标签:
近期为了分析国内航空旅游业常见安全漏洞,想到了用大数据来分析,其实数据也不大,只是生产项目没有使用Hadoop,因此这里实际使用一次。
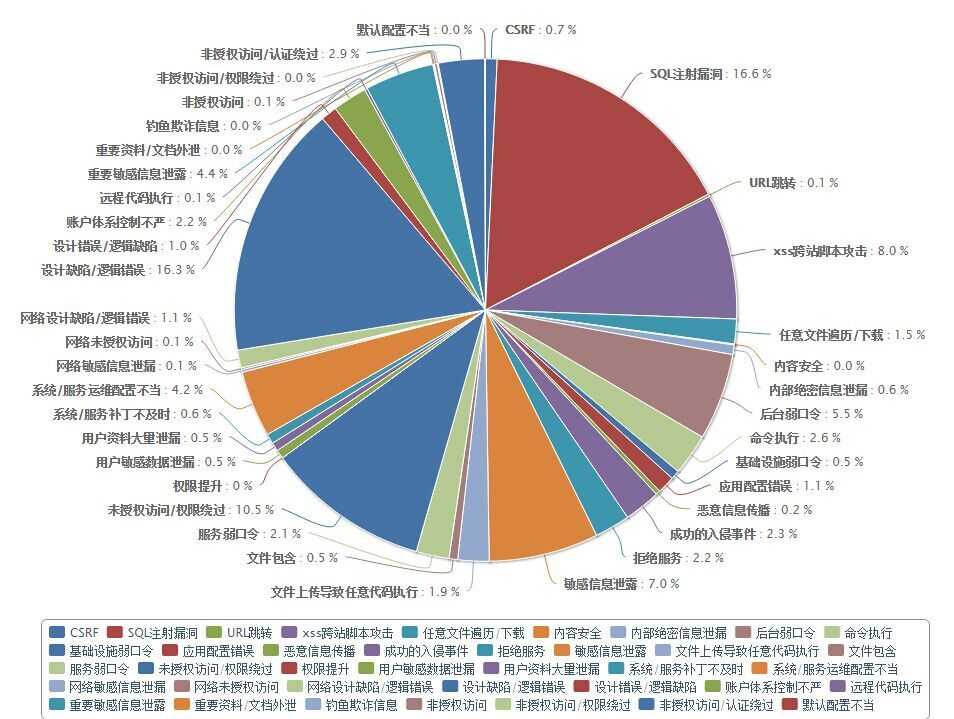
先看一下通过hadoop分析后的结果吧,最终通过hadoop分析国内典型航空旅游业厂商的常见安全漏洞个数的比例效果如下:
第一次正式使用Hadoop,肯定会遇到非常多的问题,参考了很多网络上的文章,我把自己从0搭建到使用的过程记录下来,方便以后自己或其他人参考。
之前简单用过storm,适合实时数据的处理。hadoop更偏向静态数据的处理,网上很多hadoop的教程,但有的版本比较老:比如有的是属于hadoop1.x时代,有的本机是ubuntu上安装,有的介绍理论,有的直接介绍代码demo。我的电脑是WIN7,打算在测试服务器linux Red Hat系列下搭建集群,然后通过本机win7开发并联调MapReduce程序。由于内容比较多,这篇博文主要写理论和Hadoop伪集群/集群安装过程以及Eclipse的插件安装,后面有时间再写一篇Eclipse开发的DEMO以及如何通过hadoop分析的航空旅游业典型安全漏洞。
下面主要写以下部分,理论知识描述可能会有误,主要是方便以后自己或别人参考:
一、Hadoop版本介绍
二、Hadoop名词理论介绍
三、SSH无密码登陆Linux
四、Hadoop单机安装
五、Hadoop单机模式运行
六、Hadoop伪分布式部署
七、Hadoop集群部署
八、Eclipse插件安装
九、安装调试过程中我遇到的问题
一、Hadoop版本介绍
Hadoop有1.x和2.x两个版本,参考别人官方一点的说法:Hadoop 1.x由一个分布式文件系统HDFS和一个离线计算框架MapReduce组成,HDFS由一个NameNode和多个DataNode组成,MapReduce由一个JobTracker和多个TaskTracker组成;而Hadoop 2.x则包含一个支持NameNode横向扩展的HDFS,一个资源管理系统YARN和一个运行在YARN上的离线计算框架MapReduce,YARN它将JobTracker中的资源管理和作业控制功能分开,分别由组件ResourceManager和ApplicationMaster实现,其中,ResourceManager负责所有应用程序的资源分配,而ApplicationMaster仅负责管理一个应用程序。
他们的架构做了较大调整,内部细节感兴趣可以去研究,但对开发人员最直观看到的就是配置文件的参数名称不一样了,具体可以参考:
http://www.ibm.com/developerworks/cn/opensource/os-cn-hadoop-yarn/
二、Hadoop名词理论介绍
系统角色:ResourceManager ,ApplicationMaster , NodeManager
应用名称:Job
组建接口:Mapper , Reducer
HDFS:Namenode ,Datanode
Hadop1.x时代系统角色有JobTracker和TaskTracker的概念,Hadoop2.X时代用Yarn替换了这两个角色。TaskTracker 是 Map-reduce 集群中每台机器都有的一个部分,他做的事情主要是监视自己所在机器的资源情况。TaskTracker 同时监视当前机器的 tasks 运行状况。TaskTracker 需要把这些信息通过 heartbeat 发送给 JobTracker,JobTracker 会搜集这些信息以给新提交的 job 分配运行在哪些机器上。
ResourceManager 是一个中心的服务,它做的事情是调度、启动每一个 Job 所属的 ApplicationMaster、另外监控 ApplicationMaster 的存在情况
NodeManager 功能比较专一,就是负责 Container 状态的维护,并向 ResourceManager 保持心跳。
ApplicationMaster 负责一个 Job 生命周期内的所有工作,类似老的框架中 JobTracker。但注意每一个 Job(不是每一种)都有一个 ApplicationMaster,它可以运行在 ResourceManager 以外的机器上。
NameNode可以看作是分布式文件系统中的管理者,主要负责管理文件系统的命名空间、集群配置信息和存储块的复制等。NameNode会将文件系统的Meta-data存储在内存中,这些信息主要包括了文件信息、每一个文件对应的文件块的信息和每一个文件块在DataNode的信息等。
Datanode是文件系统的工作节点,他们根据客户端或者是namenode的调度存储和检索数据,并且定期向namenode发送他们所存储的块(block)的列表。
hadoop系统中,master/slaves的一般对应关系是:
master---NameNode;ResourceManager ;
slaves---Datanode;NodeManager
在MapReduce中,一个准备提交执行的应用程序称为“作业(job)”,而从一个作业划分出的运行于各个计算节点的工作单元称为“任务(task)”。
Mapper任务运行时,它把输入文件切分成行并把每一行提供给可执行文件进程的标准输入传到map函数。 同时,mapper收集可执行文件进程标准输出的内容,并把收到的每一行内容转化成key/value对,作为mapper的输出。 其中key的值为距离文件第0个字符的距离,value为该行的值。
Reducer类中reduce函数接受Map函数组装的key/value,其中key为Map输出的键,values是各个键对应的数据集合。
三、SSH无密码登陆Linux
Ssh连接linux服务器,除了用账户密码连接,还提供通过公钥私钥配对登录的方式,这里让SSH无密码登录Linux,主要是为了方便Hadoop的Master直接连接各个Slave机器。因此创建SSH无密码登录Linux和Hadoop的功能没有关系,创建方式可以参考:
cd ~/.ssh/ #进入当前用户主目录下的.ssh文件夹下 rm ./id_rsa* #先删除已经存在的id_rsa开头的公钥文件,可能没有 ssh-keygen -t rsa #创建公钥文件,有提示,全部按确定即可 cat ./id_rsa.pub >> ./authorized_keys #把生成的id_rsa.pub公钥文件内容追加到当前目录下authorized_keys文件
创建公钥文件完成,测试可以试试:
ssh Master #Master为当前机器名,或ssh 当前ip。如果不需要输入密码,则说明成功
然后执行:
scp ~/.ssh/id_rsa.pub hadoop@Slave1:/home/hadoop/ #这条指令执行有前提,需要有一台Slave1的机器,并且当前机器Hosts对Slave1机器做了IP 机器猫映射,并且Slave1机器有一个用户名hadoop,并且用户的文件目录是/home/hadoop/。这条指令意思是把当前机器所属用户主目录下.ssh文件夹下的id_rsa.put公钥文件复制到远程机器Slave1的/home/hadoop目录下,并且访问远程机器的用户名是hadoop。
输入该指令后会要求输入Slave1机器hadoop用户的密码,输入成功后则会把id_rsa.pub文件传递到Slave1机器上。比如会有显示:
id_rsa.pub 100% 391 0.4KB/s 00:00
然后再Slave1上把Master机器的公钥文件放到用户主目录的/.ssh/authorized_keys文件里,在Slave1上操作的命令如下:
mkdir ~/.ssh #如果不存在则先创建 cat ~/id_rsa.pub >> ~/.ssh/authorized_keys rm ~/id_rsa.pub #复制完就可以删掉了
现在在Master机器上测试,因为把Master上生成的公钥文件放到Slave1机器hadoop用户的制定位置,就可以免密码登录Slave1机器了。
[hadoop@Master .ssh]$ ssh Slave1 [hadoop@Slave1 ~]$ exit #显示不用密码已经进入了Slave1机器,exit回到Master机器 logout Connection to Slave1 closed. [hadoop@Master .ssh]$ #显示回到了Master机器
SSH无密码登陆Linux就完成了。
前段时间Redis未授权访问(就是无密码)导致可以远程连接Redis后修改Redis持久文件,并写入公钥文件到特定目录,导致可以远程无密码连接到ssh,就是可以通过这样配置公钥,并通过redis写入特定目录。
四、Hadoop单机安装
单机模式我在一台测试服务器172.26.5.187上做的测试,把187服务器的主机名修改为Master,并修改Hosts文件机器名和IP映射,需要用root去执行命令:
vi /etc/sysconfig/network
修改:HOSTNAME=Master
vi /etc/hosts 172.26.5.187 Master
然后在187服务器上创建一个hadoop用户:
useradd -m hadoop -s /bin/bash 创建hadoop用户,-m创建主目录 -s /bin/bash 指定用户的登录Shell passwd hadoop mima.. #修改设置hadoop密码 usermod -g root hadoop #加入root组
通过http://mirrors.hust.edu.cn/apache/hadoop/common/hadoop-2.6.3/hadoop-2.6.3.tar.gz 镜像地址下载2.6.3版本。
把hadoop安装到/usr/local/hadoop下,把hadoop-2.6.3.tar.gz放到/usr/local目录,执行命令:
rm -rf /usr/local/hadoop # 删掉旧的(如果存在) tar -zxf ~/hadoop-2.6.3.tar.gz -C /usr/local
把文件夹修改为hadoop,执行命令,修改文件夹所属用户和组:
chown -R hadoop:hadoop /usr/local/hadoop
然后用hadoop登录后执行:
cd /usr/local/hadoop ./bin/hadoop version
输出结果:
[hadoop@Master hadoop]$ ./bin/hadoop version Hadoop 2.6.3 Subversion https://git-wip-us.apache.org/repos/asf/hadoop.git -r cc865b490b9a6260e9611a5b8633cab885b3d247 Compiled by jenkins on 2015-12-18T01:19Z Compiled with protoc 2.5.0 From source with checksum 722f77f825e326e13a86ff62b34ada This command was run using /usr/local/hadoop/share/hadoop/common/hadoop-common-2.6.3.jar
表示安装成功
五、Hadoop单机模式运行
把hadoop-2.6.3.tar.gz解压到187服务器:/usr/local/hadoop后,执行命令:
mkdir ./input cp ./etc/hadoop/*.xml ./input
直接测试自带的jar包程序,从input文件夹下的文件分析含有dfs..正则的字符串,如果有就输出到output文件夹:
[hadoop@Master hadoop]$./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.3.jar grep ./input ./output ‘dfs[a-z]+‘
发现会有报错,大意是说权限不够,执行命令:
chmod -R 744 ./bin/ #改变当前目录读写权限
再次执行:
./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.3.jar grep ./input ./output ‘dfs[a-z]+‘
执行后输出一串......
File Input Format Counters
Bytes Read=123
File Output Format Counters
Bytes Written=23
..........
说明执行成功,查看:
[hadoop@p5 hadoop]$ cat ./output/* 1 dfsadmin
这里的数据实际为part-r-00000的内容
[hadoop@p5 hadoop]$ ls output part-r-00000 _SUCCESS
注意,Hadoop 默认不会覆盖结果文件,因此再次运行上面实例会提示出错,需要先将 ./output 删除。
rm -r ./output
单机模式运行成功。
六、Hadoop伪分布式部署
首先进入到/usr/local/hadoop下:
[hadoop@Master hadoop]$ pwd /usr/local/hadoop
修改core-site.xml和hdfs-site.xml配置文件,执行:
vi ./etc/hadoop/core-site.xml
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://172.26.5.187:9000</value>
</property>
</configuration>
vi ./etc/hadoop/hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/data</value>
</property>
</configuration>
配置完成后,执行 NameNode 的格式化(只执行一次即可,以后不需要执行了):
./bin/hdfs namenode -format
成功的话,会看到 “successfully formatted” 和 “Exiting with status 0″ 的提示,若为 “Exiting with status 1″ 则是出错。
开启 NaneNode 和 DataNode 守护进程:
[hadoop@Master hadoop]$ ./sbin/start-dfs.sh
可能会报错:
bash: ./sbin/start-dfs.sh: 权限不够
执行命令,添加执行权限:
chmod -R 744 ./sbin
再执行./sbin/start-dfs.sh可能还会报错:
localhost: Error: JAVA_HOME is not set and could not be found.
执行下面命令解决:
[hadoop@Master hadoop]$ vi ./etc/hadoop/hadoop-env.sh
新增:
export JAVA_HOME=/usr/java/jdk1.6.0_38
这里设置Jdk的路径
再次执行:
[hadoop@p5 hadoop]$ ./sbin/start-dfs.sh 16/01/06 16:05:50 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Starting namenodes on [localhost]
可以忽略,并不会影响正常使用。
Jps查看当前java进程情况:
[hadoop@p5 hadoop]$ jps 25978 Jps 25713 DataNode 25876 SecondaryNameNode 25589 NameNode
如果缺少任何一个进程,都表示启动失败,需要./sbin/stop-dfs.sh停止后,检查/usr/local/hadoop/logs/hadoop-hadoop-XXX-Master.log对应XXX名称的日志
浏览器输入:http://172.26.5.187:50070/ 可访问了
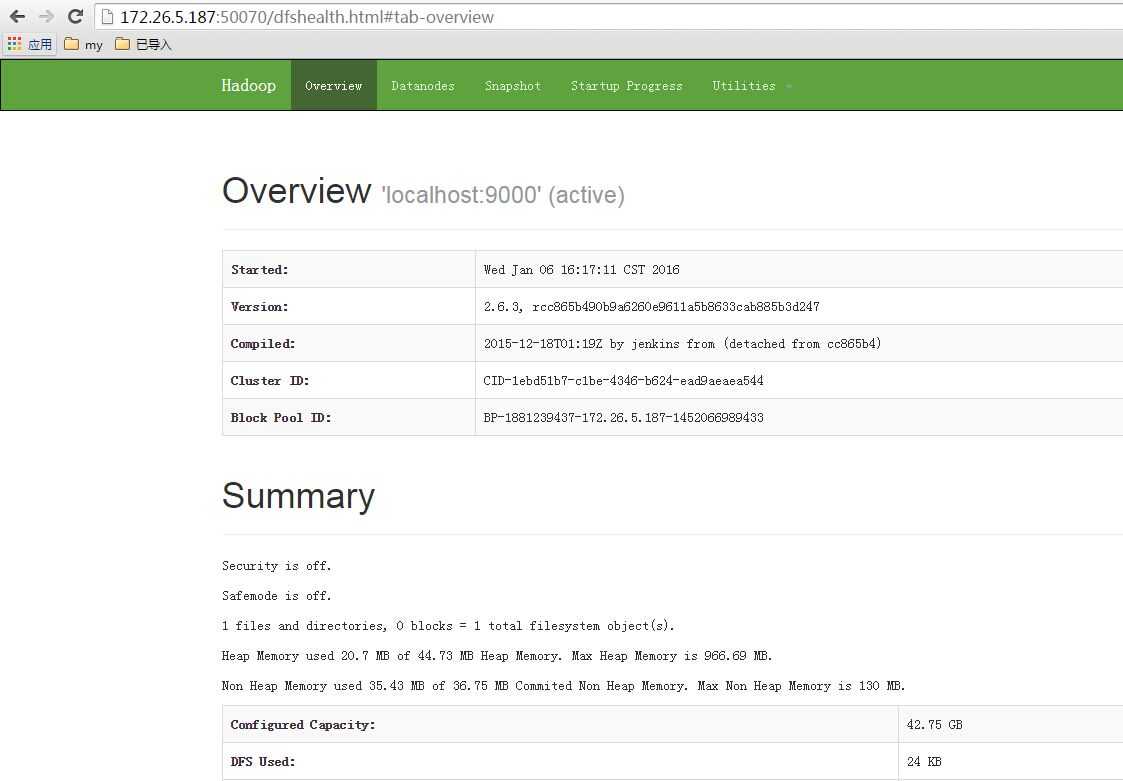
下面在伪分布式下运行一个自带的demo实例:
首先创建HTFS用户目录和input文件夹:
./bin/hdfs dfs -mkdir -p /user/hadoop ./bin/hdfs dfs -mkdir input ./bin/hdfs dfs -put ./etc/hadoop/*.xml input #复制当前目录下/etc/hadoop/下的所有xml文件到HTFS的input目录里,
通过下面指令查看复制过去的文件夹:
./bin/hdfs dfs -ls input
执行刚才单机版的测试jar包程序:
./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-*.jar grep input output ‘dfs[a-z.]+‘
执行后输出一串..
File Input Format Counters
Bytes Read=219
File Output Format Counters
Bytes Written=77
查看HDFS里output文件夹:
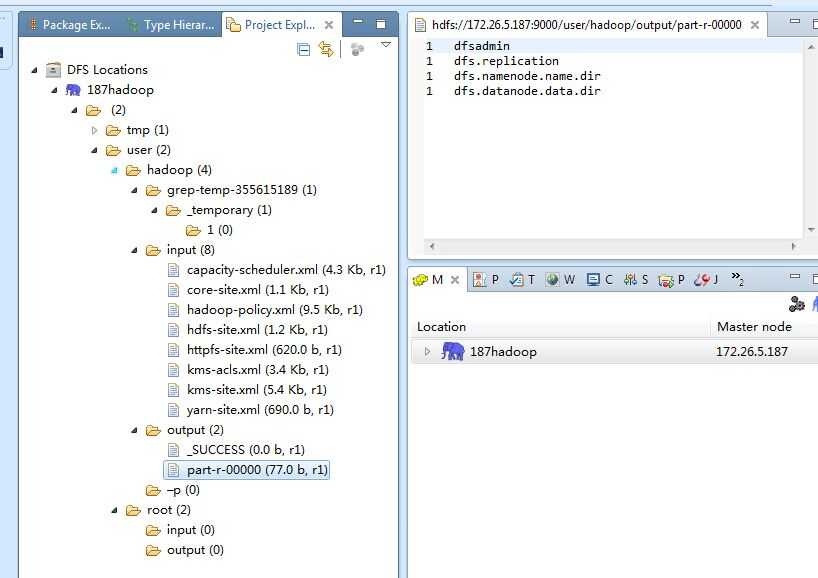
./bin/hdfs dfs -cat output/* 1 dfsadmin 1 dfs.replication 1 dfs.namenode.name.dir 1 dfs.datanode.data.dir

截图是之前没有修改hostname,所以机器名还是p5。
发现已找到多个字符串,可以把HDFS里的文件取回到output文件夹:
rm -r ./output # 先删除本地的 output 文件夹(如果存在) ./bin/hdfs dfs -get output ./output # 将 HDFS 上的 output 文件夹拷贝到本机 cat ./output/* #查看当前用户目录下的output文件夹下内容
这里伪分布式程序就运行完成了。
上述通过 ./sbin/start-dfs.sh 启动 Hadoop,仅仅是启动了 MapReduce 环境,我们可以启动 YARN ,让 YARN 来负责资源管理与任务调度。
修改文件:
mv ./etc/hadoop/mapred-site.xml.template ./etc/hadoop/mapred-site.xml
[hadoop@p5 hadoop]$ vi ./etc/hadoop/mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
[hadoop@p5 hadoop]$ vi ./etc/hadoop/yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
执行命令:
./sbin/start-yarn.sh # 启动YARN ./sbin/mr-jobhistory-daemon.sh start historyserver # 开启历史服务器,才能在Web中查看任务运行情况
Jps查看:
[hadoop@Master hadoop]$ jps 27492 Jps 27459 JobHistoryServer 25713 DataNode 27013 ResourceManager 27283 NodeManager 25876 SecondaryNameNode 25589 NameNode
启动成功后可以在 http://172.26.5.187:8088/cluster 下查看任务运行情况了。
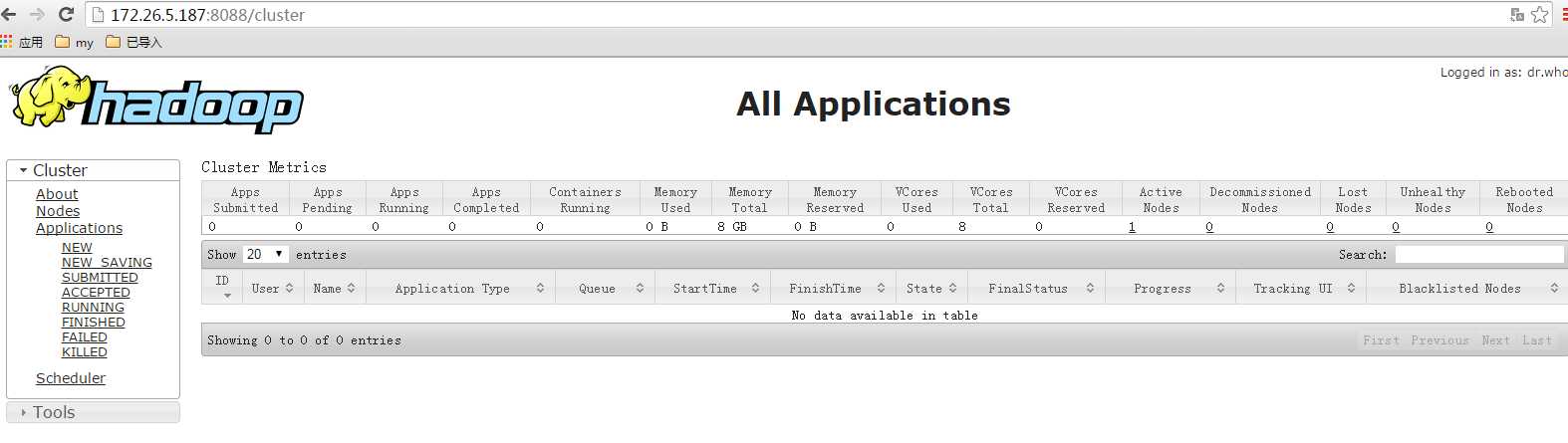
如果不想启动 YARN,务必把配置文件 mapred-site.xml 重命名,改成 mapred-site.xml.template
关闭 YARN 的脚本如下:
./sbin/stop-yarn.sh ./sbin/mr-jobhistory-daemon.sh stop historyserver
七、Hadoop集群部署
使用172.26.5.187 做Master和172.26.5.20 做Slave 测试
先187上操作:
[hadoop@Master ~]$ su root
密码:
[root@p5 hadoop]# vi /etc/sysconfig/network NETWORKING=yes HOSTNAME=p5
修改:HOSTNAME=Master
再修改hosts文件
[root@p5 hadoop]# vi /etc/hosts 172.26.5.187 Master 172.26.5.20 Slave1
然后在20服务器上操作:
useradd -m hadoop -s /bin/bash 创建hadoop用户,-m创建主目录 -s /bin/bash 指定用户的登录Shell passwd hadoop mima... usermod -g root hadoop
然后root权限下:
[root@Slave1 ~]# vi /etc/sysconfig/network NETWORKING=yes HOSTNAME=p2
修改:HOSTNAME=Slave1
[root@Slave1 ~]# vi /etc/hosts 172.26.5.20 Slave1 172.26.5.187 Master
测试:
ping Master -c 3 ping Slave1 -c 3
187和20都能ping通说明配置没有问题了。
187 Master上操作(单机模式下已操作过):
cd ~/.ssh rm ./id_rsa* ssh-keygen -t rsa # 一直按回车就可以 cat ./id_rsa.pub >> ./authorized_keys
完成后可执行 ssh Master 验证一下(可能需要输入 yes,成功后执行 exit 返回原来的终端)。接着在 Master 节点将上公匙传输到 Slave1 节点:
scp ~/.ssh/id_rsa.pub hadoop@Slave1:/home/hadoop/
输入完成后会提示传输完毕,如下图所示:
id_rsa.pub 100% 391 0.4KB/s 00:00
接着在 Slave1 172.26.5.20节点上,将 ssh 公匙加入授权:
mkdir ~/.ssh # 如果不存在该文件夹需先创建,若已存在则忽略 cat ~/id_rsa.pub >> ~/.ssh/authorized_keys rm ~/id_rsa.pub # 用完就可以删掉了
172.26.5.187上测试无密码连接20服务器:
[hadoop@Master .ssh]$ ssh Slave1 [hadoop@Slave1 ~]$ exit #exit回到187服务器 logout Connection to Slave1 closed. [hadoop@Master .ssh]$
187上执行:
[hadoop@Master .ssh]$ vi ~/.bashrc export PATH=$PATH:/usr/local/hadoop/bin:usr/local/hadoop/sbin
修改187配置文件:
[hadoop@Master .ssh]$ cd /usr/local/hadoop/etc/hadoop [hadoop@Master hadoop]$ vi slaves
删除localhost,新增一行:Slave1
文件 slaves,将作为 DataNode 的主机名写入该文件,每行一个。
187上cd到 /usr/local/hadoop/etc/hadoop目录,修改配置文件:
vi core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://Master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
</configuration>
vi hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>Master:50090</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/data</value>
</property>
</configuration>
vi mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>Master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>Master:19888</value>
</property>
</configuration>
vi yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>Master</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
cd /usr/local
rm -rf ./hadoop/tmp # 删除 Hadoop 临时文件
rm -rf ./hadoop/logs/* # 删除日志文件
然后把187上修改了配置文件后的hadoop文件夹压缩后发送到Slave机器上,这里上传到20服务器。
tar -zcf ~/hadoop.master.tar.gz ./hadoop # 先压缩到用户主目录下 cd ~ [hadoop@Master ~]$ scp ./hadoop.master.tar.gz Slave1:/home/hadoop #再复制到Salve1 hadoop.master.tar.gz 100% 187MB 11.0MB/s 00:17
复制完成后,到Slave1 20服务器上操作:
rm -rf /usr/local/hadoop # 删掉旧的(如果存在) tar -zxf ~/hadoop.master.tar.gz -C /usr/local chown -R hadoop:hadoop /usr/local/hadoop
然后在187上start启动:
[hadoop@Master hadoop]$ ./sbin/start-dfs.sh ./sbin/start-yarn.sh # 启动YARN ./sbin/mr-jobhistory-daemon.sh start historyserver # 开启历史服务器,才能在Web中查看任务运行情况
执行后可能会报错:
namenode进程启动不了,报错:Storage directory /usr/local/hadoop/tmp/dfs/name does not exist,需要重新格式化namenode。
在187上执行:hdfs namenode -format
然后需要关闭187和20服务器的防火墙,否则会导致端口访问不通,莫名其妙的错误:
[hadoop@Master local]$ service iptables stop [hadoop@Slave1 local]$ service iptables stop
再次187上start启动后,然后在187上查询如下:
[hadoop@Master hadoop]$ hdfs dfsadmin -report 16/01/21 17:55:44 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Configured Capacity: 52844687360 (49.22 GB) Present Capacity: 44751773696 (41.68 GB) DFS Remaining: 44741738496 (41.67 GB) DFS Used: 10035200 (9.57 MB) DFS Used%: 0.02% Under replicated blocks: 7 Blocks with corrupt replicas: 0 Missing blocks: 0 ------------------------------------------------- Live datanodes (1): Name: 172.26.5.20:50010 (Slave1) Hostname: Slave1 Decommission Status : Normal Configured Capacity: 52844687360 (49.22 GB) DFS Used: 10035200 (9.57 MB) Non DFS Used: 8092913664 (7.54 GB) DFS Remaining: 44741738496 (41.67 GB) DFS Used%: 0.02% DFS Remaining%: 84.67% Configured Cache Capacity: 0 (0 B) Cache Used: 0 (0 B) Cache Remaining: 0 (0 B) Cache Used%: 100.00% Cache Remaining%: 0.00% Xceivers: 1 Last contact: Thu Jan 21 17:55:44 CST 2016
如果显示Live datanodes (1)表示有 1 个 Datanodes,表示启动成功。
在这个过程中,可能还会出现问题:
比如20服务器上DataNode和NodeManager进程启动成功后自动死亡,查看日志报错:
Caused by: java.net.UnknownHostException: p2: p2...
说明可能是机器名没有修改成功,推出shh,重新连接后修改/etc/sysconfig/network里的HOSTNAME值即可。
最后启动服务在187上查看:
[hadoop@Master hadoop]$ jps 10499 ResourceManager 10801 Jps 10770 JobHistoryServer 10365 SecondaryNameNode 10188 NameNode
20上查看:
[hadoop@Slave1 ~]$ jps 4977 NodeManager 5133 Jps 4873 DataNode
表示启动成功了。
下面在集群上执行刚才测试过的自带demo程序:
187服务器执行:(如果再次执行,需要先删除:./bin/hdfs dfs -rm -r output # 删除 output 文件夹)
hdfs dfs -mkdir -p /user/hadoop hdfs dfs -mkdir input hdfs dfs -put /usr/local/hadoop/etc/hadoop/*.xml input [hadoop@Master hadoop]$ hadoop jar /usr/local/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-*.jar grep input output ‘dfs[a-z.]+‘
可能会报错:java.net.NoRouteToHostException: No route to host
这时需要确保187和20服务器防火墙是否关闭,root权限下查看防火墙:
service iptables status
需要保证用root账户关闭防火墙:service iptables stop
在187上执行:
[hadoop@Master hadoop]$ ./bin/hdfs dfs -put ./etc/hadoop/*.xml input [hadoop@Master hadoop]$ ./bin/hdfs dfs -rm -r output [hadoop@Master hadoop]$ ./bin/hdfs dfs -ls input [hadoop@Master hadoop]$ ./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-*.jar grep input output ‘dfs[a-z.]+‘
集群测试成功!
八、Eclipse插件安装
要在 Eclipse 上编译和运行 MapReduce 程序,需要安装 hadoop-eclipse-plugin,https://github.com/winghc/hadoop2x-eclipse-plugin这里有源代码和release目录下打好包的hadoop-eclipse-plugin-2.6.0.jar等3个版本的jar包。我是通过其他渠道下载的hadoop-eclipse-plugin-2.6.3.jar版本的插件,安装到MyEclipse里。
在MyEclipse里window->Preferences->Hadoop Map/Reduce,Hadoop installation directory选择到win7本地的Hadoop文件夹,比如我吧Hadoop解压后放到:D:\hadoop-2.6.3里。
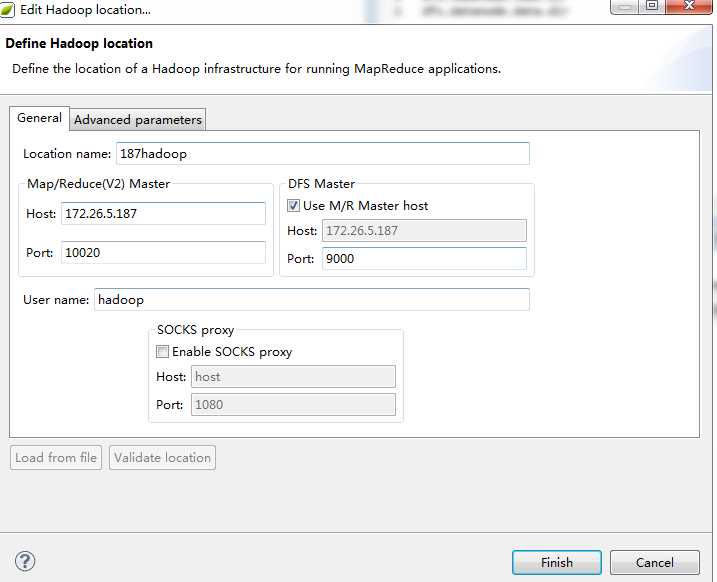
Window->Show View->Other选择Map/Reduce,在面板中单击右键,选择 New Hadoop Location,在General选项里,因为之前fs.defaultFS的值设置为hdfs://172.26.5.187:9000,所以DFS Master 的 Port 写为9000,Location Name随便写,比如我写成187Hadoop,Map/Reduce(V2) Master的Host写172.26.5.187。最后点击Finish则完成配置。
配置完成后Project Explorer 中有DFS Location。双击下面的187Hadoop则可查看187集群下的HDFS文件了。
但通过WIN7连接远程linux的Hadoop集群会报错,比如后面Myeclipse用程序执行程序,可能会报如下错:
..................................... INFO client.RMProxy: Connecting to ResourceManager at Master/172.26.5.187:8032 INFO mapreduce.JobSubmitter: Cleaning up the staging area /tmp/hadoop-yarn/staging/SL/.staging/job_1452581976741_0001 Exception in thread "main" org.apache.hadoop.security.AccessControlException: Permission denied: user=SL, access=EXECUTE, inode="/tmp":hadoop:supergroup:drwxrwx--- at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.checkFsPermission(FSPermissionChecker.java:271) ...................... Caused by: org.apache.hadoop.ipc.RemoteException(org.apache.hadoop.security.AccessControlException): Permission denied: user=SL, access=EXECUTE, inode="/tmp":hadoop:supergroup:drwxrwx--- at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.checkFsPermission(FSPermissionChecker.java:271) ..........................
通过查看,user=SL,SL是我当前WIN7登录的用户名,网上介绍有几种解决方案,我用了最简单的解决方案,配置WIN7系统环境变量:HADOOP_USER_NAME=hadoop即可。
九、安装调试过程中我遇到的问题
问题在上面每个步骤都写了,这里再汇总一下:
1、每次执行MapReduce程序需要删除输出目录,比如:
需要先删除:./bin/hdfs dfs -rm -r output # 删除 output 文件夹
2、报错:java.net.NoRouteToHostException: No route to host
解决:可能是防火墙没有关闭,导致网络访问连接问题。需要关闭集群所有服务器防火墙:service iptables stop(注意这里是直接关闭防火墙,生成环境最好针对端口开放特定访问权限)
3、执行./sbin/start-dfs.sh报错:localhost: Error: JAVA_HOME is not set and could not be found.
解决:i ./etc/hadoop/hadoop-env.sh,新增:
export JAVA_HOME=/usr/java/jdk1.6.0_38
4、./sbin/start-dfs.sh执行后,如果“NameNode”、”DataNode” 、“SecondaryNameNode”进程没有启动成功,则查看对应/usr/local/hadoop/logs/目录下的日志。
5、/etc/hadoop/core-site.xml文件里fs.defaultFS如果配置为hdfs://localhost:9000等,有可能导致9000端口其他服务器不能telnet,导致莫名其妙的问题。
解决:通过在187上执行:netstat -ntl,查看到比如如下:
tcp 0 0 127.0.0.1:9000 0.0.0.0:* LISTEN
说明9000端口被127.0.0.1监听,导致只能本机能连接9000端口,其他服务器不能连接,如果是:
tcp 0 0 0.0.0.0:9000 0.0.0.0:* LISTEN
则表示任何机器都可以连接9000端口。
6、Myeclipse连接DFS Locations下的Hadoop集群报错:An internal error occurred during: "Map/Reduce location status updater".
187上cd到/usr/local/hadoop下执行:./bin/hdfs dfs -mkdir -p /user/root/input
./bin/hdfs dfs -mkdir -p /user/root/output,这里还可能是插件包问题或系统环境变量HADOOP_USER_NAME没有设置为Master机器连接的用户名。
如需转载,请注明来自:http://lawson.cnblogs.com
Linux上搭建Hadoop2.6.3集群以及WIN7通过Eclipse开发MapReduce的demo
标签:
原文地址:http://www.cnblogs.com/Lawson/p/5149537.html