标签:
异常处理
作为爬虫的抓取过程基本就那么多内容了,后面再将一些正则表达式的东西简单介绍一下基本就完事了,下面先说说异常处理的方法。先介绍一下抓取过程中的主要异常,如URLError和HTTPError。
URLError可能产生的原因主要有:网络无连接,即本机无法上网;连接不到特定的服务器;服务器不存在等。如下所示:


错误代号是11004,错误原因是getaddrinfo failed。这类错误相对来说比较少,理由是在我们抓取网页时,一般都会人工通过浏览器访问一遍,而最为常见的是HTTPError。
HTTPError是URLError的子类,在你利用urlopen方法发出一个请求时,服务器上都会对应一个应答对象response,其中它包含一个数字“状态码”。举个例子,假如response是一个“重定向”,需定位到别的地址获取文档,urllib2将对此进行处理。
其他不能处理的,urlopen会产生一个HTTPError,对应相应的状态码,HTTP状态码表示HTTP协议所返回的响应的状态。下面将状态码归结如下:


HTTPError实例产生后会有一个code属性,这就是服务器发送的相关错误号。因为urllib2可以为你处理重定向,也就是3开头的代号可以被处理,并且100~299范围的号码指示成功,所以我们只能看到400~599的错误号码。另外可能还会遇到10053、10060等状态码,一般都是服务器不稳定造成的,多刷新几次就好了。
捕获的异常是HTTPError,它会带有一个code属性,就是错误代号,另外我们又打印了reason属性,这就是它的父类URLError的属性。


错误代号是403,错误原因是Forbidden,说明服务器禁止访问。
我们知道,HTTPError的父类是URLError,根据编程经验,父类的异常应当写到子类异常的后面,如果子类捕获不到,那么可以捕获父类的异常,所以上述的代码可以改写为:
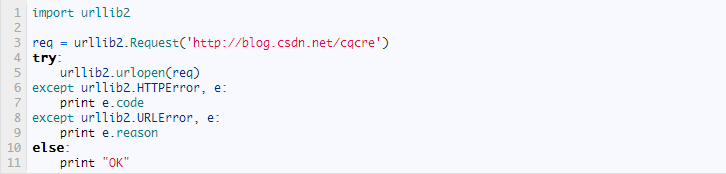
首先对异常的属性进行判断,以免出现属性输出报错的现象。
不过,就我个人而言,我不喜欢单独捕获该类异常,因为在实际应用过程中,会出项各种各样的异常,爬虫任务往往都是几天几夜的连续工作,我们又不可能24小 时盯着,所以一旦异常捕获不到就会造成爬虫程序的崩溃,而如果你还没有设置相关爬取进度的日志,这基本就是个失败的任务。所以在爬虫中,异常的捕获通常不 仅仅是报告异常的原因,更重要的是增强程序的健壮性,不至于因异常而崩溃,所以通常我的做法就是从全局角度捕获所有异常。

可以在异常捕获后记录到log日志文件中,待所有任务初步完成后,可以再对log日志里有问题的内容进行二次处理。
标签:
原文地址:http://www.cnblogs.com/timdes/p/5169472.html