标签:
在本书的最后一章,将引导您通向2014年发布的一个工具,称为walbouncer。本书中的大多数技巧说明了如何复制整个数据库实例,如何分片,等等。在最后一章,是关于wabouncer的,它是所有关于过滤事务日志流来选择性地复制数据库对象从一台服务器到到一组(不一定是完全相同的)slave。
本章将涵盖以下主题:
• walbouncer的基本概念
•安装walbouncer
•选择性地复制数据库,表,和表空间
walbouncer 工具适用于 PostgreSQL 9.4 或者更高版本。
walbouncer 的概念
PostgreSQL事务日志的目的是帮助一个在崩溃事件中出现故障的数据库实例恢复自身。它也可以用来复制 整个数据库实例,正如我们在本书中关于同步复制与异步复制的章节所讨论的。
问题在于复制整个数据库实例是必须的。在许多现实世界的场景中,这是一个问题。让我们假设,有一个中心服务器,它包含许多大学的学生学习信息。每个大学都应该有一个数据的副本。作为PostgreSQL9.4,使用一个数据库实例这是不可能的,因为流复制只具有完全复制一个数据库的能力。运行许多实例显然是非常多的工作,也许不是所期望的一套方法。
walbouncer背后的思想是连接到PostgreSQL事务日志并过来它。在这个场景中,slave将只接收数据的一个子集,从而过滤掉可能是规则的关键或者一个安全点的视图的所有数据。在我们的大学的例子中,每个大学将只会有它自己的数据库的复制,因此,没有办法看到其它组织的数据。当涉及到安全系统时,隐藏数据是一个巨大的进步。对于出于分片的目的的walbouncer来说可能是一个使用场景。
下图显示了这是如何工作的:
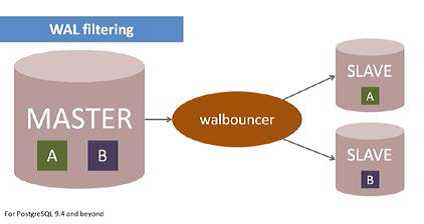
walbouncer工具是一个位于master和slave之间的一个进程。它连接到master,获取事务日志,并在它被传输到slave之前过滤它。在这个例子中,有两个slave可以用来消耗事务日志,就像普通slave一样。
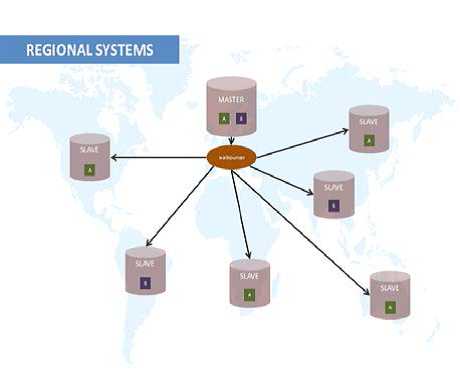
对地理上分布的数据库系统来说,walbouncer工具是理想的,因为它使我们能够很容易地决定那些数据要去哪里,哪个数据库需要在哪个位置。这里展示了一个基本的方框图:
过滤 XLOG
现在核心的问题是:walbouncer是如何过滤日志的?记住,事务日志的位置是非常关键的,在很多情况下,篡改这些事务日志的位置是很重要的,危险的,一点都不可行的。
解决这个问题的的关键在于PostgreSQL的核心深处。核心知道如何处理仿制的事务日志条目。剪下所有注定不能到达一个特定的服务器的所有数据,仿制的XLOG被注入,代替原来的一个。现在slave可以安全地消耗XLOG了并忽略那些仿制的记录。事实上,这种技术的妙处在于master和slave可以保持不变—不需要修补。所有的工作可以完全由walbouncer来做,它只是简单地作为某种XLOG的代理。
所使用的技术的因果关系如下:
•每个slave将获得相同数目的XLOG记录,不管目标系统中实际更改的数据量
•元数据(系统表)必须被完全地复制,千万不能被留下
•目标系统仍然会看到一个特定的数据库应该存在,但使用它 会失败。
最后一项特别值得注意。记住,系统无法分析特定XLOG记录的语义;它所做的所有 是检查它是否还需要。因此,元数据必须被复制。当一个slave系统尝试读取过滤的数据时,它将接收到一个令人讨厌的错误,该错误表明数据文件丢失。如果不能从磁盘读文件,则会显示错误并回滚。这种行为可能会使一些人跟到困惑,但这是唯一解决潜在技术问题的可能途径。
安装 walbouncer
walbouncer工具可以免费地从Cybertec网站下载(http://www.cybertec.at/postgresql_produkte/walbouncer/)并使用以下步骤安装:
1.为了本书的目的,使用了下面的文件:
wget http://cybertec.at/download/walbouncer-0.9.0.tar.bz2
2. 首先要做的事情是解压tar包,如下:
tar xvfj walbouncer-0.9.0.tar.bz2
3.一旦包已经被解压,您就可以进入该目录。在调用make之前,检查缺失的库是非常重要的。确保支持YAML 。在我的 CentOS测试系统中,下面的命令可以完成该工作:
[root@localhost ~]# yum install libyaml-devel
4.库将通过这些行来安装:
---> Package libyaml-devel.x86_64 0:0.1.4-11.el7_0 will be installed
--->Processing Dependency: libyaml = 0.1.4-11.el7_0 for package: libyaml-devel-0.1.4-11.el7_0.x86_64
5.下一步,只调用make。代码干净地编译。最后,只剩下make install:
[root@localhost walbouncer-0.9.0]# make install
cp walbouncer /usr/local/pgsql/bin/walbouncer
运行walbouncer所需要的二进制包将被复制到您的PostgreSQL二进制目录(在我的例子中, 是 /usr/local/pgsql/).
正如您可以看到的,部署walbouncer是很容易的,并且所有它需要的是几个命令。
配置 walbouncer
一旦代码被成功地部署了,就必须拿出一个简单的配置来告诉walbouncer做什么。为了演示walbouncer是如何工作的,这里已经创建了一个简单的安装程序。在这个例子中,两个数据库存在于master。它们中只有一个最终会在slave上:
$ createdb a
$ createdb b
目标是复制a到slave并跳过其它的。
在开始做基础备份之前,做一个walbouncer的config备份是有意义的。一个基本的配置是非常简单而且容易执行的:
listen_port: 5433
master:
host: localhost
port: 5432
configurations:
- slave1:
filter:
include_databases: [a]
配置有一下组件组成:
•listen_port:这是必要的。它定义了walbouncer使用哪个端口监听。slave可以连接到这个端口并且直接从bouncer流传输事务日志。
•master:下一节将告诉walbouncer去哪里找到它的master。在我们的例子中,master在同一台主机上并且监听5432端口。注意,没有数据库被列出。该系统连接到XLOG流,所以不需要数据库信息。
•configurations:这涵盖了slave配置。可以列出多个slave。对于每一个slave,可以使用几个过滤器。在这个例子中,只包含a数据库;其余的数据库被过滤掉。
创建基础备份
一旦写完了配置,是时候克隆一个初始的数据库实例了。棘手的事情是,没有pg_basebackup之类的工具,它为您做大多数的工作。原因是,pg_basebackup被设计用来复制整个数据库实例。在walbouncer的例子中,思想是在目标系统上只存在部分数据。因此,用户必须回到创建备份的基本方法。选择的方法是执行基础备份的传统方法。
然而,在开始之前,准备好标准流复制的master是很重要的。这包括:
•调整 postgresql.conf (wal_level, wal_keep_segments, max_wal_ senders, 等等)
•在master上调整pg_hba.conf
•在slave上设置数据目录为chmod 700
所有这些步骤都已经在第四章中描述过了,设置异步复制。正如已经提到的,棘手的部分是初始的基础备份。假设数据库必须被复制,就必须找到它的对象ID:
test=# SELECT oid, datname FROM pg_database WHERE datname = ‘a‘;
oid | datname
-------+---------
24576 | a
(1 row)
在这个例子中,对象ID是24576。一般的规则如下:所有OID大于16383的数据库有用户创建。这是唯一可以用来有用地过滤数据库的方法。
现在到maser的数据目录并复制除了基础目录的一切到slave所在的目录。在这个例子中,使用了这个小把戏:没有以a开始的文件名,所以安全地复制以c开始的一切并把备份标签添加到复制进程是可能的。现在,该系统将复制除了基础目录的一切:
cp -Rv [c-z]* backup_label ../slave/
一旦一切都被复制到了slave,在这个例子中这恰好发生在一台服务器上,缺少的基础目录可以在slave目录中创建:
$ mkdir ../slave/base
在下一步中,所有需要的数据库都可以被复制。目前,样本master上的情况如下:
[hs@localhost base]$ ls -l
total 72
drwx------ 2 hs hs 8192 Feb 24 11:53 1
drwx------ 2 hs hs 8192 Feb 24 11:52 13051
drwx------ 2 hs hs 8192 Feb 25 11:49 13056
drwx------ 2 hs hs 8192 Feb 25 11:48 16384
drwx------ 2 hs hs 8192 Feb 25 10:32 24576
drwx------ 2 hs hs 8192 Feb 25 10:32 24577
所有大于16383的OID都是有终端用户创建的。在这种情况下,有三个这样的数据库。
因此,所有的系统数据库(template0,template1,和postgres)以及需要的在slave上的数据库可以被复制到基础目录:
cp -Rv 24576 1 13051 13056 ../../slave/base/
[注意,通常情况下,slave在一个远程系统上,所以应该使用rsync或者类似工具。在这个例子中,一起都是在同一个节点来使您的生活更容易。]
重要的事情是,在在大多设置中,基础目录是到目前为止最大的目录。一旦数据被获得,备份可以被停止,如下:
test=# SELECT pg_stop_backup();
NOTICE: WAL archiving is not enabled; you must ensure that all required WAL segments are copied through other means to complete the backup
pg_stop_backup
----------------
0/2000238
(1 row)
到目前为止,所有的一切都和 常规的流复制一样—唯一的区别是并不是基础目录的所有目录都实际地同步到slave。
在接下来的步骤中,创建一个简单地recovery.conf文件:
slave]$ cat recovery.conf
primary_conninfo = ‘host=localhost port=5433‘
standby_mode = on
这里最重要的是slave的端口必须写到配置文件中去。slave将再也不会不会直接看到master了,但是会通过walbouncer消耗它所有的XLOG。
启动walbouncer
一旦完成了配置,就可以启动walbouncer了。walbouncer的语法很简单:
$ walbouncer –help
walbouncer工具代理PostgreSQL的流复制连接并有选择性地过滤
Options:
-?, --help Print this message
-c, --config=FILE Read configuration from this file.
-h, --host=HOST Connect to master on this host.
Default localhost
-P, --masterport=PORT Connect to master on this port.
Default 5432
-p, --port=PORT Run proxy on this port. Default 5433
-v, --verbose Output additional debugging information
所有相关的信息都在config文件中,所以可以确保启动:
$ walbouncer -v -c config.ini
[2015-02-25 11:56:57] wbsocket.c INFO: Starting socket on port 5433
选项-v不是强制的。它所做的一切都是给我们多提供一点正在发生的信息。一旦starting socket信息显示出来,就意味着所有的事情都在完美地进行。
最后,可以启动slave了。切换到slave的数据目录并启动它,如下:
slave]$ pg_ctl -D . -o "--port=5444" start
server starting
LOG: database system was shut down in recovery at 2015-02-25 11:59:12 CET
LOG: entering standby mode
LOG: redo starts at 0/2000060
LOG: record with zero length at 0/2000138
INFO: WAL stream is being filtered
DETAIL: Databases included: a
LOG: started streaming WAL from primary at 0/2000000 on timeline 1
LOG: consistent recovery state reached at 0/2000238
LOG: database system is ready to accept read only connections
这里的点表示本地目录(当然,把完整的路径放到这里也是一个很好的想法—绝对地)。接下来是 另外一个技巧:当为了测试的目的在同一台服务器上一次又 一次地同步slave,一遍又一遍地更改端口是很烦人的。选项-O有助于在postgresql.conf中重写配置文件,以便系统可以直接使用其它的端口启动。
[如果PostgreSQL在独立的服务器上启动,这对通过正常的初始化程序来启动服务器当然很有用。]
只要slave开始工作,walbouncer将开始发布更多的日志信息,告诉我们更多关于流的状态:
[2015-02-25 11:58:37] wbclientconn.c INFO: Received conn from 0100007F:54729
[2015-02-25 11:58:37] wbclientconn.c DEBUG1: Sending authentication packet
[2015-02-25 11:58:37] wbsocket.c DEBUG1: Conn: Sending to client 9 bytes of data
[2015-02-25 11:58:37] wbclientconn.c INFO: Start connecting to host=localhost port=5432 user=hs dbname=replication replication=true application_name=walbouncer
FATAL: no pg_hba.conf entry for replication connection from host "::1", user "hs"
一旦这些消息被显示出来,系统就处于运行状态了并且事务日志在从master流向slave。
现在是测试的时候了:
$ psql -h localhost -p 5444 b
FATAL: database "b" does not exist
DETAIL: The database subdirectory "base/24577" is missing.
当一个到过滤的数据库的连接被确立,PostgreSQL将会出错并告诉用户服务请求所需的文件不存在。这正是预期的行为种类—由于缺乏数据请求应该被拒绝。
当连接到是数据库包含一个数据库实例的时候,所有的事情工作起来像一个魔力:
$ psql -h localhost -p 5444 a
psql (9.4.1)
Type "help" for help.
a=#
下一个测试检查数据是否很好地从master复制到了slave。要执行该检查,可以在master上场景一个表:
a=# CREATE TABLE a (aid int);
CREATE TABLE
正如预期的那样,该表将很好地在slave上终止。
a=# \d
List of relations
Schema | Name | Type | Owner
--------+------+-------+-------
public | a | table | hs
(1 row)
该系统现在已经准备就绪并且可以安全的使用。
使用附加配置选项
walbouncer工具可以为用户做的事情远远超出了目前所列出来的。一些额外的配置参数也是可以用的。
第一个例子显示了如果有一个以上的slave可以做什么:
listen_port: 5433
master:
host: localhost
port: 5432
configurations:
- slave1:
match:
application_name: slave1
filter:
include_tablespaces: [spc_slave1]
exclude_databases: [test]
在配置块中,有一个slave1的部分。如果一个slave使用slave1作为application_name(按照application_name列出的条款)连接自身,slave1的配置将被选中。如果这个配置被服务器(可以有很多这样的slave部分)选中,在下一个块中列出的过滤器将被应用。
基本上,每种类型的过滤器有两种体现:include_ 和exclude_。在这个例子中,只包含spc_slave1表空间。最后的设置说,只有test被排除(如果表空间过滤器匹配它们,所有其它数据库被包括)。
当然,这样看描述也是有可能的:
exclude_tablespaces: [spc_slave1]
include_databases: [test]
在种情况下,所有表空间只有spc_slave1被包括。只有系统数据库和数据库test被复制。鉴于这些include_ 和 exclude_ 设置,可以灵活地配置复制什么到那个slave。
请记住,同步复制也需要application_name。如果通过walbouncer传递的application_name参数与在synchronous_standby_names里面列出来的application_name一样,就可以进行同步复制。
正如您可以看到的,application_name这里用于两个目的:它决定使用哪些config块,并告诉master需要哪个级别的复制。
调整过滤规则
经常被问的一个问题是看,是否可以调整过滤规则。对象随后可能被添加,或者对象可能被删除。在许多情况下,这是人们经常问的一个很常见的场景。
改变一个walbouncer设置的配置看起来并不简单。核心问题是同步XLOG并确保所有相关对象准备就绪。让我们一个一个地通过核心挑战。
删除与过滤对象
基本上,删除对象是相当简单。第一件事就是关掉slave以及walbouncer。一旦这样做了,那些不再需要的对象可以从slave的文件系统物理地删掉。这里重要的部分是找到那些对象。再次,这里选择的方法是挖掘系统表。所涉及的核心系统表或者视图如下:
•pg_class: 该表包含一系列对象 (表, 索引, 等等).从该表中取出对象的表示是很重要的。
•pg_namespace:这是用于获取模式的信息的。
•pg_inherit: 继承使用的信息在这表中。
没有一个关于如何找到所有这些对象的总指南,因为事情高度取决于应用的过滤类型。
准备好适当的SQL查询来找到这些必须要被删除的对象(文件)的最简单的方式是和psql一起使用选项-E,它显示在反斜杠命令后面所有的SQL代码。前端的SQL代码可以派上用场。下面是一些示例输出:
test=# \q
hs@chantal:~$ psql test -E
psql (9.4.1)
Type "help" for help.
test=# \d
********* QUERY **********
SELECT n.nspname as "Schema",
c.relname as "Name",
CASE c.relkind WHEN ‘r‘ THEN ‘table‘ WHEN ‘v‘ THEN ‘view‘ WHEN ‘m‘ THEN ‘materialized view‘ WHEN ‘i‘ THEN ‘index‘ WHEN ‘S‘ THEN ‘sequence‘ WHEN ‘s‘ THEN ‘special‘ WHEN ‘f‘ THEN ‘foreign table‘ END as "Type",
pg_catalog.pg_get_userbyid(c.relowner) as "Owner"
FROM pg_catalog.pg_class c
LEFT JOIN pg_catalog.pg_namespace n ON n.oid = c.relnamespace
WHERE c.relkind IN (‘r‘,‘v‘,‘m‘,‘S‘,‘f‘,‘‘)
AND n.nspname <> ‘pg_catalog‘
AND n.nspname <> ‘information_schema‘
AND n.nspname !~ ‘^pg_toast‘
AND pg_catalog.pg_table_is_visible(c.oid)
ORDER BY 1,2;
**************************
List of relations
Schema | Name | Type | Owner
--------+--------------------+-------+-------
...
一旦文件从基础目录被删除,walbouncer和slave实例可以可以被重新启动。请记住,walbouncer是一个用来使常规流更强大的工具。因此,slave仍然是只读的,并且是不可能使用DELET和DROP之类的命令的。您真的必须从磁盘删除文件。
添加对象到slaves
添加对象是目前最复杂的任务。因此,强烈推荐使用更安全,更简单的方法来 解决这个问题。最安全和最可靠的方法是完全同步一个实例,这需要新的对象。
简单地使用本章前面所描述的机制,以避免所有的陷阱。
总结
在本章中,讨论了walbouncer的工作,一个用于过滤事务日志的工具。除了安装过程,对所有的配置选项和一个基本设置进行的概述。
您学会了如何建立地理分布的设置。
PostgreSQL Replication之第十五章 与Walbouncer 一起工作
标签:
原文地址:http://www.cnblogs.com/songyuejie/p/5160328.html