标签:
1、memcached 介绍
1.1 memcached是什么?
memcached 是以LiveJournal旗下Danga Interactive 公司的Brad Fitzpatric 为首开发的一款软件。现在已成为mixi、hatena、Facebook、Vox、LiveJournal 等众多服务中提高Web应用扩展性的重要因素。许多Web 应用都将数据保存到RDBMS 中,应用服务器从中读取数据并在浏览器中显示。但随着数据量的增大、访问的集中,就会出现RDBMS 的负担加重、数据库响应恶化、网站显示延迟等重大影响。这时就该memcached 大显身手了。memcached 是高性能的分布式内存缓存服务器。一般的使用目的是,通过缓存数据库查询结果,减少数据库访问次数,以提高动态Web 应用的速度、提高可扩展性。
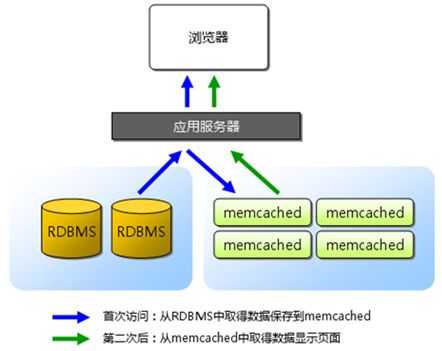
可见memcached的分布式,则是完全由客户端程序库实现的。这种分布式是memcached的最大特点。
Memcached的内存管理
最近的memcached默认情况下采用了名为Slab Allocatoion的机制分配,管理内存。在改机制出现以前,内存的分配是通过对所有记录简单地进行malloc和free来进行的。但是这中方式会导致内存碎片,加重操作系统内存管理器的负担。
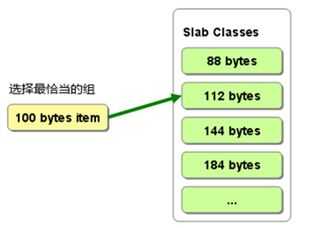
Slab Allocator的基本原理是按照预先规定的大小,将分配的内存分割成特定长度的块,已完全解决内存碎片问题。Slab Allocation 的原理相当简单。将分配的内存分割成各种尺寸的块(chucnk),并把尺寸相同的块分成组(chucnk的集合)如图:
而且slab allocator 还有重复使用已分配内存的目的。也就是说,分配到的内存不会释放,而是重复利用。
Slab Allocation 的主要术语
在Slab 中缓存记录的原理
Memcached根据收到的数据的大小,选择最合适数据大小的Slab (图2) memcached中保存着slab内空闲chunk的列表,根据该列表选择chunk,然后将数据缓存于其中。
Memcached在数据删除方面有效里利用资源
Memcached删除数据时数据不会真正从memcached中消失。Memcached不会释放已分配的内存。记录超时后,客户端就无法再看见该记录(invisible 透明),其存储空间即可重复使用。
Lazy Expriationmemcached内部不会监视记录是否过期,而是在get时查看记录的时间戳,检查记录是否过期。这种技术称为lazy expiration.因此memcached不会再过期监视上耗费CPU时间。
对于缓存存储容量满的情况下的删除需要考虑多种机制,一方面是按队列机制,一方面应该对应缓存对象本身的优先级,根据缓存对象的优先级进行对象的删除。
LRU:从缓存中有效删除数据的原理
Memcached会优先使用已超时的记录空间,但即使如此,也会发生追加新纪录时空间不足的情况。此时就要使用名为Least Recently Used (LRU)机制来分配空间。这就是删除最少使用的记录的机制。因此当memcached的内存空间不足时(无法从slab class)获取到新空间时,就从最近未使用的记录中搜索,并将空间分配给新的记录。
Memcached分布式
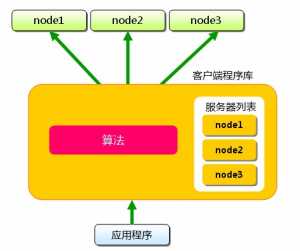
Memcached虽然称为“分布式“缓存服务器,但服务器端并没有“分布式”的功能。Memcached的分布式完全是有客户端实现的。现在我们就看一下memcached是怎么实现分布式缓存的。
例如下面假设memcached服务器有node1~node3三台,应用程序要保存键名为“tokyo”“kanagawa”“chiba”“saitama”“gunma” 的数据。
首先向memcached中添加“tokyo”。将“tokyo”传给客户端程序库后,客户端实现的算法就会根据“键”来决定保存数据的memcached服务器。服务器选定后,即命令它保存“tokyo”及其值。
同样,“kanagawa”“chiba”“saitama”“gunma”都是先选择服务器再保存。
接下来获取保存的数据。获取时也要将要获取的键“tokyo”传递给函数库。函数库通过与数据保存时相同的算法,根据“键”选择服务器。使用的算法相同,就能选中与保存时相同的服务器,然后发送get命令。只要数据没有因为某些原因被删除,就能获得保存的值。
这样,将不同的键保存到不同的服务器上,就实现了memcached的分布式。 memcached服务器增多后,键就会分散,即使一台memcached服务器发生故障无法连接,也不会影响其他的缓存,系统依然能继续运行。
Memcached的缓存分布策略:http://blog.csdn.net/bintime/article/details/6259133
余数分布式算法
就是“根据服务器台数的余数进行分散”。求得键的整数哈希值,再除以服务器台数,根据其余数来选择服务器
余数算法的缺点
余数计算的方法简单,数据的分散性也相当优秀,但也有其缺点。那就是当添加或移除服务器时,缓存重组的代价相当巨大。添加服务器后,余数就会产生巨变,这样就无法获取与保存时相同的服务器,从而影响缓存的命中。
Consistent Hashing的简单说明
Consistent Hashing如下所示:首先求出memcached服务器(节点)的哈希值, 并将其配置到0~232的圆(continuum)上。 然后用同样的方法求出存储数据的键的哈希值,并映射到圆上。 然后从数据映射到的位置开始顺时针查找,将数据保存到找到的第一个服务器上。 如果超过232仍然找不到服务器,就会保存到第一台memcached服务器上。
从上图的状态中添加一台memcached服务器。余数分布式算法由于保存键的服务器会发生巨大变化 而影响缓存的命中率,但Consistent Hashing中,只有在continuum上增加服务器的地点逆时针方向的 第一台服务器上的键会受到影响。
因此,Consistent Hashing最大限度地抑制了键的重新分布。 而且,有的Consistent Hashing的实现方法还采用了虚拟节点的思想。 使用一般的hash函数的话,服务器的映射地点的分布非常不均匀。 因此,使用虚拟节点的思想,为每个物理节点(服务器) 在continuum上分配100~200个点。这样就能抑制分布不均匀, 最大限度地减小服务器增减时的缓存重新分布。
缓存多副本
缓存多副本主要是用于在缓存数据存放时存储缓存数据的多个副本,以防止缓存失效。缓存失效发生在以下几种情况:
在缓存多副本的情况下,需要重新考虑缓存的分布式分布策略。其次缓存的多个副本实际本身是可能的多个读的节点,可以做为分布式的并行读,这是另外一个可以考虑的问题。
缓存数据的一致性问题
缓存数据尽量只读,因此缓存本身是不适合大量写和更新操作的数据场景的。对于读的情况下,如果存在数据变化,一种是同时更新缓存和数据库。一种是直接对缓存数据进行失效处理。
Memcache 命中率
缓存命中率 = get_hits/cmd_get * 100% (总命中次数/总请求次数)
要提高memcached的命中率,预估我们的value大小并且适当的调整内存页大小和增长因子是必须的。
命中率的提升可以通过多种方案实现.
其一,提高服务获取的内存总量
其二,提高空间利用率,这实际上也是另一种方式的增加内存总量
其三,应用一级别上再来一次LRU
其四,对于整体命中率,可以采取有效的冗余策略,减少分布式服务时某个server发生服务抖动的情况
一些注意
1. memcache已经分配的内存不会再主动清理。
2. memcache分配给某个slab的内存页不能再分配给其他slab。
3. flush_all不能重置memcache分配内存页的格局,只是给所有的item置为过期。
4. memcache最大存储的item(key+value)大小限制为1M,这由page大小1M限制
5.由于memcache的分布式是客户端程序通过hash算法得到的key取模来实现,不同的语言可能会采用不同的hash算法,同样的客户端程序也有可能使用相异的方法,因此在多语言、多模块共用同一组memcached服务时,一定要注意在客户端选择相同的hash算法
6.启动memcached时可以通过-M参数禁止LRU替换,在内存用尽时add和set会返回失败
7.memcached启动时指定的是数据存储量,没有包括本身占用的内存、以及为了保存数据而设置的管理空间。因此它占用的内存量会多于启动时指定的内存分配量,这点需要注意。
8.memcache存储的时候对key的长度有限制,php和C的最大长度都是250
标签:
原文地址:http://www.cnblogs.com/duanxz/p/5149396.html