标签:
Memcached 是一个高性能的分布式内存对象缓存系统,用于动态Web应用以减轻数据库负载。它通过在内存中缓存数据和对象来减少读取数据库的次数,从而提高动态、数据库驱动网站的速度。Memcached基于一个存储键/值对的hashmap。其守护进程(daemon )是用C写的,但是客户端可以用任何语言来编写,并通过memcached协议与守护进程通信。
1 wget http://memcached.org/latest 2 tar -zxvf memcached-1.x.x.tar.gz 3 cd memcached-1.x.x 4 ./configure && make && make test && sudo make install 5 6 PS:依赖libevent 7 yum install libevent-devel 8 apt-get install libevent-dev
1 memcached -d -m 10 -u root -l 10.211.55.4 -p 12000 -c 256 -P /tmp/memcached.pid 2 3 参数说明: 4 -d 是启动一个守护进程 5 -m 是分配给Memcache使用的内存数量,单位是MB 6 -u 是运行Memcache的用户 7 -l 是监听的服务器IP地址 8 -p 是设置Memcache监听的端口,最好是1024以上的端口 9 -c 选项是最大运行的并发连接数,默认是1024,按照你服务器的负载量来设定 10 -P 是设置保存Memcache的pid文件
1 存储命令: set/add/replace/append/prepend/cas 2 获取命令: get/gets 3 其他命令: delete/stats..
1 python操作Memcached使用Python-memcached模块 2 下载安装:https://pypi.python.org/pypi/python-memcached
1 import memcache 2 3 mc = memcache.Client([‘10.211.55.4:12000‘], debug=True) 4 mc.set("foo", "bar") 5 ret = mc.get(‘foo‘) 6 print ret

class Client(threading.local): """Object representing a pool of memcache servers. See L{memcache} for an overview. In all cases where a key is used, the key can be either: 1. A simple hashable type (string, integer, etc.). 2. A tuple of C{(hashvalue, key)}. This is useful if you want to avoid making this module calculate a hash value. You may prefer, for example, to keep all of a given user‘s objects on the same memcache server, so you could use the user‘s unique id as the hash value. @group Setup: __init__, set_servers, forget_dead_hosts, disconnect_all, debuglog @group Insertion: set, add, replace, set_multi @group Retrieval: get, get_multi @group Integers: incr, decr @group Removal: delete, delete_multi @sort: __init__, set_servers, forget_dead_hosts, disconnect_all, debuglog,\ set, set_multi, add, replace, get, get_multi, incr, decr, delete, delete_multi """ _FLAG_PICKLE = 1 << 0 _FLAG_INTEGER = 1 << 1 _FLAG_LONG = 1 << 2 _FLAG_COMPRESSED = 1 << 3 _SERVER_RETRIES = 10 # how many times to try finding a free server. # exceptions for Client class MemcachedKeyError(Exception): pass class MemcachedKeyLengthError(MemcachedKeyError): pass class MemcachedKeyCharacterError(MemcachedKeyError): pass class MemcachedKeyNoneError(MemcachedKeyError): pass class MemcachedKeyTypeError(MemcachedKeyError): pass class MemcachedStringEncodingError(Exception): pass def __init__(self, servers, debug=0, pickleProtocol=0, pickler=pickle.Pickler, unpickler=pickle.Unpickler, compressor=zlib.compress, decompressor=zlib.decompress, pload=None, pid=None, server_max_key_length=None, server_max_value_length=None, dead_retry=_DEAD_RETRY, socket_timeout=_SOCKET_TIMEOUT, cache_cas=False, flush_on_reconnect=0, check_keys=True): """Create a new Client object with the given list of servers. @param servers: C{servers} is passed to L{set_servers}. @param debug: whether to display error messages when a server can‘t be contacted. @param pickleProtocol: number to mandate protocol used by (c)Pickle. @param pickler: optional override of default Pickler to allow subclassing. @param unpickler: optional override of default Unpickler to allow subclassing. @param pload: optional persistent_load function to call on pickle loading. Useful for cPickle since subclassing isn‘t allowed. @param pid: optional persistent_id function to call on pickle storing. Useful for cPickle since subclassing isn‘t allowed. @param dead_retry: number of seconds before retrying a blacklisted server. Default to 30 s. @param socket_timeout: timeout in seconds for all calls to a server. Defaults to 3 seconds. @param cache_cas: (default False) If true, cas operations will be cached. WARNING: This cache is not expired internally, if you have a long-running process you will need to expire it manually via client.reset_cas(), or the cache can grow unlimited. @param server_max_key_length: (default SERVER_MAX_KEY_LENGTH) Data that is larger than this will not be sent to the server. @param server_max_value_length: (default SERVER_MAX_VALUE_LENGTH) Data that is larger than this will not be sent to the server. @param flush_on_reconnect: optional flag which prevents a scenario that can cause stale data to be read: If there‘s more than one memcached server and the connection to one is interrupted, keys that mapped to that server will get reassigned to another. If the first server comes back, those keys will map to it again. If it still has its data, get()s can read stale data that was overwritten on another server. This flag is off by default for backwards compatibility. @param check_keys: (default True) If True, the key is checked to ensure it is the correct length and composed of the right characters. """ super(Client, self).__init__() self.debug = debug self.dead_retry = dead_retry self.socket_timeout = socket_timeout self.flush_on_reconnect = flush_on_reconnect self.set_servers(servers) self.stats = {} self.cache_cas = cache_cas self.reset_cas() self.do_check_key = check_keys # Allow users to modify pickling/unpickling behavior self.pickleProtocol = pickleProtocol self.pickler = pickler self.unpickler = unpickler self.compressor = compressor self.decompressor = decompressor self.persistent_load = pload self.persistent_id = pid self.server_max_key_length = server_max_key_length if self.server_max_key_length is None: self.server_max_key_length = SERVER_MAX_KEY_LENGTH self.server_max_value_length = server_max_value_length if self.server_max_value_length is None: self.server_max_value_length = SERVER_MAX_VALUE_LENGTH # figure out the pickler style file = BytesIO() try: pickler = self.pickler(file, protocol=self.pickleProtocol) self.picklerIsKeyword = True except TypeError: self.picklerIsKeyword = False def _encode_key(self, key): if isinstance(key, tuple): if isinstance(key[1], six.text_type): return (key[0], key[1].encode(‘utf8‘)) elif isinstance(key, six.text_type): return key.encode(‘utf8‘) return key def _encode_cmd(self, cmd, key, headers, noreply, *args): cmd_bytes = cmd.encode() if six.PY3 else cmd fullcmd = [cmd_bytes, b‘ ‘, key] if headers: if six.PY3: headers = headers.encode() fullcmd.append(b‘ ‘) fullcmd.append(headers) if noreply: fullcmd.append(b‘ noreply‘) if args: fullcmd.append(b‘ ‘) fullcmd.extend(args) return b‘‘.join(fullcmd) def reset_cas(self): """Reset the cas cache. This is only used if the Client() object was created with "cache_cas=True". If used, this cache does not expire internally, so it can grow unbounded if you do not clear it yourself. """ self.cas_ids = {} def set_servers(self, servers): """Set the pool of servers used by this client. @param servers: an array of servers. Servers can be passed in two forms: 1. Strings of the form C{"host:port"}, which implies a default weight of 1. 2. Tuples of the form C{("host:port", weight)}, where C{weight} is an integer weight value. """ self.servers = [_Host(s, self.debug, dead_retry=self.dead_retry, socket_timeout=self.socket_timeout, flush_on_reconnect=self.flush_on_reconnect) for s in servers] self._init_buckets() def get_stats(self, stat_args=None): """Get statistics from each of the servers. @param stat_args: Additional arguments to pass to the memcache "stats" command. @return: A list of tuples ( server_identifier, stats_dictionary ). The dictionary contains a number of name/value pairs specifying the name of the status field and the string value associated with it. The values are not converted from strings. """ data = [] for s in self.servers: if not s.connect(): continue if s.family == socket.AF_INET: name = ‘%s:%s (%s)‘ % (s.ip, s.port, s.weight) elif s.family == socket.AF_INET6: name = ‘[%s]:%s (%s)‘ % (s.ip, s.port, s.weight) else: name = ‘unix:%s (%s)‘ % (s.address, s.weight) if not stat_args: s.send_cmd(‘stats‘) else: s.send_cmd(‘stats ‘ + stat_args) serverData = {} data.append((name, serverData)) readline = s.readline while 1: line = readline() if not line or line.strip() == ‘END‘: break stats = line.split(‘ ‘, 2) serverData[stats[1]] = stats[2] return(data) def get_slabs(self): data = [] for s in self.servers: if not s.connect(): continue if s.family == socket.AF_INET: name = ‘%s:%s (%s)‘ % (s.ip, s.port, s.weight) elif s.family == socket.AF_INET6: name = ‘[%s]:%s (%s)‘ % (s.ip, s.port, s.weight) else: name = ‘unix:%s (%s)‘ % (s.address, s.weight) serverData = {} data.append((name, serverData)) s.send_cmd(‘stats items‘) readline = s.readline while 1: line = readline() if not line or line.strip() == ‘END‘: break item = line.split(‘ ‘, 2) # 0 = STAT, 1 = ITEM, 2 = Value slab = item[1].split(‘:‘, 2) # 0 = items, 1 = Slab #, 2 = Name if slab[1] not in serverData: serverData[slab[1]] = {} serverData[slab[1]][slab[2]] = item[2] return data def flush_all(self): """Expire all data in memcache servers that are reachable.""" for s in self.servers: if not s.connect(): continue s.flush() def debuglog(self, str): if self.debug: sys.stderr.write("MemCached: %s\n" % str) def _statlog(self, func): if func not in self.stats: self.stats[func] = 1 else: self.stats[func] += 1 def forget_dead_hosts(self): """Reset every host in the pool to an "alive" state.""" for s in self.servers: s.deaduntil = 0 def _init_buckets(self): self.buckets = [] for server in self.servers: for i in range(server.weight): self.buckets.append(server) def _get_server(self, key): if isinstance(key, tuple): serverhash, key = key else: serverhash = serverHashFunction(key) if not self.buckets: return None, None for i in range(Client._SERVER_RETRIES): server = self.buckets[serverhash % len(self.buckets)] if server.connect(): # print("(using server %s)" % server,) return server, key serverhash = serverHashFunction(str(serverhash) + str(i)) return None, None def disconnect_all(self): for s in self.servers: s.close_socket() def delete_multi(self, keys, time=0, key_prefix=‘‘, noreply=False): """Delete multiple keys in the memcache doing just one query. >>> notset_keys = mc.set_multi({‘a1‘ : ‘val1‘, ‘a2‘ : ‘val2‘}) >>> mc.get_multi([‘a1‘, ‘a2‘]) == {‘a1‘ : ‘val1‘,‘a2‘ : ‘val2‘} >>> mc.delete_multi([‘key1‘, ‘key2‘]) >>> mc.get_multi([‘key1‘, ‘key2‘]) == {} This method is recommended over iterated regular L{delete}s as it reduces total latency, since your app doesn‘t have to wait for each round-trip of L{delete} before sending the next one. @param keys: An iterable of keys to clear @param time: number of seconds any subsequent set / update commands should fail. Defaults to 0 for no delay. @param key_prefix: Optional string to prepend to each key when sending to memcache. See docs for L{get_multi} and L{set_multi}. @param noreply: optional parameter instructs the server to not send the reply. @return: 1 if no failure in communication with any memcacheds. @rtype: int """ self._statlog(‘delete_multi‘) server_keys, prefixed_to_orig_key = self._map_and_prefix_keys( keys, key_prefix) # send out all requests on each server before reading anything dead_servers = [] rc = 1 for server in six.iterkeys(server_keys): bigcmd = [] write = bigcmd.append extra = ‘ noreply‘ if noreply else ‘‘ if time is not None: for key in server_keys[server]: # These are mangled keys write("delete %s %d%s\r\n" % (key, time, extra)) else: for key in server_keys[server]: # These are mangled keys write("delete %s%s\r\n" % (key, extra)) try: server.send_cmds(‘‘.join(bigcmd)) except socket.error as msg: rc = 0 if isinstance(msg, tuple): msg = msg[1] server.mark_dead(msg) dead_servers.append(server) # if noreply, just return if noreply: return rc # if any servers died on the way, don‘t expect them to respond. for server in dead_servers: del server_keys[server] for server, keys in six.iteritems(server_keys): try: for key in keys: server.expect("DELETED") except socket.error as msg: if isinstance(msg, tuple): msg = msg[1] server.mark_dead(msg) rc = 0 return rc def delete(self, key, time=0, noreply=False): ‘‘‘Deletes a key from the memcache. @return: Nonzero on success. @param time: number of seconds any subsequent set / update commands should fail. Defaults to None for no delay. @param noreply: optional parameter instructs the server to not send the reply. @rtype: int ‘‘‘ return self._deletetouch([b‘DELETED‘, b‘NOT_FOUND‘], "delete", key, time, noreply) def touch(self, key, time=0, noreply=False): ‘‘‘Updates the expiration time of a key in memcache. @return: Nonzero on success. @param time: Tells memcached the time which this value should expire, either as a delta number of seconds, or an absolute unix time-since-the-epoch value. See the memcached protocol docs section "Storage Commands" for more info on <exptime>. We default to 0 == cache forever. @param noreply: optional parameter instructs the server to not send the reply. @rtype: int ‘‘‘ return self._deletetouch([b‘TOUCHED‘], "touch", key, time, noreply) def _deletetouch(self, expected, cmd, key, time=0, noreply=False): key = self._encode_key(key) if self.do_check_key: self.check_key(key) server, key = self._get_server(key) if not server: return 0 self._statlog(cmd) if time is not None and time != 0: fullcmd = self._encode_cmd(cmd, key, str(time), noreply) else: fullcmd = self._encode_cmd(cmd, key, None, noreply) try: server.send_cmd(fullcmd) if noreply: return 1 line = server.readline() if line and line.strip() in expected: return 1 self.debuglog(‘%s expected %s, got: %r‘ % (cmd, ‘ or ‘.join(expected), line)) except socket.error as msg: if isinstance(msg, tuple): msg = msg[1] server.mark_dead(msg) return 0 def incr(self, key, delta=1, noreply=False): """Increment value for C{key} by C{delta} Sends a command to the server to atomically increment the value for C{key} by C{delta}, or by 1 if C{delta} is unspecified. Returns None if C{key} doesn‘t exist on server, otherwise it returns the new value after incrementing. Note that the value for C{key} must already exist in the memcache, and it must be the string representation of an integer. >>> mc.set("counter", "20") # returns 1, indicating success >>> mc.incr("counter") >>> mc.incr("counter") Overflow on server is not checked. Be aware of values approaching 2**32. See L{decr}. @param delta: Integer amount to increment by (should be zero or greater). @param noreply: optional parameter instructs the server to not send the reply. @return: New value after incrementing, no None for noreply or error. @rtype: int """ return self._incrdecr("incr", key, delta, noreply) def decr(self, key, delta=1, noreply=False): """Decrement value for C{key} by C{delta} Like L{incr}, but decrements. Unlike L{incr}, underflow is checked and new values are capped at 0. If server value is 1, a decrement of 2 returns 0, not -1. @param delta: Integer amount to decrement by (should be zero or greater). @param noreply: optional parameter instructs the server to not send the reply. @return: New value after decrementing, or None for noreply or error. @rtype: int """ return self._incrdecr("decr", key, delta, noreply) def _incrdecr(self, cmd, key, delta, noreply=False): key = self._encode_key(key) if self.do_check_key: self.check_key(key) server, key = self._get_server(key) if not server: return None self._statlog(cmd) fullcmd = self._encode_cmd(cmd, key, str(delta), noreply) try: server.send_cmd(fullcmd) if noreply: return line = server.readline() if line is None or line.strip() == b‘NOT_FOUND‘: return None return int(line) except socket.error as msg: if isinstance(msg, tuple): msg = msg[1] server.mark_dead(msg) return None def add(self, key, val, time=0, min_compress_len=0, noreply=False): ‘‘‘Add new key with value. Like L{set}, but only stores in memcache if the key doesn‘t already exist. @return: Nonzero on success. @rtype: int ‘‘‘ return self._set("add", key, val, time, min_compress_len, noreply) def append(self, key, val, time=0, min_compress_len=0, noreply=False): ‘‘‘Append the value to the end of the existing key‘s value. Only stores in memcache if key already exists. Also see L{prepend}. @return: Nonzero on success. @rtype: int ‘‘‘ return self._set("append", key, val, time, min_compress_len, noreply) def prepend(self, key, val, time=0, min_compress_len=0, noreply=False): ‘‘‘Prepend the value to the beginning of the existing key‘s value. Only stores in memcache if key already exists. Also see L{append}. @return: Nonzero on success. @rtype: int ‘‘‘ return self._set("prepend", key, val, time, min_compress_len, noreply) def replace(self, key, val, time=0, min_compress_len=0, noreply=False): ‘‘‘Replace existing key with value. Like L{set}, but only stores in memcache if the key already exists. The opposite of L{add}. @return: Nonzero on success. @rtype: int ‘‘‘ return self._set("replace", key, val, time, min_compress_len, noreply) def set(self, key, val, time=0, min_compress_len=0, noreply=False): ‘‘‘Unconditionally sets a key to a given value in the memcache. The C{key} can optionally be an tuple, with the first element being the server hash value and the second being the key. If you want to avoid making this module calculate a hash value. You may prefer, for example, to keep all of a given user‘s objects on the same memcache server, so you could use the user‘s unique id as the hash value. @return: Nonzero on success. @rtype: int @param time: Tells memcached the time which this value should expire, either as a delta number of seconds, or an absolute unix time-since-the-epoch value. See the memcached protocol docs section "Storage Commands" for more info on <exptime>. We default to 0 == cache forever. @param min_compress_len: The threshold length to kick in auto-compression of the value using the compressor routine. If the value being cached is a string, then the length of the string is measured, else if the value is an object, then the length of the pickle result is measured. If the resulting attempt at compression yeilds a larger string than the input, then it is discarded. For backwards compatability, this parameter defaults to 0, indicating don‘t ever try to compress. @param noreply: optional parameter instructs the server to not send the reply. ‘‘‘ return self._set("set", key, val, time, min_compress_len, noreply) def cas(self, key, val, time=0, min_compress_len=0, noreply=False): ‘‘‘Check and set (CAS) Sets a key to a given value in the memcache if it hasn‘t been altered since last fetched. (See L{gets}). The C{key} can optionally be an tuple, with the first element being the server hash value and the second being the key. If you want to avoid making this module calculate a hash value. You may prefer, for example, to keep all of a given user‘s objects on the same memcache server, so you could use the user‘s unique id as the hash value. @return: Nonzero on success. @rtype: int @param time: Tells memcached the time which this value should expire, either as a delta number of seconds, or an absolute unix time-since-the-epoch value. See the memcached protocol docs section "Storage Commands" for more info on <exptime>. We default to 0 == cache forever. @param min_compress_len: The threshold length to kick in auto-compression of the value using the compressor routine. If the value being cached is a string, then the length of the string is measured, else if the value is an object, then the length of the pickle result is measured. If the resulting attempt at compression yeilds a larger string than the input, then it is discarded. For backwards compatability, this parameter defaults to 0, indicating don‘t ever try to compress. @param noreply: optional parameter instructs the server to not send the reply. ‘‘‘ return self._set("cas", key, val, time, min_compress_len, noreply) def _map_and_prefix_keys(self, key_iterable, key_prefix): """Compute the mapping of server (_Host instance) -> list of keys to stuff onto that server, as well as the mapping of prefixed key -> original key. """ key_prefix = self._encode_key(key_prefix) # Check it just once ... key_extra_len = len(key_prefix) if key_prefix and self.do_check_key: self.check_key(key_prefix) # server (_Host) -> list of unprefixed server keys in mapping server_keys = {} prefixed_to_orig_key = {} # build up a list for each server of all the keys we want. for orig_key in key_iterable: if isinstance(orig_key, tuple): # Tuple of hashvalue, key ala _get_server(). Caller is # essentially telling us what server to stuff this on. # Ensure call to _get_server gets a Tuple as well. serverhash, key = orig_key key = self._encode_key(key) if not isinstance(key, six.binary_type): # set_multi supports int / long keys. key = str(key) if six.PY3: key = key.encode(‘utf8‘) bytes_orig_key = key # Gotta pre-mangle key before hashing to a # server. Returns the mangled key. server, key = self._get_server( (serverhash, key_prefix + key)) orig_key = orig_key[1] else: key = self._encode_key(orig_key) if not isinstance(key, six.binary_type): # set_multi supports int / long keys. key = str(key) if six.PY3: key = key.encode(‘utf8‘) bytes_orig_key = key server, key = self._get_server(key_prefix + key) # alert when passed in key is None if orig_key is None: self.check_key(orig_key, key_extra_len=key_extra_len) # Now check to make sure key length is proper ... if self.do_check_key: self.check_key(bytes_orig_key, key_extra_len=key_extra_len) if not server: continue if server not in server_keys: server_keys[server] = [] server_keys[server].append(key) prefixed_to_orig_key[key] = orig_key return (server_keys, prefixed_to_orig_key) def set_multi(self, mapping, time=0, key_prefix=‘‘, min_compress_len=0, noreply=False): ‘‘‘Sets multiple keys in the memcache doing just one query. >>> notset_keys = mc.set_multi({‘key1‘ : ‘val1‘, ‘key2‘ : ‘val2‘}) >>> mc.get_multi([‘key1‘, ‘key2‘]) == {‘key1‘ : ‘val1‘, ... ‘key2‘ : ‘val2‘} This method is recommended over regular L{set} as it lowers the number of total packets flying around your network, reducing total latency, since your app doesn‘t have to wait for each round-trip of L{set} before sending the next one. @param mapping: A dict of key/value pairs to set. @param time: Tells memcached the time which this value should expire, either as a delta number of seconds, or an absolute unix time-since-the-epoch value. See the memcached protocol docs section "Storage Commands" for more info on <exptime>. We default to 0 == cache forever. @param key_prefix: Optional string to prepend to each key when sending to memcache. Allows you to efficiently stuff these keys into a pseudo-namespace in memcache: >>> notset_keys = mc.set_multi( ... {‘key1‘ : ‘val1‘, ‘key2‘ : ‘val2‘}, ... key_prefix=‘subspace_‘) >>> len(notset_keys) == 0 True >>> mc.get_multi([‘subspace_key1‘, ... ‘subspace_key2‘]) == {‘subspace_key1‘: ‘val1‘, ... ‘subspace_key2‘ : ‘val2‘} True Causes key ‘subspace_key1‘ and ‘subspace_key2‘ to be set. Useful in conjunction with a higher-level layer which applies namespaces to data in memcache. In this case, the return result would be the list of notset original keys, prefix not applied. @param min_compress_len: The threshold length to kick in auto-compression of the value using the compressor routine. If the value being cached is a string, then the length of the string is measured, else if the value is an object, then the length of the pickle result is measured. If the resulting attempt at compression yeilds a larger string than the input, then it is discarded. For backwards compatability, this parameter defaults to 0, indicating don‘t ever try to compress. @param noreply: optional parameter instructs the server to not send the reply. @return: List of keys which failed to be stored [ memcache out of memory, etc. ]. @rtype: list ‘‘‘ self._statlog(‘set_multi‘) server_keys, prefixed_to_orig_key = self._map_and_prefix_keys( six.iterkeys(mapping), key_prefix) # send out all requests on each server before reading anything dead_servers = [] notstored = [] # original keys. for server in six.iterkeys(server_keys): bigcmd = [] write = bigcmd.append try: for key in server_keys[server]: # These are mangled keys store_info = self._val_to_store_info( mapping[prefixed_to_orig_key[key]], min_compress_len) if store_info: flags, len_val, val = store_info headers = "%d %d %d" % (flags, time, len_val) fullcmd = self._encode_cmd(‘set‘, key, headers, noreply, b‘\r\n‘, val, b‘\r\n‘) write(fullcmd) else: notstored.append(prefixed_to_orig_key[key]) server.send_cmds(b‘‘.join(bigcmd)) except socket.error as msg: if isinstance(msg, tuple): msg = msg[1] server.mark_dead(msg) dead_servers.append(server) # if noreply, just return early if noreply: return notstored # if any servers died on the way, don‘t expect them to respond. for server in dead_servers: del server_keys[server] # short-circuit if there are no servers, just return all keys if not server_keys: return(mapping.keys()) for server, keys in six.iteritems(server_keys): try: for key in keys: if server.readline() == ‘STORED‘: continue else: # un-mangle. notstored.append(prefixed_to_orig_key[key]) except (_Error, socket.error) as msg: if isinstance(msg, tuple): msg = msg[1] server.mark_dead(msg) return notstored def _val_to_store_info(self, val, min_compress_len): """Transform val to a storable representation. Returns a tuple of the flags, the length of the new value, and the new value itself. """ flags = 0 if isinstance(val, six.binary_type): pass elif isinstance(val, six.text_type): val = val.encode(‘utf-8‘) elif isinstance(val, int): flags |= Client._FLAG_INTEGER val = ‘%d‘ % val if six.PY3: val = val.encode(‘ascii‘) # force no attempt to compress this silly string. min_compress_len = 0 elif six.PY2 and isinstance(val, long): flags |= Client._FLAG_LONG val = str(val) if six.PY3: val = val.encode(‘ascii‘) # force no attempt to compress this silly string. min_compress_len = 0 else: flags |= Client._FLAG_PICKLE file = BytesIO() if self.picklerIsKeyword: pickler = self.pickler(file, protocol=self.pickleProtocol) else: pickler = self.pickler(file, self.pickleProtocol) if self.persistent_id: pickler.persistent_id = self.persistent_id pickler.dump(val) val = file.getvalue() lv = len(val) # We should try to compress if min_compress_len > 0 # and this string is longer than our min threshold. if min_compress_len and lv > min_compress_len: comp_val = self.compressor(val) # Only retain the result if the compression result is smaller # than the original. if len(comp_val) < lv: flags |= Client._FLAG_COMPRESSED val = comp_val # silently do not store if value length exceeds maximum if (self.server_max_value_length != 0 and len(val) > self.server_max_value_length): return(0) return (flags, len(val), val) def _set(self, cmd, key, val, time, min_compress_len=0, noreply=False): key = self._encode_key(key) if self.do_check_key: self.check_key(key) server, key = self._get_server(key) if not server: return 0 def _unsafe_set(): self._statlog(cmd) if cmd == ‘cas‘ and key not in self.cas_ids: return self._set(‘set‘, key, val, time, min_compress_len, noreply) store_info = self._val_to_store_info(val, min_compress_len) if not store_info: return(0) flags, len_val, encoded_val = store_info if cmd == ‘cas‘: headers = ("%d %d %d %d" % (flags, time, len_val, self.cas_ids[key])) else: headers = "%d %d %d" % (flags, time, len_val) fullcmd = self._encode_cmd(cmd, key, headers, noreply, b‘\r\n‘, encoded_val) try: server.send_cmd(fullcmd) if noreply: return True return(server.expect(b"STORED", raise_exception=True) == b"STORED") except socket.error as msg: if isinstance(msg, tuple): msg = msg[1] server.mark_dead(msg) return 0 try: return _unsafe_set() except _ConnectionDeadError: # retry once try: if server._get_socket(): return _unsafe_set() except (_ConnectionDeadError, socket.error) as msg: server.mark_dead(msg) return 0 def _get(self, cmd, key): key = self._encode_key(key) if self.do_check_key: self.check_key(key) server, key = self._get_server(key) if not server: return None def _unsafe_get(): self._statlog(cmd) try: cmd_bytes = cmd.encode() if six.PY3 else cmd fullcmd = b‘‘.join((cmd_bytes, b‘ ‘, key)) server.send_cmd(fullcmd) rkey = flags = rlen = cas_id = None if cmd == ‘gets‘: rkey, flags, rlen, cas_id, = self._expect_cas_value( server, raise_exception=True ) if rkey and self.cache_cas: self.cas_ids[rkey] = cas_id else: rkey, flags, rlen, = self._expectvalue( server, raise_exception=True ) if not rkey: return None try: value = self._recv_value(server, flags, rlen) finally: server.expect(b"END", raise_exception=True) except (_Error, socket.error) as msg: if isinstance(msg, tuple): msg = msg[1] server.mark_dead(msg) return None return value try: return _unsafe_get() except _ConnectionDeadError: # retry once try: if server.connect(): return _unsafe_get() return None except (_ConnectionDeadError, socket.error) as msg: server.mark_dead(msg) return None def get(self, key): ‘‘‘Retrieves a key from the memcache. @return: The value or None. ‘‘‘ return self._get(‘get‘, key) def gets(self, key): ‘‘‘Retrieves a key from the memcache. Used in conjunction with ‘cas‘. @return: The value or None. ‘‘‘ return self._get(‘gets‘, key) def get_multi(self, keys, key_prefix=‘‘): ‘‘‘Retrieves multiple keys from the memcache doing just one query. >>> success = mc.set("foo", "bar") >>> success = mc.set("baz", 42) >>> mc.get_multi(["foo", "baz", "foobar"]) == { ... "foo": "bar", "baz": 42 ... } >>> mc.set_multi({‘k1‘ : 1, ‘k2‘ : 2}, key_prefix=‘pfx_‘) == [] This looks up keys ‘pfx_k1‘, ‘pfx_k2‘, ... . Returned dict will just have unprefixed keys ‘k1‘, ‘k2‘. >>> mc.get_multi([‘k1‘, ‘k2‘, ‘nonexist‘], ... key_prefix=‘pfx_‘) == {‘k1‘ : 1, ‘k2‘ : 2} get_mult [ and L{set_multi} ] can take str()-ables like ints / longs as keys too. Such as your db pri key fields. They‘re rotored through str() before being passed off to memcache, with or without the use of a key_prefix. In this mode, the key_prefix could be a table name, and the key itself a db primary key number. >>> mc.set_multi({42: ‘douglass adams‘, ... 46: ‘and 2 just ahead of me‘}, ... key_prefix=‘numkeys_‘) == [] >>> mc.get_multi([46, 42], key_prefix=‘numkeys_‘) == { ... 42: ‘douglass adams‘, ... 46: ‘and 2 just ahead of me‘ ... } This method is recommended over regular L{get} as it lowers the number of total packets flying around your network, reducing total latency, since your app doesn‘t have to wait for each round-trip of L{get} before sending the next one. See also L{set_multi}. @param keys: An array of keys. @param key_prefix: A string to prefix each key when we communicate with memcache. Facilitates pseudo-namespaces within memcache. Returned dictionary keys will not have this prefix. @return: A dictionary of key/value pairs that were available. If key_prefix was provided, the keys in the retured dictionary will not have it present. ‘‘‘ self._statlog(‘get_multi‘) server_keys, prefixed_to_orig_key = self._map_and_prefix_keys( keys, key_prefix) # send out all requests on each server before reading anything dead_servers = [] for server in six.iterkeys(server_keys): try: fullcmd = b"get " + b" ".join(server_keys[server]) server.send_cmd(fullcmd) except socket.error as msg: if isinstance(msg, tuple): msg = msg[1] server.mark_dead(msg) dead_servers.append(server) # if any servers died on the way, don‘t expect them to respond. for server in dead_servers: del server_keys[server] retvals = {} for server in six.iterkeys(server_keys): try: line = server.readline() while line and line != b‘END‘: rkey, flags, rlen = self._expectvalue(server, line) # Bo Yang reports that this can sometimes be None if rkey is not None: val = self._recv_value(server, flags, rlen) # un-prefix returned key. retvals[prefixed_to_orig_key[rkey]] = val line = server.readline() except (_Error, socket.error) as msg: if isinstance(msg, tuple): msg = msg[1] server.mark_dead(msg) return retvals def _expect_cas_value(self, server, line=None, raise_exception=False): if not line: line = server.readline(raise_exception) if line and line[:5] == b‘VALUE‘: resp, rkey, flags, len, cas_id = line.split() return (rkey, int(flags), int(len), int(cas_id)) else: return (None, None, None, None) def _expectvalue(self, server, line=None, raise_exception=False): if not line: line = server.readline(raise_exception) if line and line[:5] == b‘VALUE‘: resp, rkey, flags, len = line.split() flags = int(flags) rlen = int(len) return (rkey, flags, rlen) else: return (None, None, None) def _recv_value(self, server, flags, rlen): rlen += 2 # include \r\n buf = server.recv(rlen) if len(buf) != rlen: raise _Error("received %d bytes when expecting %d" % (len(buf), rlen)) if len(buf) == rlen: buf = buf[:-2] # strip \r\n if flags & Client._FLAG_COMPRESSED: buf = self.decompressor(buf) flags &= ~Client._FLAG_COMPRESSED if flags == 0: # Bare string if six.PY3: val = buf.decode(‘utf8‘) else: val = buf elif flags & Client._FLAG_INTEGER: val = int(buf) elif flags & Client._FLAG_LONG: if six.PY3: val = int(buf) else: val = long(buf) elif flags & Client._FLAG_PICKLE: try: file = BytesIO(buf) unpickler = self.unpickler(file) if self.persistent_load: unpickler.persistent_load = self.persistent_load val = unpickler.load() except Exception as e: self.debuglog(‘Pickle error: %s\n‘ % e) return None else: self.debuglog("unknown flags on get: %x\n" % flags) raise ValueError(‘Unknown flags on get: %x‘ % flags) return val def check_key(self, key, key_extra_len=0): """Checks sanity of key. Fails if: Key length is > SERVER_MAX_KEY_LENGTH (Raises MemcachedKeyLength). Contains control characters (Raises MemcachedKeyCharacterError). Is not a string (Raises MemcachedStringEncodingError) Is an unicode string (Raises MemcachedStringEncodingError) Is not a string (Raises MemcachedKeyError) Is None (Raises MemcachedKeyError) """ if isinstance(key, tuple): key = key[1] if key is None: raise Client.MemcachedKeyNoneError("Key is None") if key is ‘‘: if key_extra_len is 0: raise Client.MemcachedKeyNoneError("Key is empty") # key is empty but there is some other component to key return if not isinstance(key, six.binary_type): raise Client.MemcachedKeyTypeError("Key must be a binary string") if (self.server_max_key_length != 0 and len(key) + key_extra_len > self.server_max_key_length): raise Client.MemcachedKeyLengthError( "Key length is > %s" % self.server_max_key_length ) if not valid_key_chars_re.match(key): raise Client.MemcachedKeyCharacterError( "Control/space characters not allowed (key=%r)" % key)
redis是一个key-value存储系统。和Memcached类似,它支持存储的value类型相对更多,包括string(字符串)、list(链表)、set(集合)、zset(sorted set --有序集合)和hash(哈希类型)。这些数据类型都支持push/pop、add/remove及取交集并集和差集及更丰富的操作,而且这些操作都是原子性的。在此基础上,redis支持各种不同方式的排序。与memcached一样,为了保证效率,数据都是缓存在内存中。区别的是redis会周期性的把更新的数据写入磁盘或者把修改操作写入追加的记录文件,并且在此基础上实现了master-slave(主从)同步。
wget http://download.redis.io/releases/redis-3.0.6.tar.gz tar xzf redis-3.0.6.tar.gz cd redis-3.0.6 make make install
1 redis-server
1 redis-cli 2 redis> set foo bar 3 OK 4 redis> get foo 5 "bar"
1 sudo pip install redis 2 or 3 sudo easy_install redis 4 or 5 源码安装 6 7 详见:https://github.com/WoLpH/redis-py
redis-py提供两个类Redis和StrictRedis用于实现Redis的命令,StrictRedis用于实现大部分官方的命令,并使用官方的语法和命令,Redis是StrictRedis的子类,用于向后兼容旧版本的redis-py。
#!/usr/bin/env python # -*- coding:utf-8 -*- import redis r = redis.Redis(host=‘192.168.1.1‘, port=6379) r.set(‘foo‘, ‘Bar‘) print r.get(‘foo‘)
redis-py使用connection pool来管理对一个redis server的所有连接,避免每次建立、释放连接的开销。默认,每个Redis实例都会维护一个自己的连接池。可以直接建立一个连接池,然后作为参数Redis,这样就可以实现多个Redis实例共享一个连接池。
#!/usr/bin/env python # -*- coding:utf-8 -*- import redis pool = redis.ConnectionPool(host=‘192.168.1.1‘, port=6379) r = redis.Redis(connection_pool=pool) r.set(‘foo‘, ‘Bar‘) print r.get(‘foo‘)
redis-py默认在执行每次请求都会创建(连接池申请连接)和断开(归还连接池)一次连接操作,如果想要在一次请求中指定多个命令,则可以使用pipline实现一次请求指定多个命令,并且默认情况下一次pipline 是原子性操作。
#!/usr/bin/env python # -*- coding:utf-8 -*- import redis pool = redis.ConnectionPool(host=‘192.168.1.1‘, port=6379) r = redis.Redis(connection_pool=pool) # pipe = r.pipeline(transaction=False) pipe = r.pipeline(transaction=True) r.set(‘name‘, ‘alex‘) r.set(‘role‘, ‘sb‘) pipe.execute()
#!/usr/bin/env python # -*- coding:utf-8 -*- import redis class RedisHelper: def __init__(self): self.__conn = redis.Redis(host=‘192.168.1.1‘) self.chan_sub = ‘fm104.5‘ self.chan_pub = ‘fm104.5‘ def public(self, msg): self.__conn.publish(self.chan_pub, msg) return True def subscribe(self): pub = self.__conn.pubsub() pub.subscribe(self.chan_sub) pub.parse_response() return pub
1 #!/usr/bin/env python 2 # -*- coding:utf-8 -*- 3 4 from monitor.RedisHelper import RedisHelper 5 6 obj = RedisHelper() 7 redis_sub = obj.subscribe() 8 9 while True: 10 msg= redis_sub.parse_response() 11 print msg
1 #!/usr/bin/env python 2 # -*- coding:utf-8 -*- 3 4 from monitor.RedisHelper import RedisHelper 5 6 obj = RedisHelper() 7 obj.public(‘hello‘)
更多参见:https://github.com/andymccurdy/redis-py/
RabbitMQ是一个在AMQP基础上完整的,可复用的企业消息系统。他遵循Mozilla Public License开源协议。
MQ全称为Message Queue, 消息队列(MQ)是一种应用程序对应用程序的通信方法。应用程序通过读写出入队列的消息(针对应用程序的数据)来通信,而无需专用连接来链接它们。消 息传递指的是程序之间通过在消息中发送数据进行通信,而不是通过直接调用彼此来通信,直接调用通常是用于诸如远程过程调用的技术。排队指的是应用程序通过 队列来通信。队列的使用除去了接收和发送应用程序同时执行的要求。
1 安装配置epel源 2 $ rpm -ivh http://dl.fedoraproject.org/pub/epel/6/i386/epel-release-6-8.noarch.rpm 3 4 安装erlang 5 $ yum -y install erlang 6 7 安装RabbitMQ 8 $ yum -y install rabbitmq-server
注意:service rabbitmq-server start/stop
1 pip install pika 2 or 3 easy_install pika 4 or 5 源码 6 7 https://pypi.python.org/pypi/pika
#!/usr/bin/env python # -*- coding:utf-8 -*- import Queue import threading message = Queue.Queue(10) def producer(i): while True: message.put(i) def consumer(i): while True: msg = message.get() for i in range(12): t = threading.Thread(target=producer, args=(i,)) t.start() for i in range(10): t = threading.Thread(target=consumer, args=(i,)) t.start()
对于RabbitMQ来说,生产和消费不再针对内存里的一个Queue对象,而是某台服务器上的RabbitMQ Server实现的消息队列。
# ######################### 生产者 ######################### #!/usr/bin/env python import pika connection = pika.BlockingConnection(pika.ConnectionParameters( host=‘localhost‘)) channel = connection.channel() channel.queue_declare(queue=‘hello‘) channel.basic_publish(exchange=‘‘, routing_key=‘hello‘, body=‘Hello World!‘) print(" [x] Sent ‘Hello World!‘") connection.close() # ########################## 消费者 ########################## #!/usr/bin/env python import pika connection = pika.BlockingConnection(pika.ConnectionParameters( host=‘localhost‘)) channel = connection.channel() channel.queue_declare(queue=‘hello‘) def callback(ch, method, properties, body): print(" [x] Received %r" % body) channel.basic_consume(callback, queue=‘hello‘, no_ack=True) print(‘ [*] Waiting for messages. To exit press CTRL+C‘) channel.start_consuming()
no-ack = False,如果生产者遇到情况(its channel is closed, connection is closed, or TCP connection is lost)挂掉了,那么,RabbitMQ会重新将该任务添加到队列中。
import pika connection = pika.BlockingConnection(pika.ConnectionParameters( host=‘192.168.1.1‘)) channel = connection.channel() channel.queue_declare(queue=‘hello‘) def callback(ch, method, properties, body): print(" [x] Received %r" % body) import time time.sleep(10) print ‘ok‘ ch.basic_ack(delivery_tag = method.delivery_tag) channel.basic_consume(callback, queue=‘hello‘, no_ack=False) print(‘ [*] Waiting for messages. To exit press CTRL+C‘) channel.start_consuming() 消费者
#!/usr/bin/env python import pika connection = pika.BlockingConnection(pika.ConnectionParameters(host=‘192.168.1.1‘)) channel = connection.channel() # make message persistent channel.queue_declare(queue=‘hello‘, durable=True) channel.basic_publish(exchange=‘‘, routing_key=‘hello‘, body=‘Hello World!‘, properties=pika.BasicProperties( delivery_mode=2, # make message persistent )) print(" [x] Sent ‘Hello World!‘") connection.close() 生产者
#!/usr/bin/env python # -*- coding:utf-8 -*- import pika connection = pika.BlockingConnection(pika.ConnectionParameters(host=‘192.168.1.1‘)) channel = connection.channel() # make message persistent channel.queue_declare(queue=‘hello‘, durable=True) def callback(ch, method, properties, body): print(" [x] Received %r" % body) import time time.sleep(10) print ‘ok‘ ch.basic_ack(delivery_tag = method.delivery_tag) channel.basic_consume(callback, queue=‘hello‘, no_ack=False) print(‘ [*] Waiting for messages. To exit press CTRL+C‘) channel.start_consuming() 消费者
默认消息队列里的数据是按照顺序被消费者拿走,例如:消费者1 去队列中获取 奇数 序列的任务,消费者1去队列中获取 偶数 序列的任务。
channel.basic_qos(prefetch_count=1) 表示谁来谁取,不再按照奇偶数排列
#!/usr/bin/env python # -*- coding:utf-8 -*- import pika connection = pika.BlockingConnection(pika.ConnectionParameters(host=‘192.168.1.1‘)) channel = connection.channel() # make message persistent channel.queue_declare(queue=‘hello‘) def callback(ch, method, properties, body): print(" [x] Received %r" % body) import time time.sleep(10) print ‘ok‘ ch.basic_ack(delivery_tag = method.delivery_tag) channel.basic_qos(prefetch_count=1) channel.basic_consume(callback, queue=‘hello‘, no_ack=False) print(‘ [*] Waiting for messages. To exit press CTRL+C‘) channel.start_consuming() 消费者
发布订阅和简单的消息队列区别在于,发布订阅会将消息发送给所有的订阅者,而消息队列中的数据被消费一次便消失。所以,RabbitMQ实现发布和订阅时,会为每一个订阅者创建一个队列,而发布者发布消息时,会将消息放置在所有相关队列中。
exchange type = fanout
#!/usr/bin/env python import pika import sys connection = pika.BlockingConnection(pika.ConnectionParameters( host=‘localhost‘)) channel = connection.channel() channel.exchange_declare(exchange=‘logs‘, type=‘fanout‘) message = ‘ ‘.join(sys.argv[1:]) or "info: Hello World!" channel.basic_publish(exchange=‘logs‘, routing_key=‘‘, body=message) print(" [x] Sent %r" % message) connection.close() 发布者
#!/usr/bin/env python import pika connection = pika.BlockingConnection(pika.ConnectionParameters( host=‘localhost‘)) channel = connection.channel() channel.exchange_declare(exchange=‘logs‘, type=‘fanout‘) result = channel.queue_declare(exclusive=True) queue_name = result.method.queue channel.queue_bind(exchange=‘logs‘, queue=queue_name) print(‘ [*] Waiting for logs. To exit press CTRL+C‘) def callback(ch, method, properties, body): print(" [x] %r" % body) channel.basic_consume(callback, queue=queue_name, no_ack=True) channel.start_consuming() 订阅者
exchange type = direct
之前事例,发送消息时明确指定某个队列并向其中发送消息,RabbitMQ还支持根据关键字发送,即:队列绑定关键字,发送者将数据根据关键字发送到消息exchange,exchange根据 关键字 判定应该将数据发送至指定队列。
#!/usr/bin/env python import pika import sys connection = pika.BlockingConnection(pika.ConnectionParameters( host=‘192.168.1.1‘)) channel = connection.channel() channel.exchange_declare(exchange=‘direct_logs‘, type=‘direct‘) result = channel.queue_declare(exclusive=True) queue_name = result.method.queue severities = sys.argv[1:] if not severities: sys.stderr.write("Usage: %s [info] [warning] [error]\n" % sys.argv[0]) sys.exit(1) for severity in severities: channel.queue_bind(exchange=‘direct_logs‘, queue=queue_name, routing_key=severity) print(‘ [*] Waiting for logs. To exit press CTRL+C‘) def callback(ch, method, properties, body): print(" [x] %r:%r" % (method.routing_key, body)) channel.basic_consume(callback, queue=queue_name, no_ack=True) channel.start_consuming() 消费者
#!/usr/bin/env python import pika import sys connection = pika.BlockingConnection(pika.ConnectionParameters( host=‘192.168.1.1‘)) channel = connection.channel() channel.exchange_declare(exchange=‘direct_logs‘, type=‘direct‘) severity = sys.argv[1] if len(sys.argv) > 1 else ‘info‘ message = ‘ ‘.join(sys.argv[2:]) or ‘Hello World!‘ channel.basic_publish(exchange=‘direct_logs‘, routing_key=severity, body=message) print(" [x] Sent %r:%r" % (severity, message)) connection.close() 生产者
exchange type = topic
在topic类型下,可以让队列绑定几个模糊的关键字,之后发送者将数据发送到exchange,exchange将传入”路由值“和 ”关键字“进行匹配,匹配成功,则将数据发送到指定队列。
1 发送者路由值 队列中 2 old.boy.python old.* -- 不匹配 3 old.boy.python old.# -- 匹配
#!/usr/bin/env python import pika import sys connection = pika.BlockingConnection(pika.ConnectionParameters( host=‘192.168.1.1‘)) channel = connection.channel() channel.exchange_declare(exchange=‘topic_logs‘, type=‘topic‘) result = channel.queue_declare(exclusive=True) queue_name = result.method.queue binding_keys = sys.argv[1:] if not binding_keys: sys.stderr.write("Usage: %s [binding_key]...\n" % sys.argv[0]) sys.exit(1) for binding_key in binding_keys: channel.queue_bind(exchange=‘topic_logs‘, queue=queue_name, routing_key=binding_key) print(‘ [*] Waiting for logs. To exit press CTRL+C‘) def callback(ch, method, properties, body): print(" [x] %r:%r" % (method.routing_key, body)) channel.basic_consume(callback, queue=queue_name, no_ack=True) channel.start_consuming() 消费者
#!/usr/bin/env python import pika import sys connection = pika.BlockingConnection(pika.ConnectionParameters( host=‘192.168.1.1‘)) channel = connection.channel() channel.exchange_declare(exchange=‘topic_logs‘, type=‘topic‘) routing_key = sys.argv[1] if len(sys.argv) > 1 else ‘anonymous.info‘ message = ‘ ‘.join(sys.argv[2:]) or ‘Hello World!‘ channel.basic_publish(exchange=‘topic_logs‘, routing_key=routing_key, body=message) print(" [x] Sent %r:%r" % (routing_key, message)) connection.close() 生产者
SQLAlchemy是Python编程语言下的一款ORM框架,该框架建立在数据库API之上,使用关系对象映射进行数据库操作,简言之便是:将对象转换成SQL,然后使用数据API执行SQL并获取执行结果。
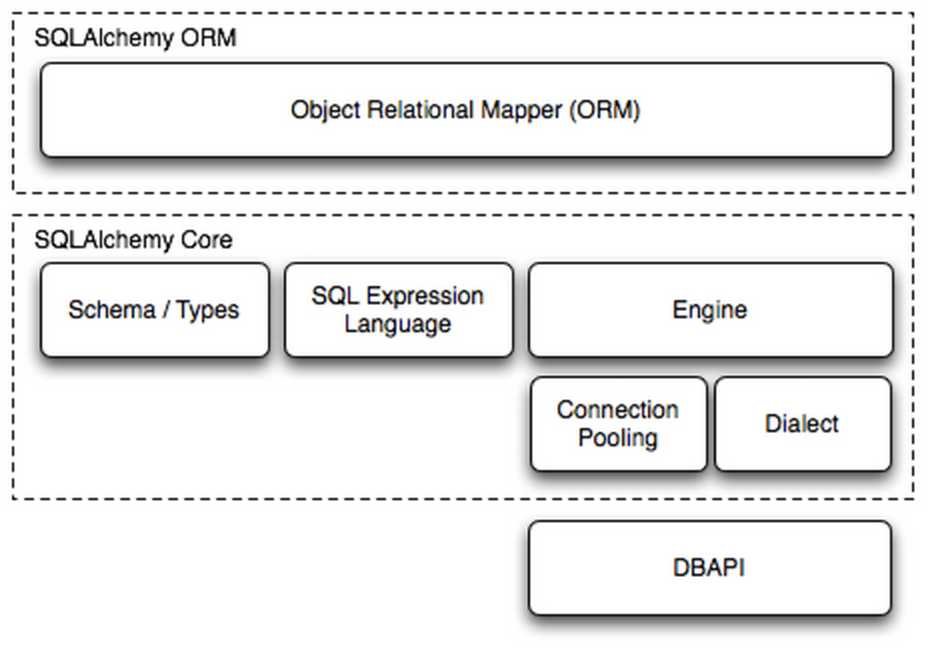
Dialect用于和数据API进行交流,根据配置文件的不同调用不同的数据库API,从而实现对数据库的操作,如:
1 MySQL-Python 2 mysql+mysqldb://<user>:<password>@<host>[:<port>]/<dbname> 3 4 pymysql 5 mysql+pymysql://<username>:<password>@<host>/<dbname>[?<options>] 6 7 MySQL-Connector 8 mysql+mysqlconnector://<user>:<password>@<host>[:<port>]/<dbname> 9 10 cx_Oracle 11 oracle+cx_oracle://user:pass@host:port/dbname[?key=value&key=value...] 12 13 更多详见:http://docs.sqlalchemy.org/en/latest/dialects/index.html
使用 Engine/ConnectionPooling/Dialect 进行数据库操作,Engine使用ConnectionPooling连接数据库,然后再通过Dialect执行SQL语句。
1 #!/usr/bin/env python 2 # -*- coding:utf-8 -*- 3 4 from sqlalchemy import create_engine 5 6 7 engine = create_engine("mysql+mysqldb://root:123@127.0.0.1:3306/s11", max_overflow=5) 8 9 engine.execute( 10 "INSERT INTO ts_test (a, b) VALUES (‘2‘, ‘v1‘)" 11 ) 12 13 engine.execute( 14 "INSERT INTO ts_test (a, b) VALUES (%s, %s)", 15 ((555, "v1"),(666, "v1"),) 16 ) 17 engine.execute( 18 "INSERT INTO ts_test (a, b) VALUES (%(id)s, %(name)s)", 19 id=999, name="v1" 20 ) 21 22 result = engine.execute(‘select * from ts_test‘) 23 result.fetchall()
#!/usr/bin/env python # -*- coding:utf-8 -*- from sqlalchemy import create_engine engine = create_engine("mysql+mysqldb://root:123@127.0.0.1:3306/s11", max_overflow=5) # 事务操作 with engine.begin() as conn: conn.execute("insert into table (x, y, z) values (1, 2, 3)") conn.execute("my_special_procedure(5)") conn = engine.connect() # 事务操作 with conn.begin(): conn.execute("some statement", {‘x‘:5, ‘y‘:10}) 事务操作
注:查看数据库连接:show status like ‘Threads%‘;
使用 Schema Type/SQL Expression Language/Engine/ConnectionPooling/Dialect 进行数据库操作。Engine使用Schema Type创建一个特定的结构对象,之后通过SQL Expression Language将该对象转换成SQL语句,然后通过 ConnectionPooling 连接数据库,再然后通过 Dialect 执行SQL,并获取结果。
#!/usr/bin/env python # -*- coding:utf-8 -*- from sqlalchemy import create_engine, Table, Column, Integer, String, MetaData, ForeignKey metadata = MetaData() user = Table(‘user‘, metadata, Column(‘id‘, Integer, primary_key=True), Column(‘name‘, String(20)), ) color = Table(‘color‘, metadata, Column(‘id‘, Integer, primary_key=True), Column(‘name‘, String(20)), ) engine = create_engine("mysql+mysqldb://root:123@127.0.0.1:3306/s11", max_overflow=5) metadata.create_all(engine) # metadata.clear() # metadata.remove()
#!/usr/bin/env python # -*- coding:utf-8 -*- from sqlalchemy import create_engine, Table, Column, Integer, String, MetaData, ForeignKey metadata = MetaData() user = Table(‘user‘, metadata, Column(‘id‘, Integer, primary_key=True), Column(‘name‘, String(20)), ) color = Table(‘color‘, metadata, Column(‘id‘, Integer, primary_key=True), Column(‘name‘, String(20)), ) engine = create_engine("mysql+mysqldb://root:123@127.0.0.1:3306/s11", max_overflow=5) conn = engine.connect() # 创建SQL语句,INSERT INTO "user" (id, name) VALUES (:id, :name) conn.execute(user.insert(),{‘id‘:7,‘name‘:‘seven‘}) conn.close() # sql = user.insert().values(id=123, name=‘wu‘) # conn.execute(sql) # conn.close() # sql = user.delete().where(user.c.id > 1) # sql = user.update().values(fullname=user.c.name) # sql = user.update().where(user.c.name == ‘jack‘).values(name=‘ed‘) # sql = select([user, ]) # sql = select([user.c.id, ]) # sql = select([user.c.name, color.c.name]).where(user.c.id==color.c.id) # sql = select([user.c.name]).order_by(user.c.name) # sql = select([user]).group_by(user.c.name) # result = conn.execute(sql) # print result.fetchall() # conn.close() 增删改查
更多内容详见:
http://www.jianshu.com/p/e6bba189fcbd ----中文
http://docs.sqlalchemy.org/en/latest/core/expression_api.html ---官方英文
注:SQLAlchemy无法修改表结构,如果需要可以使用SQLAlchemy开发者开源的另外一个软件Alembic来完成。
使用 ORM/Schema Type/SQL Expression Language/Engine/ConnectionPooling/Dialect 所有组件对数据进行操作。根据类创建对象,对象转换成SQL,执行SQL。
1 #!/usr/bin/env python 2 # -*- coding:utf-8 -*- 3 4 from sqlalchemy.ext.declarative import declarative_base 5 from sqlalchemy import Column, Integer, String 6 from sqlalchemy.orm import sessionmaker 7 from sqlalchemy import create_engine 8 9 engine = create_engine("mysql+mysqldb://root:123@127.0.0.1:3306/s11", max_overflow=5) 10 11 Base = declarative_base() 12 13 14 class User(Base): 15 __tablename__ = ‘users‘ 16 id = Column(Integer, primary_key=True) 17 name = Column(String(50)) 18 19 # 寻找Base的所有子类,按照子类的结构在数据库中生成对应的数据表信息 20 # Base.metadata.create_all(engine) 21 22 Session = sessionmaker(bind=engine) 23 session = Session() 24 25 26 # ########## 增 ########## 27 # u = User(id=2, name=‘sb‘) 28 # session.add(u) 29 # session.add_all([ 30 # User(id=3, name=‘sb‘), 31 # User(id=4, name=‘sb‘) 32 # ]) 33 # session.commit() 34 35 # ########## 删除 ########## 36 # session.query(User).filter(User.id > 2).delete() 37 # session.commit() 38 39 # ########## 修改 ########## 40 # session.query(User).filter(User.id > 2).update({‘cluster_id‘ : 0}) 41 # session.commit() 42 # ########## 查 ########## 43 # ret = session.query(User).filter_by(name=‘sb‘).first() 44 45 # ret = session.query(User).filter_by(name=‘sb‘).all() 46 # print ret 47 48 # ret = session.query(User).filter(User.name.in_([‘sb‘,‘bb‘])).all() 49 # print ret 50 51 # ret = session.query(User.name.label(‘name_label‘)).all() 52 # print ret,type(ret) 53 54 # ret = session.query(User).order_by(User.id).all() 55 # print ret 56 57 # ret = session.query(User).order_by(User.id)[1:3] 58 # print ret 59 # session.commit()
更多功能参见文档,猛击这里下载PDF
参考:http://www.cnblogs.com/wupeiqi/articles/5132791.html
Python操作 RabbitMQ、Redis、Memcache、SQLAlchemy
标签:
原文地址:http://www.cnblogs.com/fanweibin/p/5138630.html
