标签:
SQL语句其实并不是在transaction.commit()的时候发出的,而是在一句session.flush()发出。在transaction.commit()的内部就调用了session.flush()方法。之后才会提交SQL语句
在Hibernate内部去检查所有的持久化对象,如果持久化对象是由临时状态转换过来的,发出insert语句;如果持久化对象是由get方法得到的,再查看下副本,如果和副本对照一致,什么都不做,如果和副本不一样,则发出update语句
缓存的概念: 在内存区域开辟了临时空间。把一些数据临时放在内存区域,需要的时候直接从内存拿
市面上的缓存有哪些:
小型缓存-小型应用:oscache,ehcache
大型缓存-分布式应用:memory cache,redis
和大数据有关(hadoop生态圈)-分布式应用: hbase
用缓存需要考虑问题:
1.需要一些api把数据库中的数据放到缓存中
2.有一些方法从缓存中把数据提取出来
3.如果缓存中的数据发生变化,需要把数据同步到数据库中(检查缓存中的数据和数据库中的数据的一致性)
4.把数据库中的数据同步到缓存中。
5.hits命中率越低的对象应该从缓存中清空
分布式缓存:
缓存放在很多机器(节点)上。
分布式缓存对于客户端是不可见的,意思是有个黑匣子把节点全部包含了起来。分布式缓存存在的意义,缓存存在与服务器中,并放量太高。导致服务器崩溃,所以我们增加一台服务器,有着相同的缓存(相同缓存数据)。
应用:tomcat服务器并发量为150个,实际上并发量达到了100速度就很慢了,我们的解决方法就是增加服务器,但问题随之出现,session不一致。我们就把session放在tomcat的分布式缓存中(memory cache),分布式缓存就帮我们把session在服务器之间同步起来。
ps:tomcat与memory cache可以进行无缝贴合
Hibernate的一级缓存又名为session级别的缓存。一级缓存的生命周期和session的生命周期保持一致
SessionImpl实现类中的private transient StatefulPersistenceContext persistenceContext属性。
StatefulPersistenceContext类型的private Map entitiesByKey属性;就是一级缓存在内存中的对象
前一章,我们知道当我们在内存中创建了临时状态对象,通过session的一些方法进入了Hibernate中变为持久化状态,实际上这么说并不对,在这里就应该更正为并不能说进入了hibernate中,而应该说进入了一级缓存中。换句话说,如果说一个对象是一个持久化状态对象,那么这么对象就在一级缓存中。
证明方法一:连续两次get操作
证明方法二:hibernate的统计机制。session.getStatistics().getEntityCount()
结论:1。get(),save(),update().把对象放到了一级缓存当中。clear()也就是清空一级缓存中所有的数据。
2。当调用了session.close().一级缓存的生命周期就结束了
3。clear()清空一级缓存中所有的数据
4。evict()可以把一个对象从session的缓存中清空
看个例子:
假设有一辆xx路公交车,有很多站点。当公交车想要重新换一条线路的时候
(1)bus-station,一对多的关联关系,通俗的解释就是1个bus对应多个station。每个station对应一个bus
(2)
SessionFactory sessionFactory=HibernateUtils.getSessionFactory(); Session session=sessionFactory.openSession(); Transaction transaction=session.beginTransaction(); Bus bus=(Bus)session.get(Bus.class,1); Set<Station> stations=bus.getStations(); System.out.println(session.getStatistics().getEntityCount());
.....
注意:可能大家的控制台输出的一级缓存中只有1个对象。因为延迟加载的原因,后续介绍,只需要在相应的映射文件中,把
<set name="stations" table="STATION" inverse="false" lazy="false" cascade="save-update">
中lazy的值改为false即可。
(3)更改线路
Bus bus=(Bus)session.get(Bus.class,1); Set<Station> stations=bus.getStations(); for(Station station:stations){ station.setName("新地址"); } transaction.commit();
查看控制台输出:
在事务提交以后,与数据库交互了一次,把一级缓存中持久化对象有变化的,发出了所有的update语句进行了更新,优势就是再一次数据库交互中一次性的发送,减少了与数据库的交互次数

ps:注意此图的箭头标注的是 副本对象,表示副本对象和数据库保持一致
底层原理:
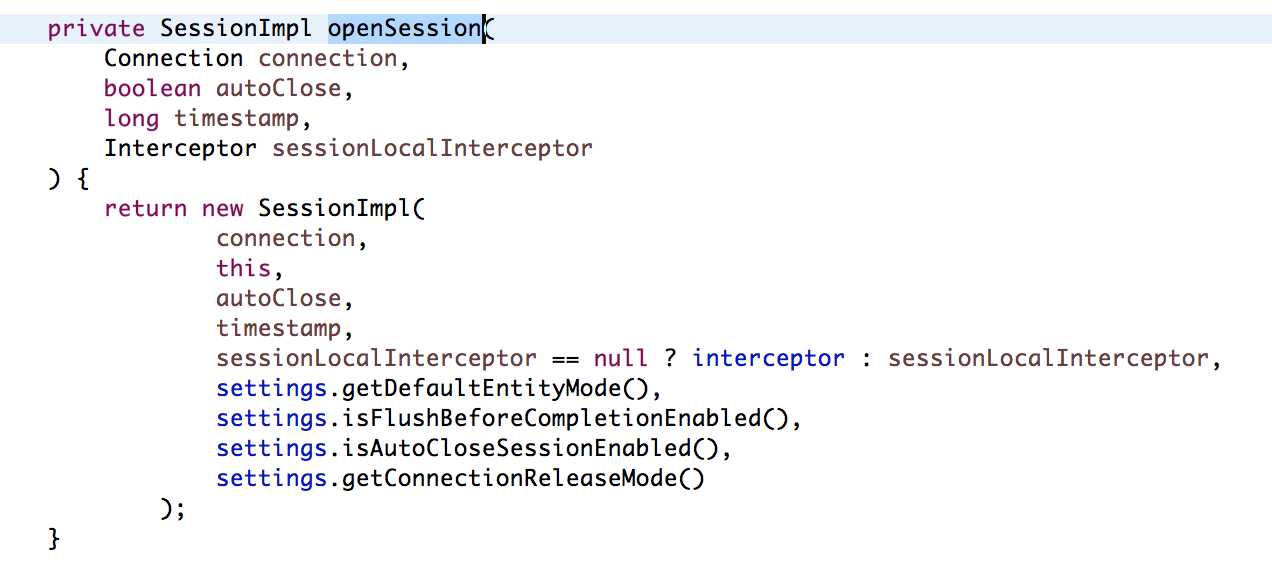
可以发现,实际上openSession(),就是把连接传递过去,直接创建一个Session实例。只要创建一个新的session,就会打开一个新的连接
这种方式的缺点:
在某些场合下有很多弊端:当在购物网购物的时候,在结账的时候。要把购物信息保存在购物网的数据库中,还需要把商品总数量减少。etc。这些事情都要在一个事务情况下运行。 订单系统:当你要保存到购物订单数据中,我们需要一个session。session就是openSession()获得的。商品系统:当你购物需要减少总库存,我们也需要一个session。session通过openSession()获得。money系统:钱的转账也需要session,获得同上。 但是这些所有系统的事情都在一个事务下发生,可是我们创建了三个session。通过源码我知道,每次openSession()都是创建一个新的session,相当于一个新的连接。所以这种方式来获得session是不可行的.
对于上述缺陷的解决,因为在结账的时候产生的操作,他们处于同一线程,因此我们使用线程局部变量来存储session,就这引出了下面这种方式
1。在hibernate.cfg.xml的配置文件中增加:
<property name="current_session_context_class">thread</property>
2。调用SessionFactory的getCurrentSession()。
【注意】
a.要使用线程中的session,增删改查必须在事务的环境下进行
b.当执行transaction.commit的时候,session自动关闭。这样子不好,如果事物提交以后,再做关于数据库的操作就不可以操作了
先从当前线程中找到map,在从key为sessionFactory所对应的value(也就是session)中获取,然后获取,如果没有取到,则创建session,然后把它在放入线程的map中
map中为什么key是sessionFactory
答:1.支持多个数据库连接,一个sessionFactory代表一个数据库连接,如果是单数据库连接,sessionFactory只有一个,如果是单数据库,sessionFactory的key不变,session只有一个 2.尽量保证,从request到response只有一个session比较好。request操作后台,打开一次数据库就够了
结论:
如果在一个线程中,共享一个数据,那么把数据放入到threadlocal中是一个不错的选择
请移步先看:Hibernate【关联关系】这篇博客,再看下面的内容
适用场合一:12306网站,当你打开网站,需要选择出发地和目的地。当你选择出发地和目的地的时候,网站肯定不会一次一次请求数据库来显示各个省份,而应该直接取内存中去获取这些省份
适用场合二:MyEclipse的菜单,比如创建工程什么的,菜单栏选项(固定数据)就在数据库中,不应该当点击某个菜单的时候,在一条一条从数据库获取菜单,而应该把这些菜单放在缓存。
不适用场合三:股票一些实时信息,数据随时都在变,不能放在缓存中
不适用场合四:财务系统,个人工资信息应该是保密的,不能放在缓存中
这上面的例子说明了三个方面的数据会使用二级缓存
1.公开的
2.固定的(数据不会发生变化)
3.数据保密性不是很强
ps:如果一个数据一直在变,不适合用缓存。
扩展:还有一些数据,本身数据是不变的,但是流动的,称这些数据为“流式数据”。比如,我们再去飞机场途中,玩下手机,在玩手机的过程中,信号就产生了,电信产生了信息:某某在什么时间什么地方发了信息。等你坐飞机到了目的地,又玩了下手机,信号又发出,这样子可以知道你的路径,这样就可以给你推送一些需要的信息,这样的数据叫流数据,数据没改,这样的数据适用用storm来做,如果流数据量特别大,比如一个省,几千万个人在玩手机,就需要时时刻刻计算,走到哪就要把信息推送到哪,这些信息就是即时的,这个storm就是在缓存中计算的
SessionFactory级别的,只要Hibernate一启动,Hibernate就有了,SessionFactory一直不消失,那么二级缓存在哪里?
SessionFactoryImpl该类中有个Map,该Map名称为entityPersisters.他就是存放类级别二级缓存的位置;在这个类中我们也看到了一个叫CollectionPersisters的Map,它正是集合二级缓存。
Hibernate并没有实现二级缓存,他是借助了第三方插件完成。
原因:oscache,ehcache。。市面上有许多缓存了,Hibernate没有必要专门做一个,所以Hibernate利用了ehcache实现了二级缓存
如何在Hibernate中配置呢?
1.导入jar包
ehcache-xxx.jar
2.在hibernate.cfg.xml配置文件增加一些配置
a。设置二级缓存的供应商
<property name="cache.provider_class">
org.hibernate.cache.EhCacheProvider
</property>
b.开启二级缓存()
<property name="cache.use_second_level_cache">
true
</property>
3.指定哪个类开启二级缓存(两种方法)
方式一:在hibernate.cfg.xml中指定(该方式不常用)
<class-cache usage="read-only" class=""/> <!-- 类级别的二级缓存 --> <collection-cache ...><!-- 集合的二级缓存。集合指的是 一对多,多对多。。。中的对象对集合中的集合 -->
方式二:在*.hbm.xml中指定
<hibernate-mapping> <class name="domain.Person" table="PERSON"> <cache usage="read-only"/> <!-- 开启了Person的二级缓存 --> <id name="pid" type="java.lang.Integer"> <column name="PID" /> <generator class="increment" /> </id> <property name="name" type="java.lang.String"> <column name="NAME" /> </property> .....
用哪些方法可以把对象放入二级缓存?
@Test
public void updateStudent(){
sessionFactory=getSessionFactory();
Session session=sessionFactory.openSession();
Person person=(Person)session.get(Person.class, 1);
session.close();
Session session2=sessionFactory.openSession();
Person person2=(Person)session2.get(Person.class, 1);
session2.close();
}
控制台只发出了一次sql语句,显然当第一次session.close()后,一级缓存中已经没有对象了,第二次get操作没有发出sql语句,直接拿到了数据,通过源码可知(DefaultLoadEvenListener类),get操作会先从一级缓存中获取,再从二级缓存中获取,否则就会向数据库发出sql语句,由此可知,get把对象放入了二级缓存中,并从二级缓存中获取
查看get操作的源码
。。
发现要证明是在哪一步放入了二级缓存很难证明,由此我们引入了统计机制,那么如何使用呢?
1.在配置文件中开启二级缓存统计机制
<property name="generate_statistics">true</property>
2.使用:"sessionFactory.getStatistics().getEntityLoadCount();"
结论:save()方法并不能操作二级缓存。虽然保存了,数据可能会变化,而二级缓存的数据不能变化,同update一样,
结论:不操作二级缓存
权限!一个系统开发完以后,权限是确定的,权限是不需要维护的,我们只需要把权限分配给用户。在tomcat启动的时候,把权限保存在二级缓存中,权限是从数据库中获取的。问题来了,一个系统有400个页面,一个页面有4个功能,一共1600个功能,现在我们只有get方法可以让对象进入二级缓存,一个get方法只能获取一个功能,我们不能get 1600次。那怎么操作?
利用查询让对象进入二级缓存中
@Test
public void testQuery(){
sessionFactory=getSessionFactory();
Session session=sessionFactory.openSession();
List<Person> persons=session.createQuery("from domain.Person").list();//HQL语句 hibernate query language
System.out.println(sessionFactory.getStatistics().getEntityLoadCount());
session.close();
}
"from domian.Person"是HQL语句,值得注意的是这里domain.person是持久化类对应.hbm.xml中class的name名称,而不是table名称。
list()方法把查询出来的数据都放入了二级缓存中,因为控制台打印出了4(person对应的表中有4条数据),并且只发出了一条sql语句
但是:
@Test
public void testQuery(){
sessionFactory=getSessionFactory();
Session session=sessionFactory.openSession();
List<Person> persons=session.createQuery("from domain.Person").list();//HQL语句 hibernate query language
System.out.println(sessionFactory.getStatistics().getEntityLoadCount());
session.close();
Session session2=sessionFactory.openSession();
persons=session2.createQuery("from domain.Person").list();//HQL语句 hibernate query language
System.out.println(sessionFactory.getStatistics().getEntityLoadCount());
}
看到第二次执行list()的时候,又发出了一条sql语句,并且二级缓存里的对象变成double份,看出list只能存入二级缓存却不能取出二级缓存中的对象,那么如何取出来呢?
@Test
public void testQuery(){
sessionFactory=getSessionFactory();
Session session=sessionFactory.openSession();
List<Person> persons=session.createQuery("from domain.Person").list();//HQL语句 hibernate query language
System.out.println(sessionFactory.getStatistics().getEntityLoadCount());
session.close();
Session session2=sessionFactory.openSession();
Iterator<Person> iterator=session2.createQuery("from domain.Person").iterate();
while(iterator.hasNext()){
Person person=iterator.next();
System.out.println(person.getName());
}
session2.close();
}
发现先执行了查询id的sql语句,然后直接得到了我们要的值。
总结:list方法会让hql语句查询出来的结果进入二级缓存,但是list方法不利用二级缓存查询
iterator方法的查询策略,不管二级缓存有没有数据,先查询表的所有的id,然后根据id值从二级缓存中查找数据,如果有,则利用二级缓存,如果没有,则直接根据id查询该表中的所有对象
用哪些方法可以把对象从二级缓存中提取出来?
iterator
get
把集合存放进二级缓存
1.修改*.hbm.xml配置文件
<class>
<id></id>
<property></property>
....
<set name="students" table="STUDENT" cascade="save-update" inverse="false">
<cache usage="read-only"/>
<key>
<column name="PID" />
</key>
<one-to-many class="domain.Student" />
</set>
</class>
2.放入
@Test
public void testCollection(){
sessionFactory=getSessionFactory();
Session session=sessionFactory.openSession();
Person person=(Person)session.get(Person.class, 1);
Set<Student> students=person.getStudents();
for(Student s:students){
s.getName();
}
System.out.println(sessionFactory.getStatistics().getEntityLoadCount());
System.out.println(session.getStatistics().getCollectionCount());
System.out.println(sessionFactory.getStatistics().getCollectionLoadCount());
session.close();
}
<cache usage="read-only"/>
usage:
read-only:只读策略,正是因为这个策略,所以对二次缓存对象不能修改
read-write:对二级缓存中的对象能够进行读和写的操作
二级缓存存放的数据量过大时也会导致查询效率降低,
解决:移到磁盘上
ehcache本身就具有这样的功能,我们需要配置
1.在根目录下创建ehcache.xml的配置文件
<ehcache xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:noNamespaceSchemaLocation="../config/ehcache.xsd">
<diskStore path="/Users/admin/Documents/workspace/HIbernate/ddd"/>
<!-- 默认存储策略 -->
<defaultCache
maxElementsInMemory="12"
eternal="false"
timeToIdleSeconds="1200"
timeToLiveSeconds="1200"
overflowToDisk="false"
maxElementsOnDisk="10000000"
diskPersistent="false"
diskExpiryThreadIntervalSeconds="120"
memoryStoreEvictionPolicy="LRU"
/>
<!-- timeToIdleSeconds:最大空闲时间,这个对象没有用1200s,这个对象如果一直没用超过一定时间就作废
maxElementsOnDisk="10000000" 磁盘上最大村多大对象
<Cache
name="domain.Person"
maxElementsInMemory="3"
eternal="false"
timeToIdleSeconds="120"
timeToLiveSeconds="120"
overflowToDisk="true"
maxElementsOnDisk="10000000"
diskPersistent="false"
diskExpiryThreadIntervalSeconds="120"
memoryStoreEvictionPolicy="LRU"
/>
</ehcache>
2.用list方法(),把hql语句查询结果全部放入二级缓存,此时在你设置的路径下,就会创建一个临时文件,用来存放二级缓存
一级缓存解决再一次请求的过程中和数据库只交互一次,二级缓存解决把固定,公开的数据放进去,方便查询,那么查询缓存是什么的呢?
一级缓存和二级缓存都是兑现缓存,意思是缓存一个对象,并且这个对象是持久化对象,更进一步解释说,假设有一个持久化对象,这个对象中有300个字段,一级缓存或者二级缓存只要查询出来会把300个字段都放到缓存中,可是我们只需要20个字段,我们就不需要把300个查出来。所以对象缓存就是把对应的数据库表中的所有字段都缓存,在某些场合,这样很浪费效率。显然用一级缓存和二级缓存就不好了。
查询缓存也叫数据缓存,内存(页面)中需要多少数据就缓存多少数据,解决的是一张表的部分字段的缓存问题。
只要一些数据放入到查询缓存中,该缓存会一直存在,直到缓存中的数据被修改,该缓存的生命周期就结束了
SessionFactoryImpl中的QueryCache queryCache和UpdateTimestampsCache updateTimestampsCache;

由这两个对象构成了查询缓存。
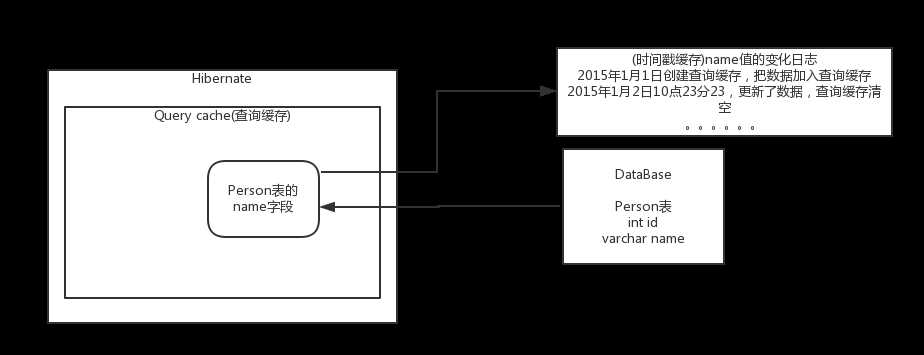
cacheRegion: 缓存的名字
updateTimestampsCache:时间戳缓存,Hibernate通过时间戳来判断 数据是否更新了
1.在hibernate.cfg.xml的配置文件开启查询缓存
<property name="cache.use_query_cache">true</property>
2.使用查询缓存
@Test
public void testList(){
sessionFactory=getSessionFactory();
Session session=sessionFactory.openSession();
Query query=session.createQuery("from domain.Person");
query.setCacheable(true);//query要使用查询缓存
query.list();//把数据放入查询缓存中
session.close();
session=sessionFactory.openSession();
query=session.createQuery("from domain.Person");
query.setCacheable(true);//query要使用查询缓存
query.list();//把数据放入查询缓存中
session.close();
}
Hibernate中总共有三种缓存:
一级缓存解决的问题:在一次请求尽量减少与数据库交互的次数,在session.flush()之前,改变的是一级缓存对象的属性,当session.flush()之后,才会和数据库交互。
一级缓存解决不了的问题:重复查询的问题,查询一次session就关闭,一级缓存就没有了
二级缓存解决的问题:经常不改变,常用的,公共的数据让入进来,可以进行重复查询,利用get()和iterator()得到二级缓存的数据
查询缓存解决的问题:可以缓存数据或对象,可以利用list()把查询缓存中的数据放入到缓存中,查询缓存中存放的数据是数据缓存
标签:
原文地址:http://www.cnblogs.com/xingdongpai/p/5092551.html