标签:
话说周围还在用人人网的人真是越来越少了,有一天闲来无事打开人人,发现最新的状态还是2013年12月的,好多好友也已经不怎么联系了,真是物是人非啊。翻了翻自己的状态,都是大学本科时发的,感觉挺有纪念意义的,就想着有空写个爬虫把自己的状态抓下来做个备份,万一哪天人人挂了,还能给自己的大学生活留个念想……
断断续续花费了几晚上的时间(真的是太慢了,orz……),写出了代码,并成功抓取了自己的所有人人状态,代码放在 GitHub https://github.com/renzongxian/backup-renren-status 上,欢迎大家提建议。运行该代码后,状态信息会保存到文件中,样式如下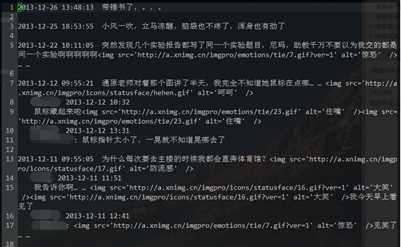
由于抓取人人状态需要登录,我参考了 http://xlzd.me/2016/01/12/python-crawler-08 和 http://www.jianshu.com/p/5c9855ca6474 这两篇文章。又由于状态信息不是直接写在 html 文件中,而是使用 XMLHttpRequest 请求服务器得到 json 数据后再对网页进行局部更新,我阅读了 http://xlzd.me/2015/12/19/python-crawler-04 这篇文章对该种情况下的抓取方式进行学习,在此感谢两位作者。
使用 Chrome 的开发者工具抓取登录过程中的 XHR 类型的数据包,如下图,可以看到 Request URL: http://www.renren.com/ajaxLogin/login?1=1&uniqueTimestamp=201604193796 ,以及请求的方式:POST。URL 最后是uniqueTimestamp,从字面意思理解是时间戳。根据参考的第二篇文章,知道它的组成为“年(2016),月(0,范围为0~11),星期(4,范围为0~6),时(19,范围为0~23),秒(37,范围为0~59),毫秒(96,范围为0~999)”,接下来就只需用 Python 中对应的时间函数表示出来,详见代码 login 函数部分。根据自己的测试,感觉人人的服务器没有对时间戳进行校验,也就是说,自己任意生成的时间戳(不一定是当前时间)也能登录成功。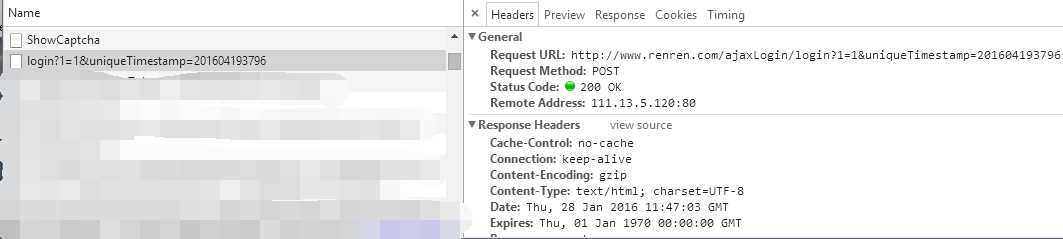
请求的方式为 POST ,那么发送请求的时候需要携带登录相关的信息,如下图所示。emal 就是你的邮箱/手机/用户名,password 是经过处理的密码,但是我也没有找到进行该处理的 js 代码,后来发现直接使用密码原文即可登录成功,r_key的值貌似跟 token 有关,但不使用也能登录,最后发现,只需要 email 和 password 两个字段就好了。然后可以根据 Response 的 Headers 是狗含有 id 信息判断是否登录成功(可能还有其他方法判断)。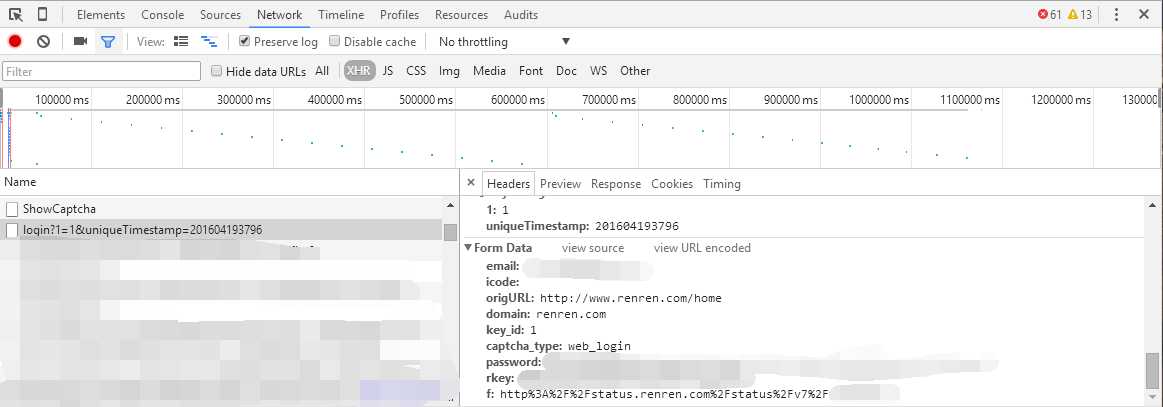
同样使用 Chrome 的开发者工具,抓取跳转到状态页( http://status.renren.com/status/v7/$id号 )的数据包,如下图所示。可以看到 Request URL 以及请求方式,由于 Request URL 中有很多参数,我将它复制下来在新的标签页里打开,然后不断删除参数,最后发现只有“userId”及“curpage”两个参数是必须的,这样就可以将 Request URL 构造出来。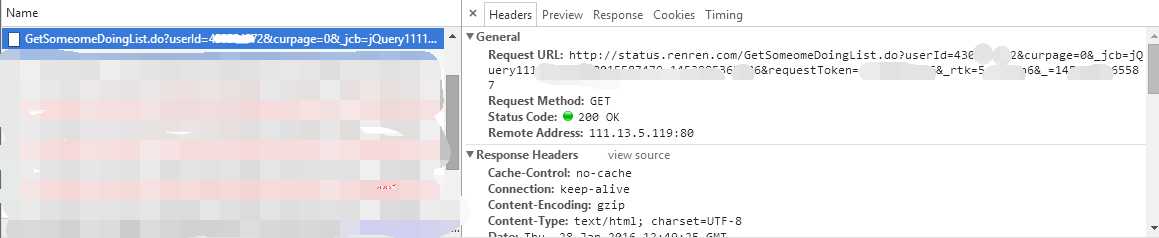
该请求的 Response 是 json 数据,通过 Preview 标签可以清楚的看到其结构,其中状态在 doingArray 中,然后,使用 Python 的 json 库可以很方便的提取自己想要的信息。我主要提取了 dtime(发表时间)、content(状态内容);如果是转发的状态,还会有 rootDoingUserName(发表原状态的用户名)、rootContent(原状态内容);如果有评论(这时 comment_count > 0),则再抓取评论,抓取方式跟状态的抓取方式类似,也是跳转到评论页时抓包得到 Request URL,然后写代码对不同的状态构造相应的评论的 Request URL 提取 Response 的 json 数据中的信息,如 authorName(评论者用户名)、time(评论时间)、content(评论内容)。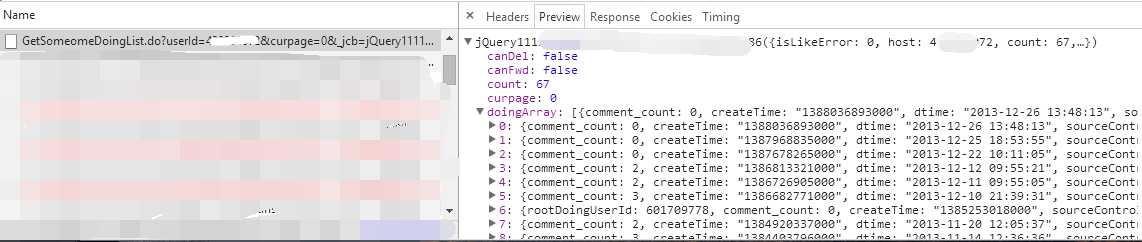
标签:
原文地址:http://www.cnblogs.com/renzongxian/p/5166745.html