标签:
转自:http://blog.csdn.net/zdy0_2004/article/details/44652323
linux死锁检测的一种思路 http://www.cnblogs.com/mumuxinfei/p/4365697.html 前言: 上一篇博文讲述了pstack的使用和原理. 和jstack一样, pstack能获取进程的线程堆栈快照, 方便检验和性能评估. 但jstack功能更加的强大, 它能对潜在的死锁予以提示, 而pstack只提供了线索, 需要gdb进一步的确定. 那Linux下, 如何去检测死锁, 如何让死锁的检测能够更加的智能和方便? 这是本文的核心主旨, 让我们一同分享下思路. 常规做法: 我们来模拟一个出现死锁的程序, 然后通过常规方式来确定是否出现了死锁, 以及在那些线程上出现的. 如下是经典的死锁程序: 注: 线程A获取锁1, 线程B获取锁2, 然后线程A/B分别去获取锁2/1, 两者谁也不松手的, 又不得对方的, 于是duang, duang duang... 使用pstack来快速扫描堆栈: 发现有两个线程均在lock中等待, 存在死锁的嫌疑, 需要gdb后具体确认. 图文解读: 线程10800申请mutex_1(此时被线程10799所有), 而线程10799申请mutex_2(被线程10800所有), 于是线程10800在等待线程10799的释放, 而线程10799在等待线程10800的释放, 于是我们可以确定发生死锁了. 但这种方式, 需要开发人员自己去验证和排除, 复杂的案例就并不轻松了. 在gdb中, 我们可以只能看到mutex对应的线程, 却无法反向获取到线程拥有的mutex列表, 如果有这个信息, 就像jstack工具那样, 获取对死锁的判定, 只要扫下堆栈信息, 就能基本的判定了. 检测模型: 对于死锁, 操作系统课程中, 着重讲述了其常规模型/检测算法/规避建议, 这边不再展开. 一言以蔽之: 死锁的发生, 必然意味着有向图(依赖关系)的构建存在环. 关于检测模型, 我们可以这么假定, 锁为有向边, 申请锁的线程A为起点, 拥有锁的线程B为终点. 这样就形成线程A到线程B的一条有向边. 而众多的锁(边)和线程(点), 就构成了一个有向图. 于是乎, 一个死锁检测的算法, 就转变为图论中有向图的环判断问题. 而该问题, 可以借助成熟的拓扑遍历算法轻易实现. //拓扑排序:可以测试一个有向图是否有环 void Graph::topsort( ) { Queue<Vertex> q; int counter = 0; q.makeEmpty( ); for each Vertex v if( v.indegree == 0 ) q.enqueue( v ); while( !q.isEmpty( ) ) { Vertex v = q.dequeue( ); counter++; for each Vertex w adjacent to v if( --w.indegree == 0 ) q.enqueue( w ); } if( counter != NUM_VERTICES ) throw CycleFoundException( ); } 解决方案: 检测模型的确定, 让人豁然开朗. 但如何落地实现, 成了另一个拦路虎. 让我们从反向获取线程拥有的锁列表这个思路出发, 如何去实现? 如果我们能像java反射一样, 拦截lock/unlock操作, 并添加汇报线程与锁关系的功能, 那自然能构建有向图. 进而实现自动检测死锁情况. 但是C/C++没有反射, 不过可以在所有的lock/unlock代码处添加桩代码, 并得以解决. 但这对使用方的代码具有侵入性, 能否改善呢? 上天总是眷顾勤奋的人, 这边我们可以借助宏扩展(宏不会递归展开, 这是关键)来巧妙实现这个功能. #include <sys/syscall.h> #define gettid() syscall(__NR_gettid) // 拦截lock, 添加before, after操作, 记录锁与线程的关系 #define pthread_mutex_lock(x) do { printf("before=>thread_id:%d apply mutex:%p\n", gettid(), x); pthread_mutex_lock(x); printf("after=>thread_id:%d acquire mutex:%p\n", gettid(), x); } while (false); // 拦截unlock, 添加after操作, 解除锁和线程的关系 #define pthread_mutex_unlock(x) do { pthread_mutex_unlock(x); printf("unlock=>thread_id: %d release mutex:%p\n", gettid(), x); } while(false); 注: gettid函数用于获取线程实际的id, 重名名的pthread_mutex_lock/pthread_mutex_unlock宏, 添加了对before/after拦截调用, 并汇报记录了锁与线程的关系. 我们可以对before/after操作, 进行实际的图构建和检测. 而且该宏替换, 轻松解决了代码侵入性的问题. 让我们在回忆jstack的使用, 猜测java就是借助反射, 轻松实现了类似的功能, 使得其能检测死锁情况. 检验效果: 有了上述的理论基础和思路后, 进行尝试和扩展. 这边写了一个简单的检测工具库, 使用非常的简单. 在需要检测的代码中, 引入dead_lock_stub.h头文件, 然后在main函数的开头加入 1 DeadLockGraphic::getInstance().start_check(); 实验效果如下: 样例代码的网盘地址如下: http://pan.baidu.com/s/1ntzHEeX
前言:
上一篇博文讲述了pstack的使用和原理. 和jstack一样, pstack能获取进程的线程堆栈快照, 方便检验和性能评估. 但jstack功能更加的强大, 它能对潜在的死锁予以提示, 而pstack只提供了线索, 需要gdb进一步的确定.
那Linux下, 如何去检测死锁, 如何让死锁的检测能够更加的智能和方便? 这是本文的核心主旨, 让我们一同分享下思路.
常规做法:
我们来模拟一个出现死锁的程序, 然后通过常规方式来确定是否出现了死锁, 以及在那些线程上出现的.
如下是经典的死锁程序: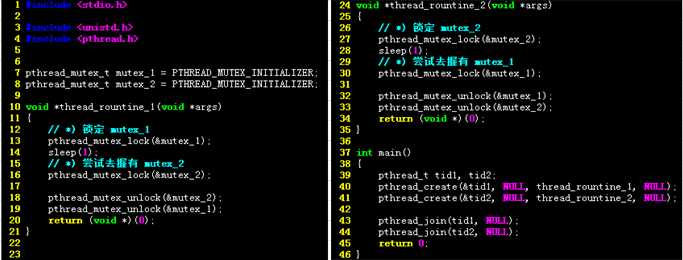
注: 线程A获取锁1, 线程B获取锁2, 然后线程A/B分别去获取锁2/1, 两者谁也不松手的, 又不得对方的, 于是duang, duang duang...
使用pstack来快速扫描堆栈:
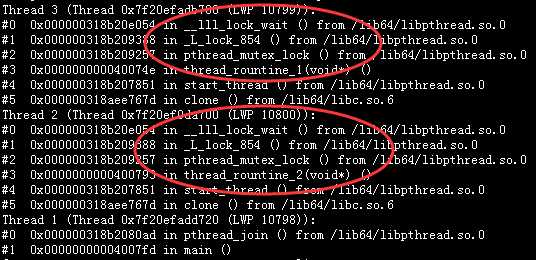
发现有两个线程均在lock中等待, 存在死锁的嫌疑, 需要gdb后具体确认.
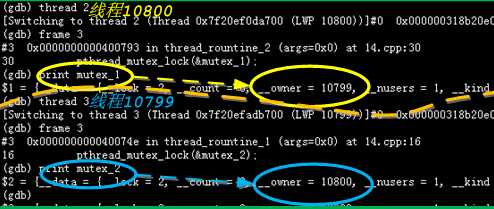
图文解读: 线程10800申请mutex_1(此时被线程10799所有), 而线程10799申请mutex_2(被线程10800所有), 于是线程10800在等待线程10799的释放, 而线程10799在等待线程10800的释放, 于是我们可以确定发生死锁了.
但这种方式, 需要开发人员自己去验证和排除, 复杂的案例就并不轻松了.
在gdb中, 我们可以只能看到mutex对应的线程, 却无法反向获取到线程拥有的mutex列表, 如果有这个信息, 就像jstack工具那样, 获取对死锁的判定, 只要扫下堆栈信息, 就能基本的判定了.
检测模型:
对于死锁, 操作系统课程中, 着重讲述了其常规模型/检测算法/规避建议, 这边不再展开.
一言以蔽之: 死锁的发生, 必然意味着有向图(依赖关系)的构建存在环.
关于检测模型, 我们可以这么假定, 锁为有向边, 申请锁的线程A为起点, 拥有锁的线程B为终点. 这样就形成线程A到线程B的一条有向边. 而众多的锁(边)和线程(点), 就构成了一个有向图.
于是乎, 一个死锁检测的算法, 就转变为图论中有向图的环判断问题. 而该问题, 可以借助成熟的拓扑遍历算法轻易实现.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
//拓扑排序:可以测试一个有向图是否有环 void Graph::topsort( ) { Queue<Vertex> q; int counter = 0; q.makeEmpty( ); for each Vertex v if( v.indegree == 0 ) q.enqueue( v ); while( !q.isEmpty( ) ) { Vertex v = q.dequeue( ); counter++; for each Vertex w adjacent to v if( --w.indegree == 0 ) q.enqueue( w ); } if( counter != NUM_VERTICES ) throw CycleFoundException( ); } |
解决方案:
检测模型的确定, 让人豁然开朗. 但如何落地实现, 成了另一个拦路虎.
让我们从反向获取线程拥有的锁列表这个思路出发, 如何去实现? 如果我们能像java反射一样, 拦截lock/unlock操作, 并添加汇报线程与锁关系的功能, 那自然能构建有向图. 进而实现自动检测死锁情况.
但是C/C++没有反射, 不过可以在所有的lock/unlock代码处添加桩代码, 并得以解决. 但这对使用方的代码具有侵入性, 能否改善呢?
上天总是眷顾勤奋的人, 这边我们可以借助宏扩展(宏不会递归展开, 这是关键)来巧妙实现这个功能.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
#include <sys/syscall.h>#define gettid() syscall(__NR_gettid)// 拦截lock, 添加before, after操作, 记录锁与线程的关系#define pthread_mutex_lock(x) \ do { \ printf("before=>thread_id:%d apply mutex:%p\n", gettid(), x); \ pthread_mutex_lock(x); \ printf("after=>thread_id:%d acquire mutex:%p\n", gettid(), x); \ } while (false);// 拦截unlock, 添加after操作, 解除锁和线程的关系#define pthread_mutex_unlock(x) \ do { \ pthread_mutex_unlock(x); \ printf("unlock=>thread_id: %d release mutex:%p\n", gettid(), x); \ } while(false); |
注: gettid函数用于获取线程实际的id, 重名名的pthread_mutex_lock/pthread_mutex_unlock宏, 添加了对before/after拦截调用, 并汇报记录了锁与线程的关系.
我们可以对before/after操作, 进行实际的图构建和检测. 而且该宏替换, 轻松解决了代码侵入性的问题.
让我们在回忆jstack的使用, 猜测java就是借助反射, 轻松实现了类似的功能, 使得其能检测死锁情况.
检验效果:
有了上述的理论基础和思路后, 进行尝试和扩展.
这边写了一个简单的检测工具库, 使用非常的简单.
在需要检测的代码中, 引入dead_lock_stub.h头文件, 然后在main函数的开头加入
|
1
|
DeadLockGraphic::getInstance().start_check(); |
实验效果如下:
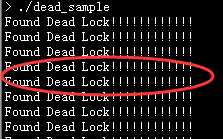
样例代码的网盘地址如下: http://pan.baidu.com/s/1ntzHEeX
标签:
原文地址:http://www.cnblogs.com/sky-heaven/p/5138370.html