标签:
严格意义来说,采集器和爬虫不是一回事:采集器是对特定结构的数据来源进行解析、结构化,将所需的数据从中提取出来;而爬虫的主要目标更多的是页面里的链接和页面的TITLE。
采集器也写过不少了,随便写一点经验吧,算是给自己的一个备忘。
首先是最简单的:静态页面采集器。即所采集的数据来源页面是静态的,至少采集器所关心的那部分数据是静态的,可以通过直接访问页面URL的方式获取到包含目标数据的全部页面代码。这种采集器是最为常用,也是最为基础的。目前已经有很多成熟的商业化的采集器产品,不过对我来说感觉用着有些过于复杂。一些我自己编写采集器时会注意的问题在这些产品上似乎没有,或者名字不是我拟的那个,找不到。用了几次,干脆不如自己写了,还更省时间效率更高。
准备知识:HTTP协议基础、HTML语言基础、正则表达式和任意支持正则表达式的编程工具(.net、java、php、Python、ruby等等都可以)
首先第一步,是下载目标页面HTML。
这一步并没有什么太难的,.net里有HttpWebRequest和HttpWebResponse等类专门处理,其他语言里也有类似的东西。不过需要注意的是,为采集器编写下载器的时候,参数配置一定要灵活:User-Agent、Refer、Cookie等字段都得做成可配,还得支持使用代理服务器,这是为了突破目标服务器的访问限制策略或机器人识别策略。有关常见的反机器人以及反“反机器人”等相关技术会在后续文章里专门编写。
页面代码下载到本地之后,就得开始对其进行解析。有两种解析方法
1、将其当做HTML解析
熟悉HTML的人可以将下载到的HTML页面直接当做HTML来解析,这样做也是最快和最有效率的。遍历HTML元素和属性之后,直接找到关注部分数据内容,通过访问其元素、元素属性和子元素的方式获取数据。.net里原生没有HTML解析库,可以找第三方库,大多数比较好用,至少当一般拿来解析个页面提个数据之类的够用了。唯一需要注意的是需要考虑页面代码下载不完全或者目标页面结构存在错误的情况。
2、将其当做字符串,用正则表达式解析
正则表达式的好处就是灵活,在方法1失效或者实现麻烦(比如目标数据的HTML元素路径可能不固定)的时候可以考虑。使用正则表达式的思路就是寻找目标数据及其上下文的特征或者特征串,然后编写正则表达式将其匹配提取出来即可。
以下以解析bing的搜索结果页为例,介绍静态采集器工作的基本原理。
首先是页面获取。点击两下就能发现页面参数的规律,举例:
http://cn.bing.com/search?q=MOLLE+II&first=31
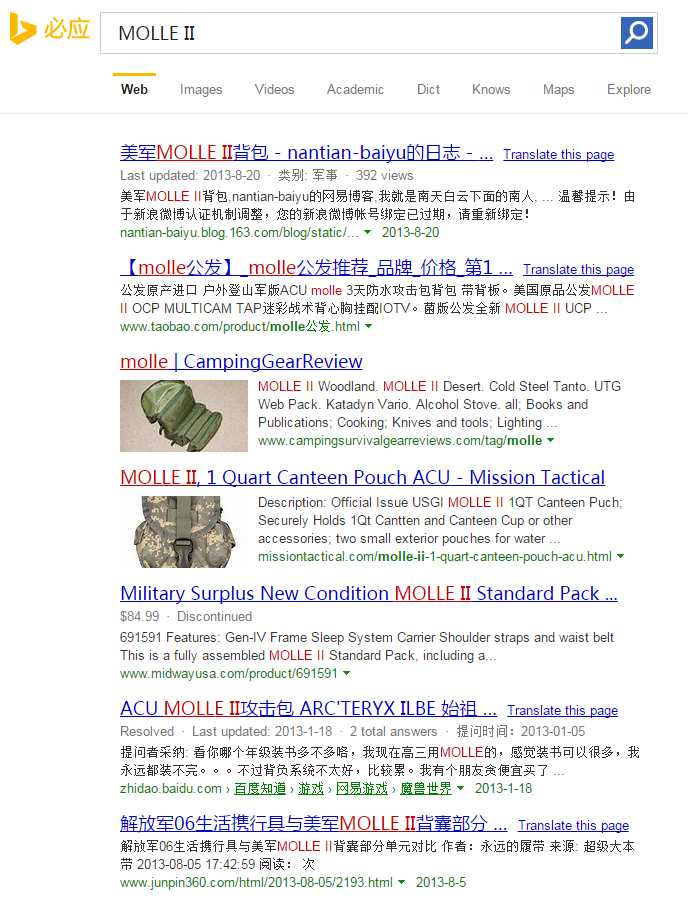
这个URL代表以“MOLLE”“II”两个关键词搜索,当前页面是是第四页。FIRST参数指的是本页第一个显示的搜索结果的索引号,第四页显示31-40个搜索结果。
这是用GET方式传递参数,大多数情况下都是这样的。如果目标页面用POST方式传递参数,用浏览器的开发者模式抓个包看看参数是啥就OK了。
然后我们就下载到了目标页面,将其在正则表达式测试器里打开:
恩,这活儿干得多了干脆自己写了一个趁手的工具。
我们的目标是提取到搜索结果里的链接文字和链接URL。对于需要从同一个页面解析得到两项或者多项相互对应的数量一样的数据,也有两种策略:根据这些数据不同的特征直接编写表达式从页面里提取目标数据(比如先用一个正则处理页面,拿到所有的链接标题文字,再用一个正则处理页面,拿到所有的链接URL),或者分析页面结构,找到包含目标数据项的最小页面结构(比如html表格里的表格行<tr>元素),再进行解析。其中后者更靠谱一点,也可以省去很多干扰,但稍微麻烦一些。以下以后一种方式进行介绍。
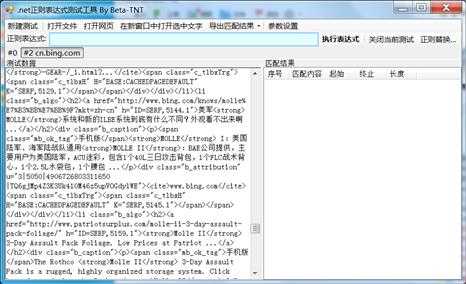
用浏览器的检查工具(Chrome里以前叫查看元素,新版改叫检查了,刚刚还找了半天)分析页面代码,我们可以发现所有的搜索内容都包含在一个id属性为"b_results"的<ol>标签里。编写表达式对其进行提取:
对于解析HTML用到的正则,零宽断言和逆序环视(查找)是经常用到的,用于提取带有特定前缀和后缀的字符串。有关正则表达式的技术博客园已经有很多相关文章,这里不再赘述。
不过需要注意的是,对于.net的正则表达式库,有一些开关需要注意。对于解析html的时候,经常需要将SingleLine参数选中,这样引擎会把字符串里所有的回车当成普通字符,而不是当成一行数据的结尾。不过这也并非绝对,也需要根据实际情况进行灵活配置。
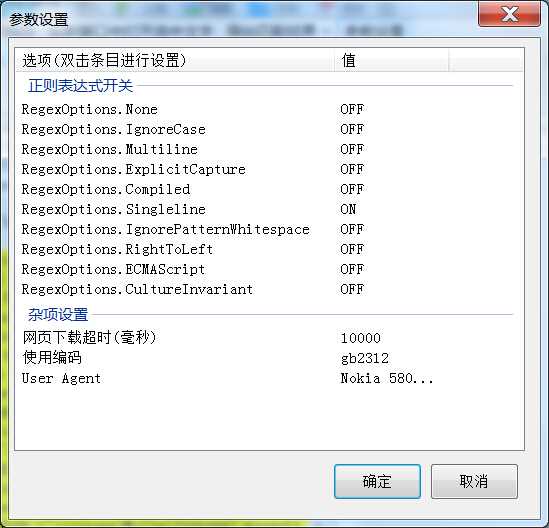
另外还有一个小技巧。在移动端盛行的今天,一些网站会根据用户浏览器请求里的USER-AGENT提供不同的页面,对手机端发起的请求就会提供手机版的页面,出于节省客户流量的考虑,一般手机版的页面会比PC端的干净一些,页面噪音更少。
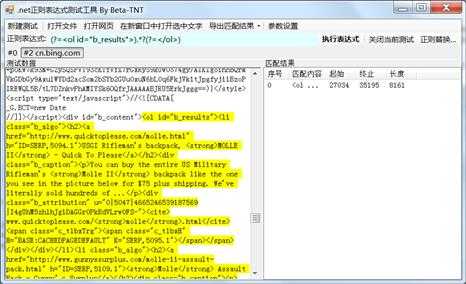
继续回到页面解析,刚刚已经找到包含所有目标元素的页面结构,实际上如果发现目标数据的最小结构的特征在页面里也是唯一的,直接提取也无妨:
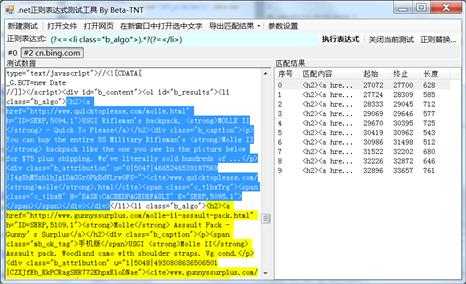
这样我们就拿到了所有包含目标数据的<li>标签的内容。顺带一提,因为截图里工具使用的NOKIA手机的USER AGENT,所以我拿到的是手机版的页面,和PC版略有不同,更干净一点。
下一步我们对每个元素进行解析。由于所有li标签的格式结构都是一样的,我们可以用同一套正则解析。
我们的目标是链接标题和链接URL,说白了,就是<a>标签的href属性和标签内容。
直接写表达式就好:
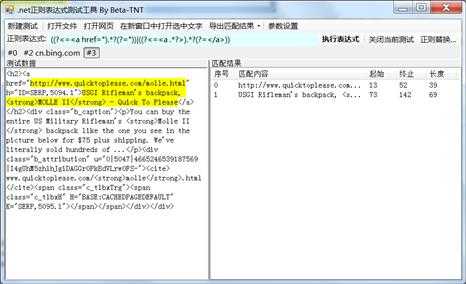
然后对于每个li标签的内容使用同样的表达式进行处理就OK了。
好了,采集器的基本原理介绍完毕,我自己写的这个正则工具可以我博客里找到,各位使用愉快,欢迎报BUG和功能建议。
下一篇将会介绍一下动态页面数据获取。
标签:
原文地址:http://www.cnblogs.com/Beta-TNT/p/5165231.html