标签:
SQL 不同于与其他编程语言的最明显特征是处理代码的顺序。在大数编程语言中,代码按编码顺序被处理,但是在SQL语言中,第一个被处理的子句是FROM子句,尽管SELECT语句第一个出现,但是几乎总是最后被处理。
每个步骤都会产生一个虚拟表,该虚拟表被用作下一个步骤的输入。这些虚拟表对调用者(客户端应用程序或者外部查询)不可用。只是最后一步生成的表才会返回给调用者。如果没有在查询中指定某一子句,将跳过相应的步骤。
首先,对应用于SQL server 2000和SQL Server 2005的各个逻辑步骤的简单描述:
(8) SELECT (9) DISTINCT (11) <TOP_specification> <select_list> (1) FROM <left_table> (3) <join_type> JOIN <right_table> (2) ON <join_condition> (4) WHERE <where_condition> (5) GROUP BY <group_by_list> (6) WITH {CUBE | ROLLUP} (7) HAVING <having_condition> (10) ORDER BY <order_by_list>
逻辑查询处理阶段简介
注:步骤10,按ORDER BY子句中的列列表排序上步返回的行,返回游标VC10。这一步是第一步也是唯一一步可以使用SELECT列表中的列别名的步骤。这一步不同于其它步骤的 是,它不返回有效的表,而是返回一个游标。SQL是基于集合理论的。集合不会预先对它的行排序,它只是成员的逻辑集合,成员的顺序无关紧要。对表进行排序 的查询可以返回一个对象,包含按特定物理顺序组织的行。ANSI把这种对象称为游标。理解这一步是正确理解SQL的基础。
因为这一步不返回表(而是返回游标),使用了ORDER BY子句的查询不能用作表表达式。表表达式包括:视图、内联表值函数、子查询、派生表和共用表达式。它的结果必须返回给期望得到物理记录的客户端应用程序。
例如,下面的派生表查询无效,并产生一个错误:
select * from(select orderid,customerid from orders order by orderid) as d
下面的视图也会产生错误
create view my_view as select * from orders order by orderid
在SQL中,表表达式中不允许使用带有ORDER BY子句的查询,而在T—SQL中却有一个例外(应用TOP选项)。
所以要记住,不要为表中的行假设任何特定的顺序。换句话说,除非你确定要有序行,否则不要指定ORDER BY 子句。排序是需要成本的,SQL Server需要执行有序索引扫描或使用排序运行符。
二、在SQL Server 2008版本中,则对逻辑阶段的描述扩展到了所有的逻辑语句,而不仅仅是联接处理,如APPLY、PIVOT等。按这种分类方式,将逻辑步骤分成了6部分,部分步骤中包含了子步骤。
(5)SELECT (5-2)DISTINCT (5-3)<TOP_specification> (5-1)<select_list> (1)FROM (1-J) <left_table> <join_type> JOIN <right_table> ON <join_condition> |(1-A) <left_table> <apply_type> APPLY <right_table_expression> AS <alias> |(1-P) <left_table> PIVOT(<pivot_specifications>) AS <alias> |(1-U) <left_table> UNPIVOT(<unpivot_specifications>) AS <alias> (2)WHERE <where_condition> (3)GROUP BY <group_by_list> (3-CR)WITH {CUBE | ROLLUP} (4)HAVING <having_condition> (6)ORDER BY <order_by_list>
下图更详细地描述了各个处理步骤的流程:
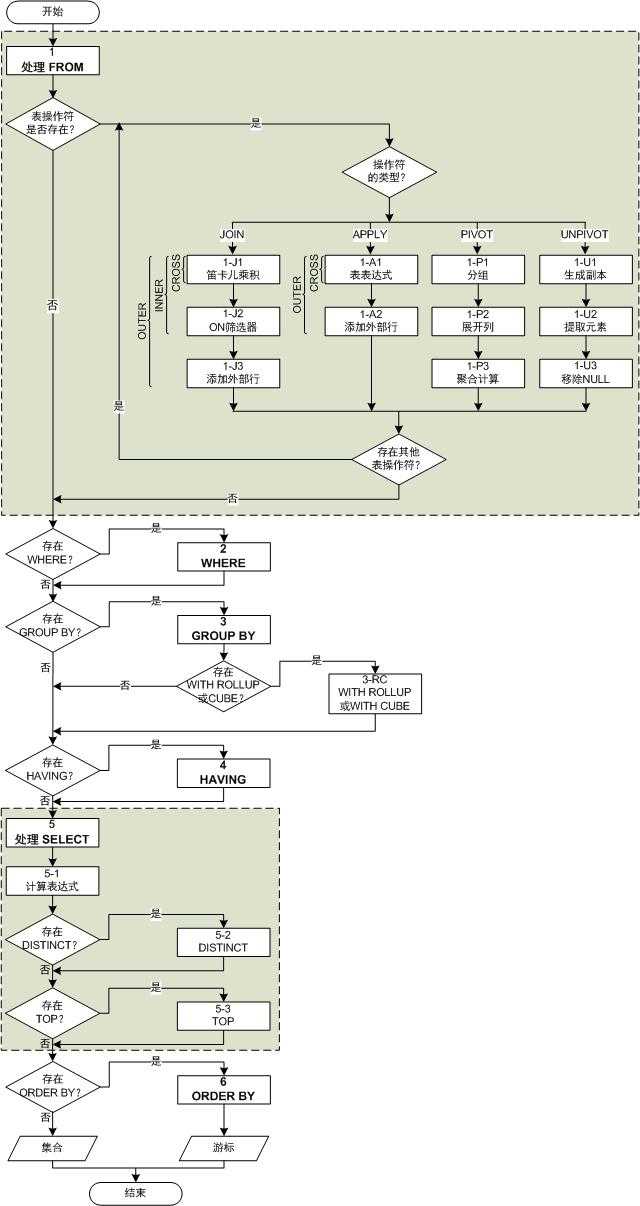
这种步骤分类相比2005版本而言更加全面和具体。上面步骤中的3-CR是我添加上去的,我觉得这样的描述更加全面。3-CR中的WITH ROLLUP和WITH CUBE参数,在SQL Server 2008中已经被GROUP BY子句的GROUPING SETS、ROLLUP和CUBE运算符代替,不再推荐使用不符合ISO标准的WITH ROLLUP、WITH CUBE和ALL语法。但是,这并不影响逻辑处理的顺序。
下面是对逻辑处理过程中各个步骤的说明,请注意虚拟表(VTn)的生成步骤:
1. FROM:该步骤中用于验证查询的源表,并处理表操作符。每个表操作符应用于一系列子步骤。例如,在上面用于联接的(1-J)步骤中会涉及如下的子步骤。最终这些子步骤完成后,将生成虚拟表VT1。
[1] (1-J1):执行left_table和right_table两个表的交叉联接(笛卡儿乘积),生成虚拟表VT1-J1;
[2] (1-J2):对笛卡儿乘积应用ON筛选器,生成虚拟表VT1-J2;
[3] (1-J3):如果是外部联接,会在该步骤中将被ON筛选掉的外部行添加到VT1-J2中,生成VT1-J3。否则,将跳过该步骤。
2. WHERE:对VT1应用WHERE筛选器,将符合筛选条件的行插入到VT2中。
3. GROUP BY:按GROUP BY子句中的列列表对VT2中的行分组,生成VT3。如果语句中包含WITH CUBE或WITH ROLLUP,则将分组统计结果再次加总后插入VT3,生成VT3-RC。
4. HAVING:对VT3应用HAVING筛选器,将符合筛选条件的行插入到VT4。
· 步骤5(SELECT):处理SELECT子句中的元素,生成VT5。
u (5-1)计算表达式:该步骤计算SELECT列表中的表达式,生成VT5-1;
u (5-2)DISTINCT:从VT5-1中移除重复行,生成VT5-2;
u (5-3)TOP:该步骤根据ORDER BY子句中指定的排序规则,从VT5-2的开始处筛选出指定数量或比例的行。
· 步骤6(ORDER BY):该步骤对VT5-3中的行按ORDER BY子句中的列列表进行排序,生成一个游标VC6。
标签:
原文地址:http://www.cnblogs.com/xinaixia/p/5138671.html