首页
Web开发
Windows程序
编程语言
数据库
移动开发
系统相关
微信
其他好文
会员
首页
>
编程语言
> 详细
python爬取并下载麦子学院所有视频教程
时间:
2016-01-18 20:45:58
阅读:
211
评论:
0
收藏:
0
[点我收藏+]
标签:
一、主要思路
scrapy爬取是有课程地址及名称
使用multiprocessing进行下载
就是为了爬点视频,所以是简单的代码堆砌
想而未实行,进行共享的方式
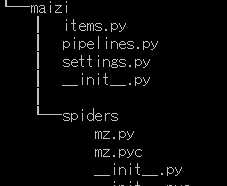
二、文件说明
itemsscray字段
piplines.py存储数据库
setting.py scrapy配置 需要注意的是
DEFAULT_REQUEST_HEADERS的设置,需要模拟登录
mz.py是主要爬虫 都是基本的爬虫功能,css+xpath+正则
start_urls = [
"http://www.maiziedu.com/course/web/"
, ]只爬了web的,可根据需要进行,或者全部,
本想不存储进数据库,直接在mz.py进行下载,但考虑到位会影响scrapy原有的性能,单独进行下载
down.py 使用multiprocessing进行下载 原本想着动态监听scrapy在数据库的中的结果,想实现进程的共享,调试多次还出现问题所以直接用Pool.Map()这种比较粗暴的方式,
mz.json现存取进json,但考虑到来回操作json文件,影响效率,所以改用数据库
三、结果
源码 :https://yunpan.cn/crjn7J97xUD8F 访问密码 6219
视频地址:
https://yunpan.cn/crjXKLGnkpzPk 访问密码 6c15
来自为知笔记(Wiz)
python爬取并下载麦子学院所有视频教程
标签:
原文地址:http://www.cnblogs.com/yinsolence/p/5140297.html
踩
(
0
)
赞
(
0
)
举报
评论
一句话评论(
0
)
登录后才能评论!
分享档案
更多>
2021年07月29日 (22)
2021年07月28日 (40)
2021年07月27日 (32)
2021年07月26日 (79)
2021年07月23日 (29)
2021年07月22日 (30)
2021年07月21日 (42)
2021年07月20日 (16)
2021年07月19日 (90)
2021年07月16日 (35)
周排行
更多
Spring Cloud 从入门到精通(一)Nacos 服务中心初探
2021-07-29
基础的排序算法
2021-07-29
SpringBoot|常用配置介绍
2021-07-29
关于 .NET 与 JAVA 在 JIT 编译上的一些差异
2021-07-29
C语言常用函数-toupper()将字符转换为大写英文字母函数
2021-07-29
《手把手教你》系列技巧篇(十)-java+ selenium自动化测试-元素定位大法之By class name(详细教程)
2021-07-28
4-1 YAML配置文件 注入 JavaBean中
2021-07-28
【python】 用来将对象持久化的 pickle 模块
2021-07-28
马拉车算法
2021-07-28
用Python进行冒泡排序
2021-07-28
友情链接
兰亭集智
国之画
百度统计
站长统计
阿里云
chrome插件
新版天听网
关于我们
-
联系我们
-
留言反馈
© 2014
mamicode.com
版权所有 联系我们:gaon5@hotmail.com
迷上了代码!

 https://yunpan.cn/crjXKLGnkpzPk 访问密码 6c15
https://yunpan.cn/crjXKLGnkpzPk 访问密码 6c15