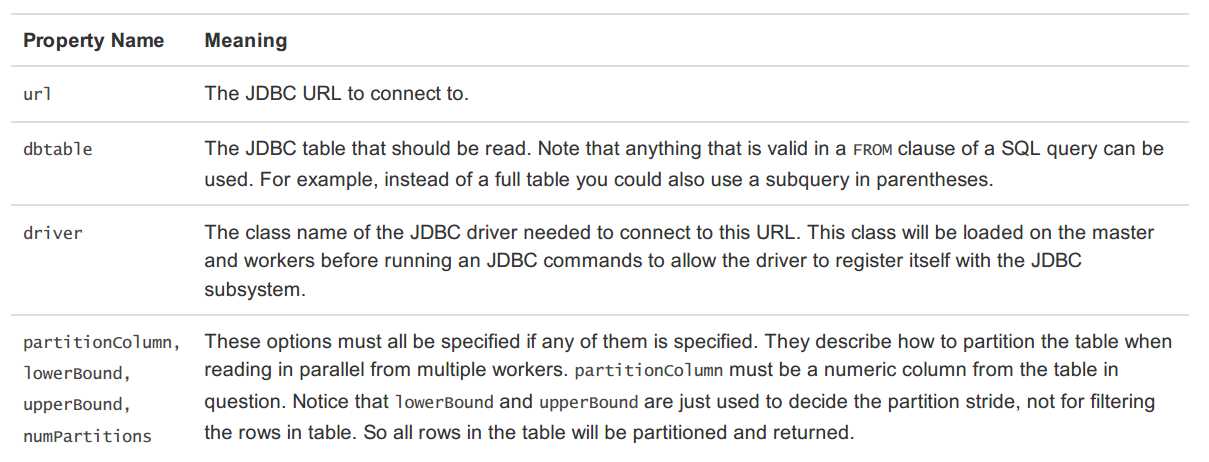
代码示例如下:
val jdbcDF = sqlContext.read.format("jdbc").options(
Map("url" -> "jdbc:postgresql:dbserver",
"dbtable" -> "schema.tablename")).load()Map<String, String> options = new HashMap<String, String>();
options.put("url", "jdbc:postgresql:dbserver");
options.put("dbtable", "schema.tablename");
DataFrame jdbcDF = sqlContext.read().format("jdbc"). options(options).load();
Spark SQL可以通过调用sqlContext.cacheTable("tableName") 或者dataFrame.cache(),将表用一种柱状格式( an inmemory columnar format)缓存至内存中。然后Spark SQL在执行查询任务时,只需扫描必需的列,从而以减少扫描数据量、提高性能。通过缓存数据,Spark SQL还可以自动调节压缩,从而达到最小化内存使用率和降低GC压力的目的。调用sqlContext.uncacheTable("tableName")可将缓存的数据移出内存。
可通过两种配置方式开启缓存数据功能:

可以通过配置下表中的参数调节Spark SQL的性能。在后续的Spark版本中将逐渐增强自动调优功能,下表中的参数在后续的版本中或许将不再需要配置。
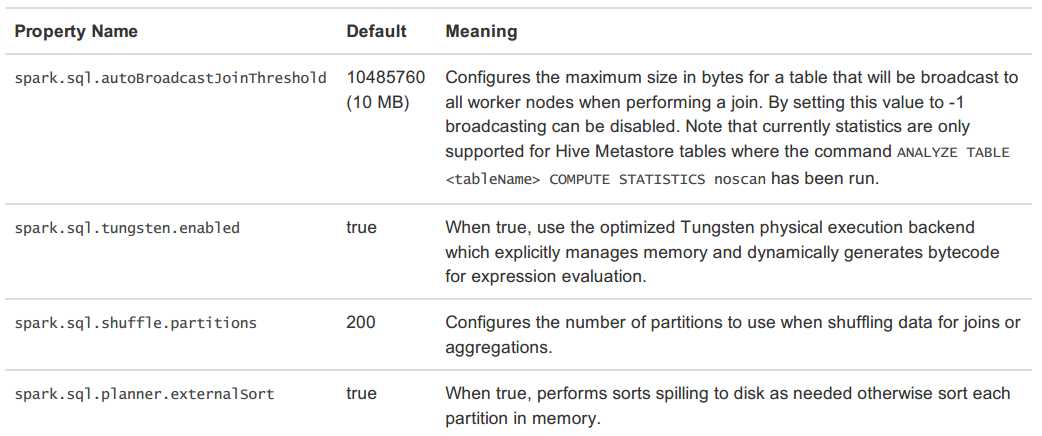
使用Spark SQL的JDBC/ODBC或者CLI,可以将Spark SQL作为一个分布式查询引擎。终端用户或应用不需要编写额外的代码,可以直接使用Spark SQL执行SQL查询。
这里运行的Thrift JDBC/ODBC服务与Hive 1.2.1中的HiveServer2一致。可以在Spark目录下执行如下命令来启动JDBC/ODBC服务:
./sbin/start-thriftserver.sh这个命令接收所有 bin/spark-submit 命令行参数,添加一个 --hiveconf 参数来指定Hive的属性。详细的参数说明请执行命令 ./sbin/start-thriftserver.sh --help 。
服务默认监听端口为localhost:10000。有两种方式修改默认监听端口:
export HIVE_SERVER2_THRIFT_PORT=<listening-port>
export HIVE_SERVER2_THRIFT_BIND_HOST=<listening-host>
./sbin/start-thriftserver.sh --master <master-uri> ..../sbin/start-thriftserver.sh --hiveconf hive.server2.thrift.port=<listening-port> --hiveconf hive.server2.thrift.bind.host=<listening-host> --master <master-uri>
...使用 beeline 来测试Thrift JDBC/ODBC服务:
./bin/beeline连接到Thrift JDBC/ODBC服务
beeline> !connect jdbc:hive2://localhost:10000在非安全模式下,只需要输入机器上的一个用户名即可,无需密码。在安全模式下,beeline会要求输入用户名和密码。安全模式下的详细要求,请阅读beeline documentation的说明。
配置Hive需要替换 conf/ 目录下的 hive-site.xml。
Thrift JDBC服务也支持通过HTTP传输发送thrift RPC messages。开启HTTP模式需要将下面的配参数配置到系统属性或 conf/: 下的 hive-site.xml中
hive.server2.transport.mode - Set this to value: http
hive.server2.thrift.http.port - HTTP port number fo listen on; default is 10001
hive.server2.http.endpoint - HTTP endpoint; default is cliservice测试http模式,可以使用beeline链接JDBC/ODBC服务:
beeline> !connect jdbc:hive2://<host>:<port>/<database>?hive.server2.transport.mode=http;hive.server2.thrift.http.path=<http_endpoint>
Spark SQL CLI可以很方便的在本地运行Hive元数据服务以及从命令行执行查询任务。需要注意的是,Spark SQL CLI不能与Thrift JDBC服务交互。
在Spark目录下执行如下命令启动Spark SQL CLI:
./bin/spark-sql配置Hive需要替换 conf/ 下的 hive-site.xml 。执行 ./bin/spark-sql --help 可查看详细的参数说明 。
Spark SQL与Hive Metastore、SerDes、UDFs相兼容。Spark SQL兼容Hive Metastore从0.12到1.2.1的所有版本。Spark SQL也与Hive SerDes和UDFs相兼容,当前SerDes和UDFs是基于Hive 1.2.1。
Spark SQL Thrift JDBC服务与Hive相兼容,在已存在的Hive上部署Spark SQL Thrift服务不需要对已存在的Hive Metastore做任何修改,也不需要对数据做任何改动。
Spark SQL支持多部分的Hive特性,例如:
下面是当前不支持的Hive特性,其中大部分特性在实际的Hive使用中很少用到。
Major Hive Features
Esoteric Hive Features
Hive Input/Output Formats
Hive优化
部分Hive优化还没有添加到Spark中。没有添加的Hive优化(比如索引)对Spark SQL这种in-memory计算模型来说不是特别重要。下列Hive优化将在后续Spark SQL版本中慢慢添加。
SET spark.sql.shuffle.partitions=[num_tasks]; ”控制post-shuffle的并行度,不能自动检测。
Spark SQL和DataFrames支持的数据格式如下:
Spark SQL所有的数据类型在 org.apache.spark.sql.types 包内。不同语言访问或创建数据类型方法不一样:
Scala
代码中添加 import org.apache.spark.sql.types._,再进行数据类型访问或创建操作。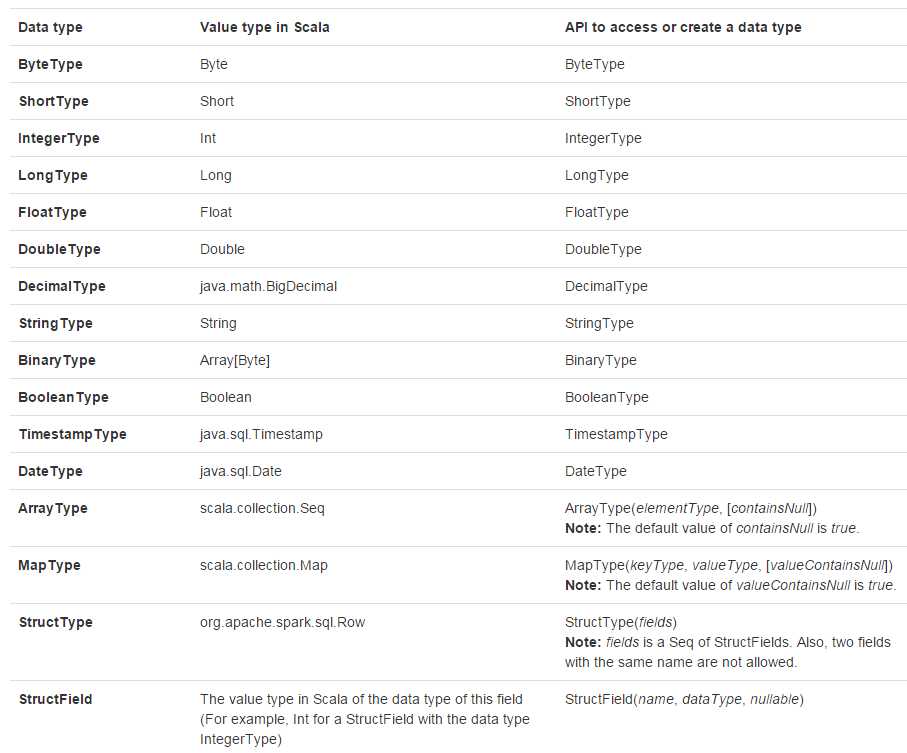
Java
可以使用 org.apache.spark.sql.types.DataTypes 中的工厂方法,如下表: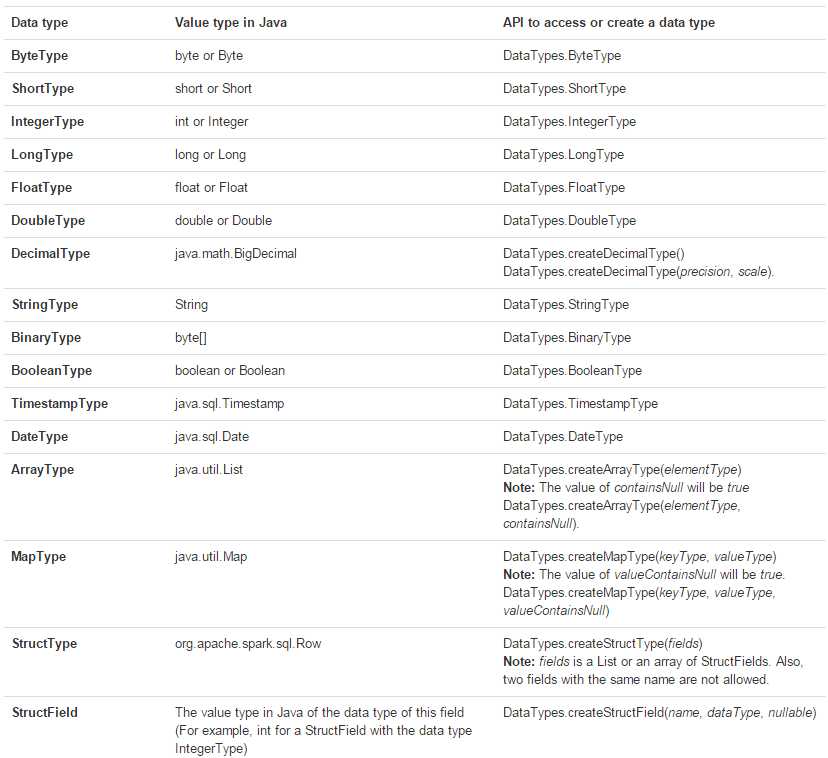
当处理float或double类型时,如果类型不符合标准的浮点语义,则使用专门的处理方式NaN。需要注意的是:
标签:
原文地址:http://www.cnblogs.com/yangsy0915/p/5087043.html