标签:
公司需要将服务器的网页缓存到路由器,用户在访问该网页时就直接取路由器上的缓存即可。虽然我不知道这个需求有什么意义,但还是尽力去实现吧。
wget是unix和类unix下的一个网页抓取工具,待我熟悉它后,发现它的功能远不止这些。但是这篇博文只说怎么抓取一个指定URL以及它下面的相关内容(包括html,js,css,图片)并将内容里的绝对路径换成相对路径。网上搜到一堆有关wget的文章,关于它怎么抓取网页和相关的图片资源,反正我是没有找到一篇实用的,都以失败告终。
这是wget -h > ./help_wget.txt 后的文件内容
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
289
290
291
292
293
294
295
296
297
298
299
300
301
302
303
304
305
306
307
308
309
310
311
312
313
314
315
316
317
318
319
320
321
322
323
324
325
326
327
328
329
330
331
332
333
334
335
336
337
338
339
340
341
342
|
GNU Wget 1.16, a non-interactive network retriever.Usage: wget [OPTION]... [URL]...Mandatory arguments to long options are mandatory for short options too.Startup: -V, --version display the version of Wget and exit. -h, --help print this help. -b, --background go to background after startup. -e, --execute=COMMAND execute a `.wgetrc‘-style command.Logging and input file: -o, --output-file=FILE log messages to FILE. -a, --append-output=FILE append messages to FILE. -q, --quiet quiet (no output). -v, --verbose be verbose (this is the default). -nv, --no-verbose turn off verboseness, without being quiet. --report-speed=TYPE Output bandwidth as TYPE. TYPE can be bits. -i, --input-file=FILE download URLs found in local or external FILE. -F, --force-html treat input file as HTML. -B, --base=URL resolves HTML input-file links (-i -F) relative to URL. --config=FILE Specify config file to use. --no-config Do not read any config file.Download: -t, --tries=NUMBER set number of retries to NUMBER (0 unlimits). --retry-connrefused retry even if connection is refused. -O, --output-document=FILE write documents to FILE. -nc, --no-clobber skip downloads that would download to existing files (overwriting them). -c, --continue resume getting a partially-downloaded file. --start-pos=OFFSET start downloading from zero-based position OFFSET. --progress=TYPE select progress gauge type. --show-progress display the progress bar in any verbosity mode. -N, --timestamping don‘t re-retrieve files unless newer than local. --no-use-server-timestamps don‘t set the local file‘s timestamp by the one on the server. -S, --server-response print server response. --spider don‘t download anything. -T, --timeout=SECONDS set all timeout values to SECONDS. --dns-timeout=SECS set the DNS lookup timeout to SECS. --connect-timeout=SECS set the connect timeout to SECS. --read-timeout=SECS set the read timeout to SECS. -w, --wait=SECONDS wait SECONDS between retrievals. --waitretry=SECONDS wait 1..SECONDS between retries of a retrieval. --random-wait wait from 0.5*WAIT...1.5*WAIT secs between retrievals. --no-proxy explicitly turn off proxy. -Q, --quota=NUMBER set retrieval quota to NUMBER. --bind-address=ADDRESS bind to ADDRESS (hostname or IP) on local host. --limit-rate=RATE limit download rate to RATE. --no-dns-cache disable caching DNS lookups. --restrict-file-names=OS restrict chars in file names to ones OS allows. --ignore-case ignore case when matching files/directories. -4, --inet4-only connect only to IPv4 addresses. -6, --inet6-only connect only to IPv6 addresses. --prefer-family=FAMILY connect first to addresses of specified family, one of IPv6, IPv4, or none. --user=USER set both ftp and http user to USER. --password=PASS set both ftp and http password to PASS. --ask-password prompt for passwords. --no-iri turn off IRI support. --local-encoding=ENC use ENC as the local encoding for IRIs. --remote-encoding=ENC use ENC as the default remote encoding. --unlink remove file before clobber.Directories: -nd, --no-directories don‘t create directories. -x, --force-directories force creation of directories. -nH, --no-host-directories don‘t create host directories. --protocol-directories use protocol name in directories. -P, --directory-prefix=PREFIX save files to PREFIX/... --cut-dirs=NUMBER ignore NUMBER remote directory components.HTTP options: --http-user=USER set http user to USER. --http-password=PASS set http password to PASS. --no-cache disallow server-cached data. --default-page=NAME Change the default page name (normally this is `index.html‘.). -E, --adjust-extension save HTML/CSS documents with proper extensions. --ignore-length ignore `Content-Length‘ header field. --header=STRING insert STRING among the headers. --max-redirect maximum redirections allowed per page. --proxy-user=USER set USER as proxy username. --proxy-password=PASS set PASS as proxy password. --referer=URL include `Referer: URL‘ header in HTTP request. --save-headers save the HTTP headers to file. -U, --user-agent=AGENT identify as AGENT instead of Wget/VERSION. --no-http-keep-alive disable HTTP keep-alive (persistent connections). --no-cookies don‘t use cookies. --load-cookies=FILE load cookies from FILE before session. --save-cookies=FILE save cookies to FILE after session. --keep-session-cookies load and save session (non-permanent) cookies. --post-data=STRING use the POST method; send STRING as the data. --post-file=FILE use the POST method; send contents of FILE. --method=HTTPMethod use method "HTTPMethod" in the request. --body-data=STRING Send STRING as data. --method MUST be set. --body-file=FILE Send contents of FILE. --method MUST be set. --content-disposition honor the Content-Disposition header when choosing local file names (EXPERIMENTAL). --content-on-error output the received content on server errors. --auth-no-challenge send Basic HTTP authentication information without first waiting for the server‘s challenge.HTTPS (SSL/TLS) options: --secure-protocol=PR choose secure protocol, one of auto, SSLv2, SSLv3, TLSv1 and PFS. --https-only only follow secure HTTPS links --no-check-certificate don‘t validate the server‘s certificate. --certificate=FILE client certificate file. --certificate-type=TYPE client certificate type, PEM or DER. --private-key=FILE private key file. --private-key-type=TYPE private key type, PEM or DER. --ca-certificate=FILE file with the bundle of CA‘s. --ca-directory=DIR directory where hash list of CA‘s is stored. --random-file=FILE file with random data for seeding the SSL PRNG. --egd-file=FILE file naming the EGD socket with random data.FTP options: --ftp-user=USER set ftp user to USER. --ftp-password=PASS set ftp password to PASS. --no-remove-listing don‘t remove `.listing‘ files. --no-glob turn off FTP file name globbing. --no-passive-ftp disable the "passive" transfer mode. --preserve-permissions preserve remote file permissions. --retr-symlinks when recursing, get linked-to files (not dir).WARC options: --warc-file=FILENAME save request/response data to a .warc.gz file. --warc-header=STRING insert STRING into the warcinfo record. --warc-max-size=NUMBER set maximum size of WARC files to NUMBER. --warc-cdx write CDX index files. --warc-dedup=FILENAME do not store records listed in this CDX file. --no-warc-compression do not compress WARC files with GZIP. --no-warc-digests do not calculate SHA1 digests. --no-warc-keep-log do not store the log file in a WARC record. --warc-tempdir=DIRECTORY location for temporary files created by the WARC writer.Recursive download: -r, --recursive specify recursive download. -l, --level=NUMBER maximum recursion depth (inf or 0 for infinite). --delete-after delete files locally after downloading them. -k, --convert-links make links in downloaded HTML or CSS point to local files. --backups=N before writing file X, rotate up to N backup files. -K, --backup-converted before converting file X, back up as X.orig. -m, --mirror shortcut for -N -r -l inf --no-remove-listing. -p, --page-requisites get all images, etc. needed to display HTML page. --strict-comments turn on strict (SGML) handling of HTML comments.Recursive accept/reject: -A, --accept=LIST comma-separated list of accepted extensions. -R, --reject=LIST comma-separated list of rejected extensions. --accept-regex=REGEX regex matching accepted URLs. --reject-regex=REGEX regex matching rejected URLs. --regex-type=TYPE regex type (posix). -D, --domains=LIST comma-separated list of accepted domains. --exclude-domains=LIST comma-separated list of rejected domains. --follow-ftp follow FTP links from HTML documents. --follow-tags=LIST comma-separated list of followed HTML tags. --ignore-tags=LIST comma-separated list of ignored HTML tags. -H, --span-hosts go to foreign hosts when recursive. -L, --relative follow relative links only. -I, --include-directories=LIST list of allowed directories. --trust-server-names use the name specified by the redirection url last component. -X, --exclude-directories=LIST list of excluded directories. -np, --no-parent don‘t ascend to the parent directory.Mail bug reports and suggestions to <bug-wget@gnu.org>. |
根据wget的帮助文档,我尝试了下面这条命令
|
1
|
wget -r -np -pk -nH -P ./download http://www.baidu.com |
解释一下这些参数
-r 递归下载所有内容
-np 只下载给定URL下的内容,不下载它的上级内容
-p 下载有关页面需要用到的所有资源,包括图片和css样式
-k 将绝对路径转换为相对路径(这个很重要,为了在用户打开网页的时候,加载的相关资源都在本地寻找)
-nH 禁止wget以接收的URL为名称创建文件夹(如果没有这个,这条命令会将下载的内容存在./download/www.baidu.com/下)
-P 下载到哪个路径,这里是当前文件夹下的download文件夹下,没有的话,wget会帮你自动创建
这些选项都符合目前的这个需求,单结果很意外,并不是我们想象的那么简单,wget并没有给我们想要的东西
你如果执行了这条命令,会发现在当前的download文件夹中只是下载了一个index.html和一个robots.txt,而index.html文件所需要的图片也并没有被下载
<img>标签中的路径也没有被替换成相对路径,可能只是去掉了"http:"这个字符串而已。
至于为什么会这样,请继续往下看。
因为上面的命令行不通,所以,脑洞全开。来吧,让我们写一个shell脚本,名称为wget_cc内容如下
|
1
2
3
4
5
6
7
8
9
10
11
|
#!/bin/shURL="$2"PATH="$1"echo "download url: $URL"echo "download dir: $PATH"/usr/bin/wget -e robots=off -w 1 -xq -np -nH -pk -m -t 1 -P "$PATH" "$URL"echo "success to download" |
需要注意的是,我的wget是在/usr/bin目录下(这里必须写全路径),你可以使用which wget这个命令确定你的wget路径所在,然后替换到脚本中就行了。
这里多加了几个参数,解释一下:
-e 用法是‘-e command’
用来执行额外的.wgetrc命令。就像vim的配置存在.vimrc文件中一样,wget也用.wgetrc文件来存放它的配置。也就是说在wget执行之前,会先执行.wgetrc文件中的配置命令。一个典型的.wgetrc文件可以参考:
http://www.gnu.org/software/wget/manual/html_node/Sample-Wgetrc.html
http://www.gnu.org/software/wget/manual/html_node/Wgetrc-Commands.html
用户可以在不改写.wgetrc文件的情况下,用-e选项指定额外的配置命令。如果想要制定多个配置命令,-e command1 -e command2 ... -e commandN即可。这些制定的配置命令,会在.wgetrc中所有命令之后执行,因此会覆盖.wgetrc中相同的配置项。
这里robots=off是因为wget默认会根据网站的robots.txt进行操作,如果robots.txt里是User-agent: * Disallow: /的话,wget是做不了镜像或者下载目录的。
这就是前面为什么下载不了图片和其他资源的原因所在了,因为你要爬的HOST禁止蜘蛛去爬它,而wget使用 -e robots=off 这个选项可以通过这个命令绕过这个限制。
-x 创建镜像网站对应的目录结构
-q 静默下载,即不显示下载信息,你如果想知道wget当前在下载什么资源的话,可以去掉这个选项
-m 它会打开镜像相关的选项,比如无限深度的子目录递归下载。
-t times 某个资源下载失败后的重试下载次数
-w seconds 资源请求下载之间的等待时间(减轻服务器的压力)
剩下有不懂的你就去挖文档吧。
写好后保存退出,执行:
|
1
|
chmod 744 wget_cc |
OK,这样脚本就能直接执行,而不用在每条命令前带 /bin/sh 让sh去解释它了。
下面就让脚本执行起来吧!
|
1
|
./wget_cc ./download http://www.baidu.com |
下载完成后的目录结构
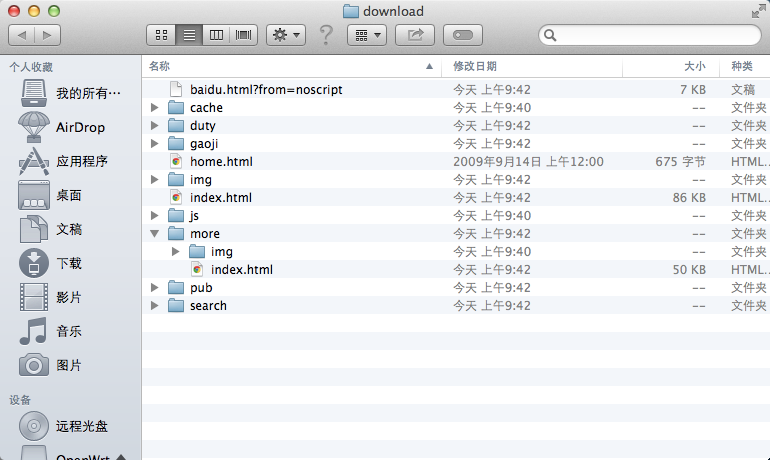
OK,然后再查看<img>标签中的src属性,
src="img/bd_logo1.png"
果然换成了相对路径啊,大功告成,觉得对您有帮助的请点个赞吧!
标签:
原文地址:http://www.cnblogs.com/archoncap/p/5166741.html