标签:
Chapter 1: Setting the Foundations
The human race is a naturally inquisitive species. We just love tinkering with things. When I recently bought a new iMac, I had it to bits within seconds, before I’d even read the instruction manual. We enjoy working things out ourselves and creating our own mental models of how we think things behave. We muddle through and only turn to the manual when something goes wrong or defies our expectations.
人类是天然好奇的物种。我们喜欢对事情寻根问底。(muddle through 蒙混过关 ;defies 难以满足)
One of the best ways to learn Cascading Style Sheets (CSS) is to jump right in and start tinkering. In fact, I imagine this is how the majority of you learned to code, by picking things up off blogs, viewing source to see how things worked, and then trying them out on your personal sites. You almost certainly didn’t start by reading the full CSS specification, which is enough to put anyone to sleep.
学习CSS 最好的方法是跳出局限,同时保持探究。(majority of 大多数)
In this chapter you will learn about
• Structuring your code
• The importance of meaningful documentation
• Naming conventions
• When to use IDs and class names
• Microformats
• Different versions of HTML and CSS
• Document types, DOCTYPE switching, and browser modes
A brief history of markup
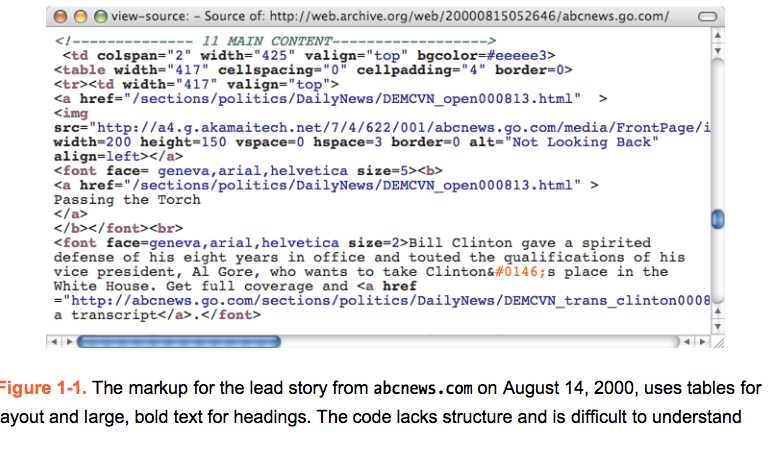
The early Web was little more than a series of interlinked(相通的) research documents using HTML to add basic formatting and structure. However, as the World Wide Web gained in popularity, HTML started being used for presentational(陈述的 表象的) purposes. Instead of using heading elements for page headlines, people would use a combination of font and bold tags to create the visual effect they wanted. Tables got co-opted as a layout tool rather than a way of displaying data, and people would use blockquote to add whitespace rather than to indicate quotations. Very quickly, the Web lost its meaning and became a jumble of(混乱) font and table tags. Web designers came up with a name for this kind of markup; they called it tag soup (see Figure 1-1).
上述论述了使用表格布局带来的问题:一大堆 tags 构成了所谓的 tags soup
As web pages became more and more presentational, the code became increasingly difficult to understand and maintain. WYSIWYG (What You See Is What You Get) editors offered authors an escape from these complexities and promised a brave new world of visual layout. Unfortunately, rather than making things simpler, these tools added their own complicated markup to the mix. Editors like FrontPage or Dreamweaver allowed users to build complex table layouts at the click of a button, cluttering the code with nested tables and “spacer GIFs” (see Figure 1-2). Sadly, these layouts were extremely fragile(脆弱) and prone(容易) to breaking. Because the markup was littered with meaningless code, it was easy to delete the wrong tag and watch the whole layout crumble(崩溃). Furthermore, due to the complexity of the code, bug hunting was almost impossible. It was often easier to code the page from scratch than hunt around in the hope of fixing the bug. Things were further complicated if you were working on a large site. Because the presentation of the site was locked into the individual pages, you had to craft complicated “find and replace” routines to make even the smallest sitewide change. I’ve broken more than one site in my time because of a hastily(草草) constructed “find and replace” routine. Consequently, your page templates would go out of sync extremely quickly, and a simple change could mean hand editing every page on your site.
Tables were never meant for layout, so David Siegel invented a clever hack to make them work. In order to prevent tables from horizontally or vertically collapsing, Siegel suggested using a 1- pixel transparent GIF. By putting these hidden images in their own table cells and then scaling them vertically or horizontally, you could artificially enforce a minimum width on the cells, thus preserving the layout. Also known as a “shim GIF” because of the file name given to them in Dreamweaver, they were an extremely common sight in old school table-based layouts. Thankfully, the practice has now died out, so you no longer see these presentational elements cluttering up your code.
大意是 table 式的布局非常难以维护,tag 很容易被误删,尤其当代码量非常大时,一个非常小的改动就会造成 沉重的改动工作量。主要指出了传统 table 式布局的复杂之处
(注: “shim GIF“ Also known as a transparent gif or a spacer gif.
It is a transparent picture that cannot be seen
It is used to hold open tables cells and can be resized to any dimensions.
)
Rather than being seen as a simple markup language, HTML gained a reputation for being complicated, confusing, and prone to errors. Consequently, many people were afraid of touching the code, which resulted in an overreliance on visual editors and spawned a whole generation of designers that didn’t understand how to code. By the turn of the millennium, the web design industry was in a mess, and something needed to be done.
问题摆在那里,是应该提出解决方案了!
Then along came Cascading Style Sheets. CSS allowed authors to control how a page looked through an external style sheet, making it possible to separate the content from presentation. Now, sitewide changes could be made in one place and would propagate(传播) throughout the system. Presentational tags like the font tag could be ditched(抛弃), and layout could be controlled using CSS instead of tables. Markup could be made simple again, and people began to develop a newfound interest in the underlying(底层) code.
于是 CSS 横空出世了!
Most importantly for the context of this book, meaningful markup provides you with a simple way of targeting the elements you wish to style. It adds structure to a document and creates an underlying framework to build upon. You can style elements directly without needing to add other identifiers, and thus avoid unnecessary code bloat(膨胀).
CSS 好处!
IDs and class names Meaningful elements provide an excellent foundation, but the list of available elements isn’t exhaustive. HTML 4 was created as a simple document markup language rather than an interface language. Because of this, dedicated elements for things such as content areas or navigation bars just don’t exist. You could create your own elements using XML, but for reasons too complicated to go into, it’s not very practical.
HTML4 是标记型语言,而不是接口语言
HTML 5 hopes to solve some of these problems by providing developers with a richer set of elements to work with. These include structural elements like header, nav, article, section, and footer as well as well as new UI features like data inputs and the menu element. In preparation for HTML 5, many developers have started adopting these as naming conventions for their ID and class names.
HTML5 拥有更多元素进行处理!
An ID is used to identify a specific element, such as the site navigation, and must be unique to that page. IDs are useful for identifying persistent structural elements such as the main navigation or content areas. They are also useful for identifying one-off elements—a particular link or form element, for example.
While a single ID name can only be applied to one element on a page, the same class name can be applied to any number of elements on a page. This makes classes much more powerful. Classes are useful for identifying types of content or similar items
ID 用于标示唯一元素,在页面内必须唯一,Class 用于标示大量相同元素,此标签具有更大威力!
Naming your elements :It is often difficult to decide if an element should have an ID or class name. As a general rule, classes should be applied to conceptually similar items that could appear in multiple places on the same page, whereas IDs should be applied to unique elements. However, you then get into a debate about which elements are conceptually similar and which elements are unique.
Divs and spans :One element that can help add structure to a document is the div element. Many people mistakenly believe that a div element has no semantic meaning. However, div actually stands for division and provides a way of dividing a document into meaningful areas. So by wrapping your main content area in a div and giving it a class of content, you are adding structure and meaning to your document. Using too many divs is often described as divitus and is usually a sign that your code is poorly structured and overly complicated. Instead, divs should be used to group related items based on their meaning or function rather than their presentation or layout.
divs 为块级元素,常用于“分割”-分割 documents 为不同的部分,但是用太多的 divs 并不是一件那么好的事,实际上,div 用于将相关的元素分组聚合到一起,而不是仅仅考虑布局而将其聚合到一起!
Different versions of HTML and CSS: CSS comes in various versions, or levels, so it’s important to know which version to use.
CSS 1 became a recommendation at the end of 1996 and contains very basic properties such as fonts, colors, and margins.
CSS 2 was released in 1998 and added advanced concepts such as floating and positioning to the mix, as well as new selectors like the child, adjacent sibling, and universal selectors.
CSS 3 has been broken down into modules that can be released and implemented independently. CSS 3 contains some exciting new additions, including an advanced layout module, brand new background properties, and a host of new selectors. Some of these modules are scheduled for release as soon as the second half of 2009. Sadly, we’ve been here before, and several modules have been on the verge of release only to be pushed back into “last call” or “working draft” status, so it’s difficult to know how many will actually make the grade. Hopefully, by 2011, we’ll see a number of these modules become official recommendations. More worryingly, some modules don’t appear to have been started, while others haven’t been updated for several years. Due to this glacial pace of development, it seems unlikely the CSS 3 will ever be fully complete.
The good news is that, despite the numerous delays, many browser vendors have already implemented some of the more interesting parts of the CSS 3 specification. As such, it is possible
to start using many of these exciting selectors today
CSS 各版本的情况如上,CSS 3 从 2009 年下半年开始推进,但是大多数仅仅停留在“草案”阶段,模块没有全部完成。但是好消息是,不少浏览器已经开始支持 CSS3 的部分特性了!
HTML 4.01 became a recommendation at the end of 1999 and is the version of HTML that most people use. In January 2000 the W3C created an XML version of HTML 4.01 and named it XHTML 1.0. The main difference between XHTML 1.0 and HTML 4.01 is that it follows the XML coding conventions. This means that, unlike in regular HTML, all XHTML attributes must contain quote marks, and all elements must be closed.
XHTML 1.1 was an attempt to take XHTML even closer to XML. There was very little practical difference between the two languages. However there was one big theoretical difference. While it was still considered acceptable to serve up an XHTML 1.0 page as an HTML document, XHTML 1.1 pages were supposed to be sent to the browsers as if they were XML. This meant that if your XHTML 1.1 page contained a single error, such as an unencoded ampersand, web browsers weren’t supposed to display the page. This obviously isn’t ideal for most website owners, so XHTML 1.1 never really took off. There is still some debate as to whether you should serve up an XHTML 1.0 pages as if it were HTML or if you’re better sticking with HTML 4.01. However, it’s clear that you shouldn’t be using XHTML 1.1 unless you’re using the correct mime type and are happy for your page not to display if it contains an error. HTML 5 is relatively new, and as a draft specification is changing all the time. However, it has a lot of momentum and several popular browsers have already started building in support. HTML 5 grew out the frustration(挫折) developers had with the slow and archaic (古老)development of XHTML 2. So a group of them decided to draft their own specification. This proved so successful that HTML 5 became an official W3C project, and the development of XHTML 2 was sidelined(搁置).
上面介绍了 HTML 4.01,XHTML 1.0,XHTML 1.1 ,XHTML 2.0, HTML5 的发展历史,其中由于 XHTML 1.1 的弊端,不推荐使用 该版本,HTML5 是一个 XHTML 2 的替代!
Document types, DOCTYPE switching, and browser modes:A Document Type Definition (DTD) is a set of machine-readable rules that define what is and isn’t allowed in a particular version of HTML or XML. Browsers are supposed to use these rules when parsing a web page to check the validity of the page and act accordingly. Browsers know which DTD to use, and hence which version of HTML you are using, by analyzing the page’s DOCTYPE declaration.
A DOCTYPE declaration is a line or two of code at the start of your HTML document that describes the particular DTD being used. In this example, the DTD being used is for XHTML 1.0 Strict: DOCTYPE declarations will typically, but not always, contain a URL to the specified DTD file. So HTML5, for instance, doesn’t require a URL. Browsers tend to not read these files, choosing instead to recognize common DOCTYPE declarations. DOCTYPEs currently come in two flavors, strict and transitional. As the name suggests, transitional DOCTYPEs are aimed at people transitioning from older versions of the language. As such, the transitional versions of HTML 4.01 and XHTML 1.0 still allow the use of deprecated elements like the font element. The strict versions of these languages ban the use of deprecated elements to separate content from presentation.
DTD 是给 浏览器“看”的,根据 DTD 的不同 浏览器会进行不同的动作,html5 的 DTD 并不需要包含 url 字段
Validation As well as being semantically marked up, an HTML document needs to be written using valid code. If the code is invalid, browsers will try to interpret the markup themselves, sometimes getting it wrong. Worse still, if an XHTML document is being sent with the correct MIME type, browsers that understand XML simply won’t display an invalid page. Because browsers need to know which DTD to use in order to process the page correctly, a DOCTYPE declaration is required for the page to validate. You can check to see if your HTML is valid by using the W3C validator, a validator bookmarklet, or a plug-in like the Firefox Web Developer Extension. Many HTML editors now have validators built in, and you can even install a copy of the W3C validator locally on your computer. The validator will tell you if your page validates, and if not, why not !
此节用于说明 validate 的重要性,通过 W3C 的 validator 可以尽早知道 那里没有通过 validate!
[CSS Mastery]Chapter 1: Setting the Foundations
标签:
原文地址:http://www.cnblogs.com/muyiblog/p/5134086.html