标签:
接近两个星期的奋战,nagios的安装搭建以及监控服务自动报警功能终于基本得以实现,现在自己整理一份安装技术手册,方便自己以后查阅和回顾。
接近两个星期的奋战,nagios的安装搭建以及监控服务自动报警功能终于基本得以实现,现在自己整理一份安装技术手册,方便自己以后查阅和回顾。
|
主机名 |
操作系统 |
IP |
作用 |
|
Nagios-Server |
Centos5.4 |
211.162.127.51 |
监控机 |
|
211.162.127.43 |
Centos5.4 |
211.162.127.43 |
被监控机 |
nagios的功能是监控服务和主机,但是他自身并不包括这部分功能的代码,所有的监控、检测功能都是有插件来完成的。
再说报警功能,如果监控系统发现问题不能报警那就没有意义了,所以报警也是nagios很重要的功能之一。但是,同样的,nagios自身也没有报警部分的代码,甚至没有插件,而是交给用户或者其他相关开源项目组去完成。
nagios安装,是指基本平台,也就是nagios软件包的安装。它是监控体系的框架,也是所有监控的基础。
打开nagios官方的文档,会发现nagios基本上没有什么依赖包,只要求系统是linux或者其他nagios支持的系统。不过如果你没有安装apache(httpd服务),那么你就没有那么直观的界面来查看监控信息了,所以apache姑且算是一个前提条件。关于apache的安装,网上有很多,照着安装就是了。安装之后要检查一下是否可以正常工作。
nagios定义了4中监控状态,代表不同的严重级别,除了OK代表正常不用关心外,其余3种都要引起重视.如下表:
|
状态 |
代码 |
颜色 |
|
正常 |
OK |
绿色, |
|
警告 |
WARNING |
黄色, |
|
严重 |
CRITICAL |
红色, |
|
未知错误 |
UNKOWN |
深黄色 |
1.Nagios-4.1.1.tar.gz (Nagios主程序软件包)
[root@nagios~]#wget http://jaist.dl.sourceforge.net/project/nagios/nagios-4.x/nagios-4.1.1/nagios-4.1.1.tar.gz
2.Nagios-plugins-2.1.1.tar.gz (Nagios 插件)
[root@nagios~]#wget http://nagios-plugins.org/download/nagios-plugins-2.1.1.tar.gz
3.nrpe-2.12.tar.gz (Nagios 代理检测程序)
[root@nagios~]#wget http://jaist.dl.sourceforge.net/project/nagios/nrpe-2.x/nrpe-2.15/nrpe-2.15.tar.gz
4.NSClient++-0.2.7.zip(用于监控windows系统所需的软件)
http://sourceforge.net/projects/nscplus/
[root@nagios~] # ls
nagios-4.1.1.tar.gz nagios-plugins-2.1.1.tar.gz nrpe-2.15.tar.gz
1.安装前所依赖性包的安装
[root@nagios~]# yum -y install httpd php gcc glibc glibc-common gd gd-devel
2.创建nagios用户和组
[root@nagios~]# useradd -m nagios
[root@nagios~]# groupadd nagcmd
[root@nagios~]# usermod -a -G nagcmd nagios
[root@nagios~]# usermod -a -G nagcmd apache
3.编译安装nagios
[root@nagios~]# tar -zxvf nagios-4.1.1.tar.gz
[root@nagios~]# cd nagios-4.1.1
[root@nagios-4.1.1]#./configure--with-command-group=nagcmd\ --with-nagios-user=nagios \ --with-nagios-group=nagios --prefix=/usr/local/nagios
(红色部分命令可敲可不敲,指定nagios安装目录)
[root@ nagios-4.1.1]# make all
[root@ nagios-4.1.1]# make install
[root@nagios-4.1.1]# make install-init
[root@nagios-4.1.1]# make install-config
[root@nagios-4.1.1]# make install-commandmode
[root@nagios-4.1.1]# make install-webconf (生成apache配置文件nagios.conf)
4.为nagios生成web验证密码
[root@nagios-4.1.1]# htpasswd -c /usr/local/nagios/etc/htpasswd.users nagiosadmin
5.设置nagios开机启动
chkconfig --add nagios
chkconfig nagios on
chkconfig --add httpd
chkconfig httpd on
6.修改selinux
两种方法:
第一种就是直接关闭selinux, 把selinux设置成disabled状态,使用getenforce能查看到当前selinux的状态,0为关闭,1为打开。
[root@nagios-4.1.1]# vim /etc/sysconfig/selinux
SELINUX=disabled
插件是nagios扩展功能的强大武器,一般好的软件,都支持插件的扩展,你可以根据实际需求,自己开发插件。
[root@nagios~]# tar -zxvf nagios-plugins-2.1.1.tar.gz
[root@nagios~]#cd nagios-plugins-2.1.1
[root@nagios-plugins-2.1.1]#./configure --prefix=/usr/local/nagios --with-nagios-user=nagios --with-nagios-group=nagios
[root@nagios-plugins-2.1.1]# make&&make install
[root@nagios~]# cd /usr/local/nagios
[root@nagios nagios]# ls -l
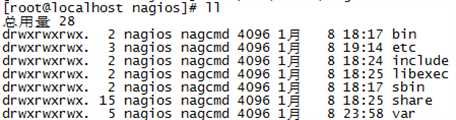
成功安装后在/usr/local/nagios目录下可见这几个文件夹,其中etc为配置文件目录,插件都安装在libexec目录下,var为存放nagios服务日志目录。下面我们进入etc目录来配置检测主机是否存活
[root@nagios nagios]# cd etc/
[root@nagios etc]# ls -l

Etc目录下可见cgi.cfg、htpasswd.users、nagios.cfg、objects、resource.cfg这五个文件与目录.
Cgi.cfg (CGI配置文件)
htpasswd.users (Apache的用户验证密码文件)
Nagios.cfg (主配置文件)
objects (对象定义文件目录)
Resource.cfg(资源配置文件)
Nagios自己定义了一套规则用于配置文件,其中最重要的概念就是”对象”----object.通俗的理解:假定我们首先定义了”性别”这个对象,它的值只可能是男,女,人妖等等,然后定义某人为一个对象,例如张三,定义张三的时候有”性别”这个属性,它的值就必须来源了之前定义的性别这个对象,要么是男是女,或者是人妖.
在Nagios里面定义了一些基本的对象,一般用到的有:
|
联系人 |
contact |
出了问题像谁报告?一般当然是系统管理员了 |
|
监控时间段 |
timeperiod |
7X24小时不间断还是周一至周五,或是自定义的其他时间段 |
|
被监控主机 |
host |
所需要监控的服务器,当然可以是监控机自己 |
|
监控命令 |
command |
nagios发出的哪个指令来执行某个监控,这也是自己定义的 |
|
被监控的服务 |
service |
例如主机是否存活,80端口是否开,磁盘使用情况或者自定义的服务等 |
另外,多个被监控主机可以定义为一个主机组,多个联系人可以被定义为一个联系人组,多个服务还能定义成一个服务组呢.
回到上面的例子,定义张三需要之前定义的性别,我们定义一个被监控的服务,当然就要指定被监控的主机,需要监控的时间段,要用哪个命令来完成这个监控操作,出了问题向哪个联系人报告.
所有这些对象绝对多数都是需要我们手动定义的,这就是nagios的安装显得复杂的地方.下面我们来配置nagios主配置文件。
[root@nagios etc]#vim nagios.cfg

此处是定义了nagios日志存放的位置,默认为这个位置可以不用改它。
cfg_file=/usr/local/nagios/etc/objects/commands.cfg (命令定义文件) cfg_file=/usr/local/nagios/etc/objects/contacts.cfg (联系人信息定义文件) cfg_file=/usr/local/nagios/etc/objects/contactgroups.cfg (添加此行联系人组定义文件) cfg_file=/usr/local/nagios/etc/objects/hosts.cfg (添加此行主机定义文件) cfg_file=/usr/local/nagios/etc/objects/hostgroups.cfg (添加此行主机组定义文件) cfg_file=/usr/local/nagios/etc/objects/services.cfg (添加此行服务定义文件) cfg_file=/usr/local/nagios/etc/objects/timeperiods.cfg (时间周期定义文件) cfg_file=/usr/local/nagios/etc/objects/templates.cfg
#difinations for monitoring the local (linux)host
#cfg_file=/usr/local/nagios/etc/objects/localhost.cfg (注释掉此行)
注释掉了就说明不读取这个文件里的配置,取消注释就说明nagios将读取这个文件里的配置。此处将localhost.cfg文件注释,说明所有主机配置都将读取objects目录中hosts.cfg当中定义的主机。
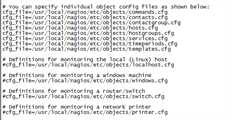
改check_external_commands=0为check_external_commands=1 .这行的作用是允许在web界面下执行重启nagios、停止主机/服务检查等操作。
把command_check_interval的值从默认的1改成command_check_interval=10s(根据自己的情况定这个命令检查时间间隔,不要太长也不要太短)。
主配置文件要改的基本上就是这些,但是/usr/local/nagios/etc/objects中并没有文件hosts.cfg等一些文件,稍后手动创建它们。(在nagios.cfg中配置的参数其实还有很多,像service_check_timeout,enable_notifications=1 开启报警通知,确保nagios_user=nagios,nagios_group=nagios等,这些以后再说)
(二)脚本控制文件cgi.cfg的配置
[root@nagios etc]# vim cgi.cfg
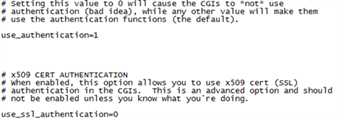 |
Cgi.cfg的作用是控制相关cgi脚本,先确保use_authentication=1,default_user_name=***这句可以不用定义,默认是注释掉的,看命令解释说地定义有风险。
.files/image006.png) |
authorized_for_system_information=nagiosadmin,test
authorized_for_configuration_information=nagiosadmin,test
authorized_for_system_commands=nagiosadmin,test //多个用户之间用逗号隔开
authorized_for_all_services=nagiosadmin,test
authorized_for_all_hosts=nagiosadmin,test
authorized_for_all_service_commands=nagiosadmin,test
authorized_for_all_host_commands=nagiosadmin,test
上述的用户名就是之前使用htpasswd -c /usr/local/nagios/etc/htpasswd.users nagiosadmin生成的nagiosadmin用户,由此操作可同样创建出上述test用户。在此就不做过多说明了。不过这个要注意,请不要随便添加不存在的验证用户,并且为了安全起见,不要添加过多的验证用户。
(三)主机定义文件hosts.cfg的配置
[root@nagios etc]# cd objects/
[root@nagios objects]# vim hosts.cfg 此处没有hosts.cfg文件,直接vim编辑创建即可
.files/image007.png)
define host{
host_name Nagios-Server
//被监控主机的名称,最好别带空格用tab键来分隔
alias Nagios Server
//别名
address 211.162.127.51
//被监控主机的IP地址,我现在暂时先填本机的IP
check_command check-host-alive
//监控的命令check-host-alive,这个命令来自commands.cfg,用来监控主机是否存活
max_check_attempts 5
//检查失败后重试的次数
check_period 24x7
//检查的时间段24x7,来自于在timeperiods.cfg中定义的
contact_groups sagroup
//联系人组,上面在contactgroup.cfg中定义的sagroup
notification_interval 10
//提醒的间隔,每隔10秒提醒一次
notification_period 24x7
//提醒的周期, 24x7,同样来自于我们之前在timeperiods.cfg中定义的
notification_options d,u,r
//指定什么情况下提醒,具体含义见之前contacts.cfg部分的介绍
}
211.162.127.43主机定义同上,就不一一详细说明了。
(四)主机组定义文件hostgroups.cfg的配置
[root@nagios objects]#vim hostgroups.cfg
.files/image008.png)
此处添加之前已定义好的主机名就行了,不同主机名之间用逗号隔开。
(五)监控时间段文件timeperiods.cfg的配置
[root@nagios objects]#vim timeperiods.cfg
.files/image009.png)
关于其他时间段的定义我是全部注释掉了的,只留了24x7这个时间段的定义,按理来说这个应该是不需要的,假如使用命令检测配置文件出现报错情况的话就把其他时间命令定义都注释掉。
(六)联系人文件contacts.cfg的配置
[root@nagios objects]#vim contacts.cfg
.files/image010.jpg)
此处定义的就是出了问题应该通知谁,通常就是系统管理员,上图定义的就是当监控服务出现u(unknow)、c(critical)、r(从异常状态下恢复)或者主机出现d(down机)、u(unreachable)、r(从异常状态下恢复)的时候就会以notify-service和notify-host-by-sms命令定义的方式(此命令是在commands.cfg中定义的)向系统管理员发送报警通知,此处没有定义W警告级别。注意,contacts.cfg最下面也有关于contactgroup的模版,这里我们另外创建一个contactgroup.cfg联系组的文件,就不在联系人文件中定义联系组了,可以注释掉。
[root@nagios objects]#vim contactgroup.cfg
.files/image011.jpg)
定义联系组的组名为sagroup,组的成员来自于上面定义的contacts.cfg,如果有多个联系人则以逗号相隔。下面是最关键的了,用nagios主要是监控一台主机的各种信息,包括本机资源,对外的服务等等.这些在nagios里面都是被定义为一个个的项目(nagios称之为服务,为了与主机提供的服务相区别,我这里用项目这个词),而实现每个监控项目,则需要通过commands.cfg文件中定义的命令.
例如我们现在有一个监控项目是监控一台机器的web服务是否正常, 我们需要哪些元素呢?最重要的有下面三点:首先是监控哪台机,然后是这个监控要用什么命令实现,最后就是出了问题的时候要通知哪个联系人?
(八)服务定义文件services.cfg的配置
[root@nagios objects]#vim services.cfg
.files/image012.jpg)
以监控http服务为例,监控的主机为Nagios-Server这台主机,监控的时间段为24
x7这个时间段名命定的定义,引用的检查服务命令是commands.cfg里定义的check_tcp!80这个命令,就是去ping主机的80端口来检查http是否正常,发现ping不通后最大尝试次数为4次,包括重新检查间隔这些参数都是在timeperiods.cfg里定义的,自己可以修改。还有就是报警参数的设置也是自己按需求定义。(注意,这里最下面加了一句notifications_enabled 1是为了实现短信猫报警排错时加进去的,正常来说这句不需要加,因为nagios.cfg主配置文件里定义这句报警通知开关打开为1了)
.files/image013.png)
监控多个主机服务复制粘贴就行,只要把hostname改一下即可。上图只展示了监控host存活的配置,常用监控服务的配置在介绍监控插件安装配置的时候再贴出。
(九)修改目录的所有者测试web监控界面
[root@nagios~]# chown –R nagios:nagcmd /usr/local/nagios/etc/objects/
[root@nagios~]#/usr/local/nagios/bin/nagios–v/usr/local/nagios/etc/nagios.cfg 检测配置文件是否正确
.files/image014.jpg)
.files/image015.png)
如果都是0说明配置没有问题,如果有错误的话会有提示哪里出错,检查出错的配置文件。
[root@nagios~]#/etc/init.d/httpd restart
[root@nagios~]#/etc/init.d/nagios restart
在浏览器输入主监控机IP地址测试:http://211.162.127.51/nagios/
.files/image016.jpg)
要求用户名验证,就是之前htpasswd创建的web验证用户nagiosadmin,第一部分的功能已经实现了,就是简单的监控主机是否存活(上图那些check_disk、check_http这些服务是用安装插件以后监控起来的服务,到上述步骤完成时不会出现,只监控主机存活的话服务只有check-host-alive),当然,对于系统监控来说,这是远远不够的,对于来说,他的真正功能功能还没有发挥出来,在下面部分会详细的叙述。
nagios本身并没有监控的功能,所有的监控是由插件完成的,插件将监控的结果返回给nagios,nagios分析这些结果,以web的方式展现给我们,同时提供相应的报警功能(这个报警的功能也是由插件完成的)
所有的这些插件是一些实现特定功能的可执行程序,默认安装的路径是/usr/local/nagios/libexec
.files/image017.jpg)
或许在这里又迷糊了,我们在定义某个监控项目时,所用的监控命令都是来自commands.cfg的,这和这些插件有什么关系???想到了吧,commands.cfg中定义的监控命令就是使用的这些插件.举个例子,之前我们已经不止一次用到了check-host-alive这个命令,打开commands.cfg就可以看到这个命令的定义,如下:
|
################################################################################ # # SAMPLE HOST CHECK COMMANDS # ################################################################################ # This command checks to see if a host is "alive" by pinging it # The check must result in a 100% packet loss or 5 second (5000ms) round trip # average time to produce a critical error. # Note: Only one ICMP echo packet is sent (determined by the ‘-p 1‘ argument) # ‘check-host-alive‘ command definition define command{ command_name check-host-alive command_line $USER1$/check_ping -H $HOSTADDRESS$ -w 3000.0,80% -c 5000.0,100% -p 1 } |
command_name check-host-alive
这句话的意思是定义的命令名是check-host-alive,也就是我们在services.cfg中使用的名称
执行的操作是
$USER1$/check_ping -H $HOSTADDRESS$ -w 3000.0,80% -c 5000.0,100% -p 1
其中$USER1$是在resource.cfg文件中定义的,代表插件的安装路径.就如我们上面看到的那样$USER1$=/usr/local/nagios/libexec,至于$HOSTADDRESS$,则默认被定义为监控主机的地址.
简单的说,我们在services.cfg中定义了对Nagios-Server执行check-host-alive命令,实际上就是执行了
/usr/local/nagios/libexec/ check_ping -H Nagios-Server的ip地址 -w 3000.0,80% -c 5000.0,100% -p 1
实际上check-host-alive只是这一长串命令的简称而已,而在services.cfg中都是使用简称的.
在commands.cfg中定义了很多这样的命令简称.基本上我们常用的监控项目都包含了,例如ftp,http,本地的磁盘,负载等等.
我们再看一个命令,check_local_disk定义如下
|
# ‘check_local_disk‘ command definition define command{ command_name check_local_disk command_line $USER1$/check_disk -w $ARG1$ -c $ARG2$ -p $ARG3$ } |
check_local_disk实际上是执行的check_disk插件.这里的$ARG1$, $ARG2$, $ARG3$是什么意思呢?在之前我们已经提到了这个check_disk这个插件的用法,-w的参数指定磁盘剩了多少是警告状态,-c的参数指定剩多少是严重状态,-p用来指定路径.
在使用check-host-alive的时候,只需要在services.cfg中直接写上这个命令名check-host-alive.后面没任何的参数.而使用check_local_disk则不同,在services.cfg中这要这么写
check_local_disk!10%!5%!/
在命令名后面用!分隔出了3个参数,10%是$ARG1$的值,5%是$ARG2$的值,/ 是$ARG3$的值
简单的一句话就是
|
services.cfg定义监控项目用某个命令 ↓ 这个命令必须在commands.cfg中定义 ↓ 定义这个命令时使用了libexec下的插件 |
如果命令不带$ARG1$就可以在services.cfg中直接使用,如果带了使用时就带上参数,以!相隔
继续编辑services.cfg服务配置文件,添加需要监控的服务,基本上就是copy上节我们定义监控主机存活的配置,略作修改就行:
监控Nagios-Server的FTP服务
|
define service{ host_name Nagios-Server 要监控的机器,给出机器名,注意必须是hosts.cfg中定义的 service_description check ftp 给这个监控项目起个名字吧,任意起,你自己懂就行 check_command check_ftp 所用的命令,当然必须是commands.cfg中定义了的 max_check_attempts 5 normal_check_interval 3 retry_check_interval 2 check_period 24x7 notification_interval 10 notification_period 24x7 notification_options u,c,r contact_groups sagroup } |
监控Nagios-Server的根分区使用情况
|
define service{ host_name Nagios-Server service_description check disk check_command check_local_disk!10%!5%!/ max_check_attempts 5 normal_check_interval 3 retry_check_interval 2 check_period 24x7 notification_interval 10 notification_period 24x7 notification_options w,u,c,r contact_groups sagroup } |
其他的监控服务类似于这样,需要监控的服务在commands.cfg里都可以一一找到模版,需要监控不同主机只要修改hostname这一栏就行了。
对于像磁盘容量,cpu负载这样的”本地信息”,nagios只能监测自己所在的主机,而对其他的机器则显得有点无能为力.毕竟没得到被控主机的适当权限是不可能得到这些信息的.为了解决这个问题,nagios有这样一个附加组件----NRPE.用它就可以完成对linux类型主机”本地信息”的监控.
NRPE原理图如下:
.files/image018.jpg)
NRPE总共由两部分组成:
– check_nrpe 插件,位于在监控主机上
– NRPE daemon,运行在远程的linux主机上(通常就是被监控机)
按照上图,整个的监控过程如下:
当nagios需要监控某个远程linux主机的服务或者资源情况时
1.nagios会运行check_nrpe这个插件,告诉它要检查什么.
2.check_nrpe插件会连接到远程的NRPE daemon,所用的方式是SSL
3.NRPE daemon会运行相应的nagios插件来执行检查
4.NRPE daemon将检查的结果返回给check_nrpe插件,插件将其递交给nagios做处理.
注意:NRPE daemon需要nagios插件安装在远程的linux主机上,否则,daemon不能做任何的监控.
1.首先需要添加nagios用户
[root@127.43~]#useradd –s /sbin/nologin nagios
[root@127.43~]#passwd nagios
2.安装nagios插件
[root@127.43~]# tar –zxvf nagios-plugins-2.1.1.tar.gz
[root@127.43~]#cd nagios-plugins-2.1.1/
[root@127.43 nagios-plugins-2.1.1]#./configure
[root@127.43 nagios-plugins-2.1.1]# make&&make install
这一步完成后会在/usr/local/nagios/下生成两个目录libexec和share
3.修改目录权限
[root@127.43 nagios-plugins-2.1.1]#chown nagios:nagios /usr/local/nagios
[root@127.43 nagios-plugins-2.1.1]#chown –R nagios:nagios /usr/local/nagios/libexec
或者可以直接一条命令完成:
[root@127.43 nagios-plugins-2.1.1]#chown –R nagios:nagios /usr/local/nagios
4.安装nrpe
[root@127.43~]# tar –zxvf nrpe-2.1.12.tar.gz
[root@127.43~]#cd nrpe-2.12/
[root@127.43 nrpe-2.12]#./configure
[root@127.43 nrpe-2.12]#make all
[root@127.43 nrpe-2.12]#make install-plugin
主监控机需要安装check_nrpe这个插件,被监控机则不需要,这里就都安装上以备万一
[root@127.43 nrpe-2.12]#make install-daemon
安装daemon
[root@127.43 nrpe-2.12]#make install-daemon-config
安装配置文件
查看nagios目录会发现已经生成一下几个目录
![]()
另外一点是nrpe daemon是作为xinetd下的一个服务运行的,所以首先要安装好xinetd,不过一般系统默认是已经安装上的。
[root@127.43 nrpe-2.12]#make install-xinetd
安装xinetd脚本文件,就创建了/etc/xinetd.d/nrpe这个文件,下面来编辑这个文件
[root@127.43 nrpe-2.12]#vim /etc/xinetd.d/nrpe
.files/image020.png)
只需要在only_from后面加上监控主机的地址就行,以空格相隔。
5.编辑/etc/services文件,增加nrpe服务
[root@127.43 nrpe-2.12]#vim /etc/services
.files/image021.png)
在最后一行添加上 nrpe 5666/tcp #nrpe
最后重启xinetd服务
[root@127.43 nrpe-2.12]#service xinetd restart
![]()
可以查看到5666端口已经在监听了,然后使用check_nrpe这个插件功能测试nrpe时候正常工作
![]()
可以看到返回当前NRPE的版本,说明本地用check_nrpe连接nrpe daemon是正常的。要注意的是为了让主监控机能监控到被监控机信息,被监控机也要保证防火墙打开5666端口。
6.查看nrpe的监控命令
进入到/usr/local/nagios/etc目录,可以看到目录下有一个nrpe.cfg文件,这就是nrpe的主配置文件,编辑他,找到下面这段话:
|
# The following examples use hardcoded command arguments... command[check_users]=/usr/local/nagios/libexec/check_users -w 5 -c 10 command[check_load]=/usr/local/nagios/libexec/check_load -w 15,10,5 -c 30,25,20 command[check_hda1]=/usr/local/nagios/libexec/check_disk -w 20 -c 10 -p /dev/hda1 command[check_zombie_procs]=/usr/local/nagios/libexec/check_procs -w 5 -c 10 -s Z command[check_total_procs]=/usr/local/nagios/libexec/check_procs -w 150 -c 200 |
红色部分是命令名,也就是check_nrpe 的-c参数可以接的内容,等号=后面是实际执行的插件程序(这与commands.cfg中定义命令的形式十分相似,只不过是写在了一行).也就是说check_users就是等号后面/usr/local/nagios/libexec/check_users -w 5 -c 10的简称.
我们可以很容易知道上面这5行定义的命令分别是检测登陆用户数,cpu负载,hda1的容量,僵尸进程,总进程数.各条命令具体的含义见插件用法(执行”插件程序名 –h”)
|
/usr/local/nagios/libexec/check_nrpe -H localhost -c check_users |
|
/usr/local/nagios/libexec/check_nrpe -H localhost -c check_load |
|
/usr/local/nagios/libexec/check_nrpe -H localhost -c check_hda1 |
|
/usr/local/nagios/libexec/check_nrpe -H localhost -c check_zombie_procs |
|
/usr/local/nagios/libexec/check_nrpe -H localhost -c check_total_procs |
到此被监控机上的配置就完成了,下面配置主监控机。
在主监控机上其实要做的就是安装check_nrpe插件,然后在commands.cfg里创建check_nrpe的命令定义,daemon不需要安装上去,但是为了保险起见还是同客户端上一样都安装上去。
1.安装插件和nrpe
[root@nagios~]# tar –zxvf nrpe-2.1.12.tar.gz
[root@nagios~]# cd nrpe-2.12/
[root@nagios nrpe-2.12]#./configure&&make all
[root@nagios nrpe-2.12]#make install-plugin
[root@nagios nrpe-2.12]#make install-daemon
[root@nagios nrpe-2.12]#make install-daemon-config
[root@nagios nrpe-2.12]#make install-xinetd
![]()
执行这句命令测试监控机使用check_nrpe与被监控机运行的nrpe-daemon之间的通信是否成功,如果返回正确版本信息说明正常。
2.修改目录权限
[root@nagios nagios-plugins-2.1.1]#chown nagios:nagios /usr/local/nagios
[root@nagios nagios-plugins-2.1.1]#chown –R nagios:nagios /usr/local/nagios/libexec
或者可以直接一条命令完成:
[root@nagios nagios-plugins-2.1.1]#chown –R nagios:nagios /usr/local/nagios
编辑nrpe
[root@127.43 nrpe-2.12]#vim /etc/xinetd.d/nrpe
.files/image025.png)
3.添加nrpe服务端口
[root@nagios nrpe-2.12]# vim /etc/services 在最后添加nrpe 5666/tcp #nrpe
最后重启xinetd服务 /etc/init.d/xinetd restart
以上几步和客户端上的配置相同
4.在commands.cfg里增加对check_nrpe的定义
只需要在最后增加下面内容:
# ‘check_nrpe ‘ command definition
define command{
command_name check_nrpe
command_line /usr/local/nagios/libexec(或者直接写$USER1$)/check_nrpe -H $HOSTADDRESS$ -c $ARG1$
}
.files/image026.jpg)
-c后面带的$ARG1$参数是传给nrpe daemon执行的检测命令,之前说过了它必须是nrpe.cfg中所定义的那5条命令中的其中一条.在services.cfg中使用check_nrpe的时候要用!带上这个参数
下面就可以在services.cfg中定义对211.162.127.43主机cpu负载等等的监控
define service {
host_name 211.162.127.43
被监控的主机名,这里注意必须是linux且运行着nrpe,而且必须是hosts.cfg中定义的
service_description check-users
监控项目的名称
check_period 24x7
max_check_attempts 4
normal_check_interval 3
retry_check_interval 2
contact_groups sagroup
notification_interval 10
notification_period 24x7
notification_options w,u,c,r
check_command check_nrpe!check_users
监控命令check_nrpe,是在commands.cfg中定义的,带的参数是check_load,是在nrpe.cfg中定义的
}
define service {
host_name 211.162.127.43
service_description check-load
check_period 24x7
max_check_attempts 4
normal_check_interval 3
retry_check_interval 2
contact_groups sagroup
notification_interval 10
notification_period 24x7
notification_options w,u,c,r
check_command check_nrpe!check_load
}
define service {
host_name 211.162.127.43
service_description check-total-procs
check_period 24x7
max_check_attempts 4
normal_check_interval 3
retry_check_interval 2
contact_groups sagroup
notification_interval 10
notification_period 24x7
notification_options w,u,c,r
check_command check_total_procs
}
加入监控swap使用情况,很遗憾的是在nrpe.cfg中默认没有定义这个监控功能的定义,那就手动在nrpe.cfg中添加,自定义对于监控swap的nrpe命令。
现在我们要监控swap分区,如果空闲空间小于20%则为警告状态—warning;如果小于10%则为严重状态—critical.我们可以查得需要使用check_swap插件,完整的命令行应该是下面这样.
/usr/local/nagios/libexec/check_swap -w 20% -c 10%
编辑/usr/local/nagios/etc/nrpe.cfg增加下面这行
|
command[check_swap]=/usr/local/nagios/libexec/check_swap -w 20% -c 10% |
现在check_swap就可以作为check_nrpe的-c的参数使用了,在services.cfg里增加这个监控项目
define service {
host_name 211.162.127.43
service_description check-swap
check_period 24x7
max_check_attempts 4
normal_check_interval 3
retry_check_interval 2
contact_groups sagroup
notification_interval 10
notification_period 24x7
notification_options w,u,c,r
check_command check_nrpe!check_swap
}
接下来重启nagios就行了,到此服务器端和客户端的配置全部完成。
1.安装硬件
把短信猫接上电源,把sim卡插入,把串口连接到服务器主机接口上。
2.安装minicom
[root@nagios~]# yum -y install minicom gettext-devel gettext
3.设置超级终端参数
[root@nagios~]#minicom -s 将会出现以下界面
.files/image027.png)
选中serial port setup,输入a将/dev/modem改为对应串口(ttyS0是串口1,ttyS1是串口2),输入e修改波特率,最后选择save setup as dfl然后Exit from Minicom
.files/image028.png)
4.下载安装gnokii
wget
http://www.gnokii.org/download/gnokii/gnokii-0.6.30.tar.gz
wget http://ftp.gnome.org/pub/gnome/sources/intltool/0.40/intltool-0.40.6.tar.gz
首先要先安装perl-XML-Parse
![]()
然后解压安装intltool
[root@nagios~]# tar -zxvf intltool-0.40.6.tar.gz
[root@nagios~]#cd intltool-0.40.6
[root@nagios intltool-0.40.6]#./configure
[root@nagios intltool-0.40.6]#make&&make install
最后再安装gnokii
[root@nagios~]# tar -zxvf gnokii-0.6.30.tar.gz
[root@nagios~]# cd gnokii-0.6.30
[root@nagios gnokii-0.6.30]#./configure
[root@nagios gnokii-0.6.30]#gmake
[root@nagios gnokii-0.6.30]#gmake install
5.配置gnokii
[root@nagios~]#mkdir -p /root/.config/gnokii
[root@nagios~]#cp /usr/local/share/doc/gnokii/sample/gnokiirc /root/.config/gnokii/config
然后编辑这个文件
[global]
port = /dev/ttyS0
其他的port都可以注释掉
model = AT
同样的把其他model = 6510什么的都注释掉
Initlength = default
connection = serial
usr_locking=no
据说这个为yes时无法同时给多人发送短信,没试过
serial_baudrate = 9600
.files/image030.png)
smsc_timeout = 10
[xgnokii]
allow_breakage = 0
[gnokiid]
bindir = /usr/local/sbin/ 测试机里写的是sbin,但是看技术文档上又是写的bin,还是按照机器上的来做吧,不行就换bin
[connect_script]
TELEPHONE=12345678
[logging]
debug = on
rlpdebug = off
xdebug = off
.files/image031.png)
6.测试gnokii
[root@nagios~]# gnokii --identify
看到无报错的话现在就可以发短信了,不过在使用之前可以使用which gnokii来查看一下gnokii命令正确的绝对路径,本测试机是在/usr/local/bin/gnokii
[root@nagios~]# echo -n "test message" | /usr/local/bin/gnokii --sendsms 1342893****
.files/image032.png)
显示OK应该很快就能收到短信了
[root@nagios~]# vim /usr/local/nagios/etc/objects/commands.cfg加入对短信自动报警命令的定义
.files/image033.png)
最好是手动一个个的敲,否则很容易出错,最后修改一下权限问题
[root@nagios~]# chown -R nagios:nagios /usr/local/bin/gnokii
[root@nagios~]# chown -R nagios:nagios /dev/ttyS0
然后切换到nagios用户测试下发送短信
[nagios@nagios~]# echo -n "test message" | /usr/local/bin/gnokii --sendsms 1342893****
如果成功收到短信证明没什么问题了,(在此之前应该还要会cp下模版文件之类的,看具体报什么错,解决步骤跟root用户操作一样,cp模版文件到某个目录下然后修改参数)nagios应该能实现自动发送短信功能,但是我遇到很奇怪的事情,就是手动测试能成功收到短信,但是down掉一个服务后nagios就是不能自动发送短信,后来在一个国外论坛上查到解决方案,实施后问题解决。
[root@nagios~]# cp .config/gnokii/config /etc/gnokiirc
[root@nagios~]# usermod -a -G uucp nagios
.files/image034.png)
详见网站
http://securfox.wordpress.com/2009/03/30/how-to-configure-nagios-to-send-sms-to-your-mobile/
NSClient的原理如下图
.files/image035.jpg)
可以看到,NSClient与nrpe最大的区别就是:
--被监控机上安装有nrpe,并且还有插件,最终的监控是由这些插件来进行的.当监控主机将监控请求发给nrpe后,nrpe调用插件来完成监控.
--NSClient则不同,被监控机上只安装NSClient,没有任何的插件.当监控主机将监控请求发给NSClient后,NSClient直接完成监控,所有的监控是由NSClient完成的.
下面就开始手动安装
1.安装NSClient
从http://nsclient.org/nscp/downloads上下载最新的软件包,有64位,32位各种软件包提供不同下载需求,这里我们选择的就是windows32位包下载,选择NSClient++-0.3.9-Win32.zip下载。
.files/image036.png)
解压到C盘名为NSClient的文件夹中
.files/image037.png)
2.安装服务
打开cmd切换到C:\NSClient
执行nsclient++ /install
![]()
执行nsclient++ SysTray 注意大小写,这一步是安装系统托盘,时间稍微有点长
![]()
在运行里面输入services.msc打开”服务”
.files/image040.jpg)
看到下图就说明NSClient服务已经安装上了

双击打开,点”登录”标签,在”允许服务与桌面交互”前打勾

3.修改配置文件
编辑C:\NSClient目录下的NSC.ini文件
|
将 [modules]部分的所有模块前面的注释都去掉,除了CheckWMI.dll and RemoteConfiguration.dll这两个 |
|
在[Settings]部分设置‘password‘选项来设置密码,作用是在nagios连接过来时要求提供密码.这一步是可选的,我这里方便起见跳过它,不要密码. |
|
将[Settings]部分‘allowed_hosts‘选项的注释去掉,并且加上运行nagios的监控主机的IP.我改为如下这样allowed_hosts=127.0.0.1/32,192.168.0.111 以逗号相隔.这个地方是支持子网的,如果写成192.168.0.0/24则表示该子网内的所有机器都可以访问.如果这个地方是空白则表示所有的主机都可以连接上来.注意是[Settings]部分的,因为[NSClient]部分也有这个选项. |
|
必须保证[NSClient]的‘port‘选项并没有被注释,并且它的值是‘12489‘,这是NSClient的默认监听端口 |
如下图所示:
.files/image043.png)
.files/image044.png)
.files/image045.png)
、.files/image046.jpg)
.files/image047.png)
在CMD中执行nsclient++ /start启动服务,注意所在目录是C:\NSClient
![]()
已经正常启动了.注意服务默认设的是”自动”,也就是说是开机自动启动的.
在cmd里面执行netstat –an可以看到已经开始监听tcp的12489端口了
![]()
这样外部就可以访问了吗?错!防火墙也要打开tcp的12489端口,否则nagios检查此服务的时候会报socket 超时错误.是critical哦!后果很十分严重啊.我就犯了这个错误,所以特别强调一下。在windows防火墙启用的情况下
.files/image050.png)
选择例外添加端口
.files/image051.png)
添加NSClient++端口就OK了
.files/image052.png)
这样被监控机的配置就搞定了,它就等待nagios发出某个监控请求,然后它执行请求将监控的结果发回到nagios监控主机上。
4.对监控主机的配置
接下来就是要配置监控主机了.与之前的nrpe的过程类似,在监控主机上做的就3件事情
1.安装监控windows的插件(已经默认安装了,check_nt)
2.定义命令
3.定义要监控的项目
定义命令
在nagios的libexec下有check_nt这个插件,它就是用来检查windows机器的服务的,其功能类似于上一章讲的check_nrpe.
vim /usr/local/nagios/etc/objects/commands.cfg
.files/image053.png)
模版中应该有这句命令的定义了,接下来直接引用就行了。
如果NSClient设置了连接需要密码,则应写成如下格式
$USER1$/check_nt -H $HOSTADDRESS$ -p 12489 -s PASSWORD -v $ARG1$ $ARG2$
增加监控项目
vi /usr/local/nagios/etc/objects/services.cfg
.files/image054.png)
当然windows-127.189这个hostsname还得去hosts.cfg主机配置文件当中定义好,要不得报错。
同样的可以增加如下服务(为了篇幅,我只给出最关键的check_command这一项)
1)监控windows服务器运行的时间
check_command check_nt!UPTIME
2)监控Windows服务器的CPU负载,如果5分钟超过80%则是warning,如果5分钟超过90%则是critical
check_command check_nt!CPULOAD!-l 5,80,90
3)监控Windows服务器的内存使用情况,如果超过了80%则是warning,如果超过90%则是critical.
check_command check_nt!MEMUSE!-w 80 -c 90
4)监控Windows服务器C:\盘的使用情况,如果超过80%已经使用则是warning,超过90%则是critical
check_command check_nt!USEDDISKSPACE!-l c -w 80 -c 90
注:-l后面接的参数用来指定盘符
5)监控Windows服务器D:\盘的使用情况,如果超过80%已经使用则是warning,超过90%则是critical
check_command check_nt!USEDDISKSPACE!-l d -w 80 -c 90
6)监控Windows服务器的W3SVC服务的状态,如果服务停止了,则是critical
check_command check_nt!SERVICESTATE!-d SHOWALL -l W3SVC
7)监控Windows服务器的Explorer.exe进程的状态,如果进程停止了,则是critical
check_command check_nt!PROCSTATE!-d SHOWALL -l Explorer.exe
重启nagios服务来生效,等一会就可以查看页面了。
Sendmail配置
解压缩tar –zxvf sendEmail-v1.55.tar.gz
cd sendEmail-v1.55
将可执行程序复制cp sendEmail /usr/local/bin
然后给确认确实它具有执行权限
# ‘notify-by-email‘ command definition
define command{
command_name notify-by-email
command_line /usr/bin/printf "%b" "***** Nagios 2.9 *****\n\nNotification Type: $NOTIFICATIONTYPE$\n\nService: $SERVICEDESC$\nHost: $HOSTALIAS$\nAddress: $HOSTADDRESS$\nState: $SERVICESTATE$\n\nDate/Time: $LONGDATETIME$\n\nAdditional Info:\n\n$SERVICEOUTPUT$" | /usr/local/bin/sendEmail -f nagios@test.com -t $CONTACTEMAIL$ -s mail.test.com -u "** $NOTIFICATIONTYPE$ alert - $HOSTALIAS$/$SERVICEDESC$ is $SERVICESTATE$ **" -xu nagios -xp p#3isoda
}
标签:
原文地址:http://www.cnblogs.com/czrwxw/p/5141365.html