标签:
一、set集合:
1 #!/usr/bin/env python 2 # -*- encodeing:UTF-8 -*- 3 lst=[1,23,5,4,1,5,4] 4 print(set(lst)) 输出:[1,23,5,4]
例:交集、差集
1 #!/usr/bin/env python 2 # -*- encodeing:UTF-8 -*- 3 old_dict ={ 4 "#1":{‘hostname‘:‘c1‘,‘cpu_count‘:2,‘mem_capicity‘:80}, 5 "#2":{‘hostname‘:‘c1‘,‘cpu_count‘:2,‘mem_capicity‘:80}, 6 "#3":{‘hostname‘:‘c1‘,‘cpu_count‘:2,‘mem_capicity‘:80}, 7 } 8 new_dict ={ 9 "#1":{‘hostname‘:‘c1‘,‘cpu_count‘:2,‘mem_capicity‘:800}, 10 "#3":{‘hostname‘:‘c1‘,‘cpu_count‘:2,‘mem_capicity‘:80}, 11 "#4":{‘hostname‘:‘c2‘,‘cpu_count‘:2,‘mem_capicity‘:80}, 12 } 13 old=set(old_dict.keys()) 14 new=set(new_dict.keys()) 15 updata_set=old.intersection(old) 16 del_set=old.symmetric_difference(new) 17 add_set=new.symmetric_difference(updata_set) 18 print(updata_set) 19 print(del_set) 20 print(add_set)
1 import collections 2 obj=collections.Counter(‘fefheufheuf‘) 3 #print(obj) 4 #for k in obj.elements(): 5 # print(k) 6 for k,v in obj.items(): 7 print(k,v) 输出:h 2 f 4 u 2 e 3
1 # -*- encodeing:UTF-8 -*- 2 import collections 3 d = collections.OrderedDict() 4 d[3]=‘A‘ 5 d[2]=‘B‘ 6 d[1]=‘C‘ 7 for k, v in d.items(): 8 print(k, v)
1 #!/usr/bin/env python 2 # -*- encodeing:UTF-8 -*- 3 import collections 4 def default_factory(): 5 return‘default value‘ 6 d=collections.defaultdict(default_factory,foo=‘bar‘,ok=‘ok‘) 7 print(‘d:‘,d) 8 print(‘foo=>‘,d[‘foo‘]) 9 print(‘ok=>‘,d[‘ok‘]) 10 print(‘bar=>‘,d[‘bar‘])
1 #!/usr/bin/env python 2 # -*- encodeing:UTF-8 -*- 3 import collections 4 d=collections.deque(‘abcdefgh‘) 5 print(‘Deque:‘,d) 6 7 #!/usr/bin/env python 8 # -*- encodeing:UTF-8 -*- 9 import collections 10 d=collections.deque() 11 d.extend(‘abcdefg‘) 12 print(‘extend:‘,d) 13 d.append(‘h‘) 14 print(‘append:‘,d) 15 # add to left 16 d1=collections.deque() 17 d1.extendleft(range(6)) 18 print(‘extendleft:‘,d1) 19 d1.appendleft(6) 20 print(‘appendleft:‘,d1)
1 #!/usr/bin/env python 2 # -*- encodeing:UTF-8 -*- 3 import queue 4 q=queue.Queue() 5 q.put(‘123‘) 6 q.get(‘4545‘) 7 print(q)
1 #!/usr/bin/env python 2 # -*- encodeing:UTF-8 -*- 3 import collections 4 MytupleClass= collections.namedtuple(‘MytupleClass‘,[‘x‘,‘y‘,‘z‘]) 5 obj =MytupleClass(11,22,33) 6 print(obj.x) 7 print(obj.y) 8 print(obj.z) 输出:11 22 33
1 n1={‘k1‘:8,‘k2‘:787,‘k3‘:[2,4]} 2 print(id(n1)) 3 n2=copy.copy(n1) 4 print(id(n2)) 5 n3=copy.deepcopy(n1) 6 print(id(n3)) 7 8 n4={‘cpu‘:[90,],‘mem‘:[80,],‘disk‘:[80]} 9 n5 =copy.deepcopy(n4) 10 print(n5) 11 n5[‘cpu‘][0]=60 12 print(n5) 输出:{‘mem‘: [80], ‘disk‘: [80], ‘cpu‘: [90]} {‘mem‘: [80], ‘disk‘: [80], ‘cpu‘: [60]}
1 def函数名(): 2 函数体 3 函数名()
1 #!/usr/bin/env python 2 def hanshu(): 3 num1=8 4 num1+=8 5 print(num1) 6 hanshu() 输出:16
1 def wa(a1,a2=232,a3=24):#默认参数必须放在最后 2 print(a1,a2,a3) 3 wa(a1=53,a2=989)
1 def show(*arg): 2 print(arg,type(arg)) 3 show(78,98) 4 5 def show(**args): 6 print(args,type(args)) 7 show(k1=32,k2=898,k3=343) 8 9 def show (*args,**kwargs): 10 print(args,type(args)) 11 print(kwargs,type(kwargs)) 12 show(34,43,k1=45,k2=45,)
1 l1={‘alvin‘,‘boy‘,‘eric‘} 2 for i,item in enumerate(l1,1): 3 print(i,item) 输出:1 alvin 2 eric 3 boy
map与filte
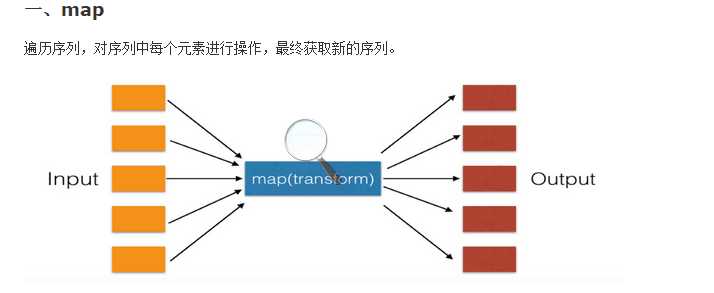
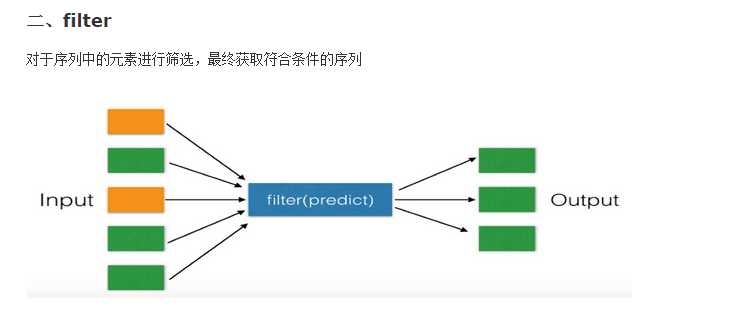
标签:
原文地址:http://www.cnblogs.com/Xiaolong-Lv/p/5143902.html