标签:
1) 不同应用中B+树索引的使用
对于OLTP应用,由于数据量获取可能是其中一小部分,建立B+树索引是有异议时的
对OLAP应用,情况比较复杂,因为索引的添加应该是宏观的而不是微观的。
2) 联合索引
对表上多个列进行索引。联合索引的创建方法与多个索引创建的方法一样。不同之处在于有多个索引页
CREATE TABLE t( a INT, b INT, PRIMARY KEY(a), KEY idx_a_b(a,b) )ENGINE=INNODB
从本质上来说,联合索引也是一棵B+树,不同的联合索引的键值的数量不是1,而是大于等于2。
讨论一下由2个整数列组成的联合索引,分别为a,b
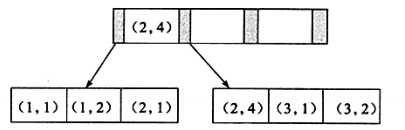
可以看到键值是顺序的,通过叶子节点可以逻辑上顺序地读出所有的数据,即(1,1)(1,2)(2,1)(2,4)(3,1)(3,2)。数据按(a,b)顺序存放
因此对于查询SELECT * FROM TABLE WHERE a = 1 and b=2,显然是可以使用(a,b)联合索引的。对于单列a查询SELECT * FROM TABLE WHERE a = 1,也是可以用到这个(a,b)索引,但是对于b列SELECT * FROM TABLE WHERE b = 2则不可以使用B+树索引。可以发现叶子节点上b列的值为1 2 1 4 1 2 不是顺序的。因此对于b列的查询是使用不到(a,b)的索引
联合索引的第二个好处是已经对第二个键值进行排序处理。例如在很多情况下,需要对某个用户的购物情况进行查询,并且按照时间排序最后取出最近三次的购物记录,使用联合索引可以避免多一次的排序操作。因为索引本身在叶子节点已经排序了。
CREATE TABLE buy_log( userid INT UNSIGNED NOT NULL, buy_date DATE )ENGINE=INNODB; INSERT INTO buy_log VALUES(1,‘2009-01-01‘); INSERT INTO buy_log VALUES(2,‘2009-01-01‘); INSERT INTO buy_log VALUES(3,‘2009-01-01‘); INSERT INTO buy_log VALUES(1,‘2009-02-01‘); INSERT INTO buy_log VALUES(3,‘2009-02-01‘); INSERT INTO buy_log VALUES(1,‘2009-03-01‘); INSERT INTO buy_log VALUES(1,‘2009-04-01‘); ALTER TABLE buy_log ADD KEY(userid); ALTER TABLE buy_log ADD KEY(userid,buy_date);
建立了两个索引做比较。都包含userid。
SELECT * FROM buy_log WHERE userid=2;
查看优化器的选择

可以看到两个索引都可以使用。但优化器最终使用了userid,因为该索引的叶子节点包含单个键值。所以理论上一个页能存放的记录应该更多
假定要取出userid=1的最近3次记录
EXPLAIN SELECT * FROM buy_log WHERE userid=1 ORDER BY buy_date DESC LIMIT 3;

这次优化器使用了(userid,buy_date)的联合索引userid_2 因为在这个联合索引中buy_date已经排序了。根据该联合索引取出数据,无须在对buy_date做一次额外的排序操作。若强制使用userid索引
EXPLAIN SELECT * FROM buy_log FORCE INDEX(userid) WHERE userid=1 ORDER BY buy_date DESC LIMIT 3;

可以看到Using filesort,即需要额外的一次排序操作才能完成查询。显然是对buy_date排序。因为索引userid中的buy_date是未排序的
联合索引(a,b)其实是根据列a,b进行排序的,故此下面语句可以直接使用联合索引得到结果
EXPLAIN SELECT * FROM TABLE WHERE a=1 ORDER BY b;
对于联合索引(a,b,c) 也可以直接通过联合索引得到结果
EXPLAIN SELECT * FROM TABLE WHERE a=1 and b = 1 ORDER BY c; EXPLAIN SELECT * FROM TABLE WHERE a=1 ORDER BY b;
但是对于下面语句,就不能得到结果了,需要执行一次filesort排序操作因为(a,c)并未排序
EXPLAIN SELECT * FROM TABLE WHERE a=1 ORDER BY c;
3) 覆盖索引
InnoDB存储引擎支持覆盖索引,即从辅助索引中就可以查询到记录,而不需要查询聚集索引中的记录。使用覆盖索引的一个好处是辅助索引不包含整行记录的所有信息,故其大小远小于聚集索引。因此可以减少大量的IO操作
对于InnoDB存储引擎的辅助索引,由于其包含了主键信息,因此其叶子节点存放的数据为(parimary key1,parimary key2,...key1,key2,...)例如,下面语句都可仅使用一次辅助联合索引来完成查询
SELECT key2 FROM table WHERE key1=xxx; SELECT primary key2,key2 FROM table key1=xxx; SELECT primary key1,key2 FROM table key1=xxx; SELECT primary key1,primary key2,key2 FROM table key1=xxx;
覆盖索引的另一个好处是对某些统计问题而言,如上的buy_log,要进行如下查询
SELECT COUNT(*) FROM buy_log;
InnoDB存储引擎并不会选择通过查询聚集索引来进行统计。由于buy_log还有辅助索引,而辅助索引远小于聚集索引。选择辅助索引可以减少IO操作。

如图显示。possible_keys是NULL,但是实际执行优化器却选择了userid,而列Extra的Using index就是代表优化器选择了覆盖索引的操作
此外,在通常情况下,(a,b)的联合索引,一半是不可以选择列b中所谓的查询条件,但是如果是统计操作,并且是覆盖索引的。则优化器会进行选择
EXPLAIN SELECT COUNT(*) FROM buy_log WHERE buy_date>=‘2011-01-01‘ AND buy_date<‘2011-02-01‘;

表buy_log有(userid,buy_date)联合索引,这里只根据b进行了条件查询,一般情况下,是不能进行该联合索引的。但这条SQL语句查询是统计操作。并且可以利用覆盖索引的信息。因此优化器是会选择联合索引的。
标签:
原文地址:http://www.cnblogs.com/olinux/p/5146263.html