标签:
skewed classes

skewed classes: 一种类里面的数量远远高于(或低于)另一个类,即两个极端的情况。
预测cancer的分类模型,如果在test set上只有1%的分类误差的话,乍一看是一个很好的结果,实际上如果我们将所有的y都预测为0的话(即都不为cancer),分类误差为0.5%(因为cancer的比率为0.5%)。error降低了,那这是对算法的一种改进吗?显然不是的。因为后面一种方法实际上什么也没有做(将所有的y=0),不是一种好的机器学习算法。所以这种error metrics对于skewed classes是不行的,那么我们要寻求一种适用于skewed classes上面的error metrics。
precision(查准率) & recall(召回率)
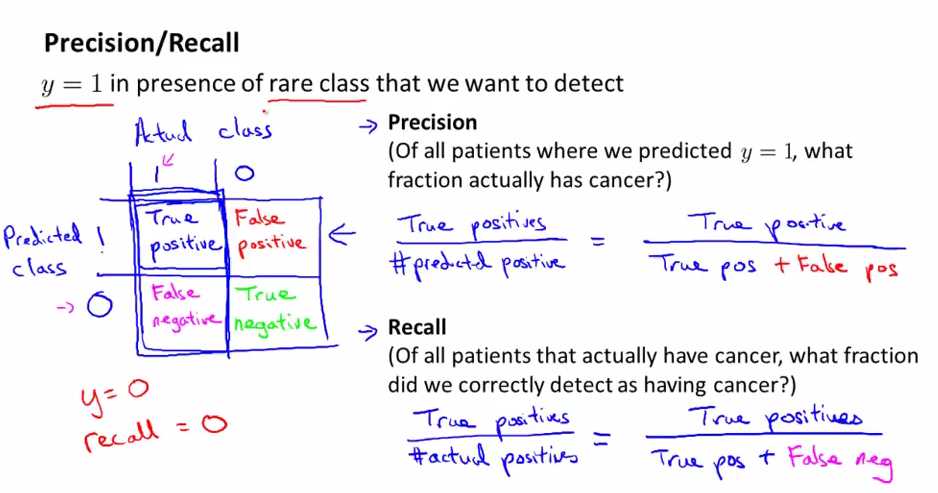
用测试集来评估一个分类模型: 如上图所示,在实际值与预测值上进行一个2*2的分类(假设这是一个2分类问题),将它们分为真阳性(实际是postive,预测也是postive),假阳性(预测是postive,实际是negative),真阴性(实际是negative,预测也是negative),假阴性(预测也是negative,实际是positive)。
precision(查准率):真阳性(True positive)/预测为positive(阳性的)数量(predicted y=1)= 真阳性/(真阳性+假阳性)
recall(召回率): 真阳性(True positive)/实际为positive(阳性的)的数量 (actually have cancer) = 真阳性/(真阳性+假阴性)
这样当我们用precision与recall来评估上一个例子的算法时(将所有的y都预测为0),这样它的true positive 就为0,这样它的precision与recall就都为0,即能知道这不是一个好的算法,所以我们可以通过precision各recall来评估一个算法是否好。也给了我们一个更直接的方法来评估模型的好坏。
我们经常使用y=1(不是y=0)来做为很少(rare)出现的那个类(如为cancer的类),即做为要检测出来的类。
总结
Machine learning system design---Error metrics for skewed(偏斜的) classes
标签:
原文地址:http://www.cnblogs.com/yan2015/p/5158815.html