标签:
转自:http://www.cnblogs.com/lanzi/archive/2010/10/26/1861338.html
OVER(PARTITION BY)函数介绍
开窗函数指定了分析函数工作的数据窗口大小,这个数据窗口大小可能会随着行的变化而变化,举例如下:
1:over后的写法:
over(order by salary) 按照salary排序进行累计,order by是个默认的开窗函数
over(partition by deptno)按照部门分区
2:开窗的窗口范围:
over(order by salary range between 5 preceding and 5 following):窗口范围为当前行数据幅度减5加5后的范围内的。
举例:
--sum(s)over(order by s range between 2 preceding and 2 following) 表示加2或2的范围内的求和
select name,class,s, sum(s)over(order by s range between 2 preceding and 2 following) mm from t2gf 3 99 198
举例:
3、与over函数结合的几个函数介绍
下面以班级成绩表t2来说明其应用
t2表信息如下:
cfe 2 74
dss 1 95
ffd 1 95
fda 1 80
gds 2 92
gf 3 99
ddd 3 99
adf 3 45
asdf 3 55
3dd 3 78
select * from
(
select name,class,s,rank()over(partition by class order by s desc) mm from t2
)
where mm=1;
得到的结果是:
dss 1 95 1
ffd 1 95 1
gds 2 92 1
gf 3 99 1
ddd 3 99 1
注意:
1.在求第一名成绩的时候,不能用row_number(),因为如果同班有两个并列第一,row_number()只返回一个结果;
select * from
(
select name,class,s,row_number()over(partition by class order by s desc) mm from t2
)
where mm=1;
1 95 1 --95有两名但是只显示一个
2 92 1
3 99 1 --99有两名但也只显示一个
2.rank()和dense_rank()可以将所有的都查找出来:
如上可以看到采用rank可以将并列第一名的都查找出来;
rank()和dense_rank()区别:
--rank()是跳跃排序,有两个第二名时接下来就是第四名;
select name,class,s,rank()over(partition by class order by s desc) mm from t2
dss 1 95 1
ffd 1 95 1
fda 1 80 3 --直接就跳到了第三
gds 2 92 1
cfe 2 74 2
gf 3 99 1
ddd 3 99 1
3dd 3 78 3
asdf 3 55 4
adf 3 45 5
--dense_rank()l是连续排序,有两个第二名时仍然跟着第三名
select name,class,s,dense_rank()over(partition by class order by s desc) mm from t2
dss 1 95 1
ffd 1 95 1
fda 1 80 2 --连续排序(仍为2)
gds 2 92 1
cfe 2 74 2
gf 3 99 1
ddd 3 99 1
3dd 3 78 2
asdf 3 55 3
adf 3 45 4
--sum()over()的使用
select name,class,s, sum(s)over(partition by class order by s desc) mm from t2 --根据班级进行分数求和
dss 1 95 190 --由于两个95都是第一名,所以累加时是两个第一名的相加
ffd 1 95 190
fda 1 80 270 --第一名加上第二名的
gds 2 92 92
cfe 2 74 166
gf 3 99 198
ddd 3 99 198
3dd 3 78 276
asdf 3 55 331
adf 3 45 376
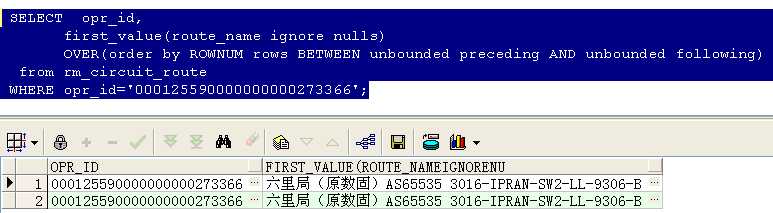
first_value() over()和last_value() over()的使用
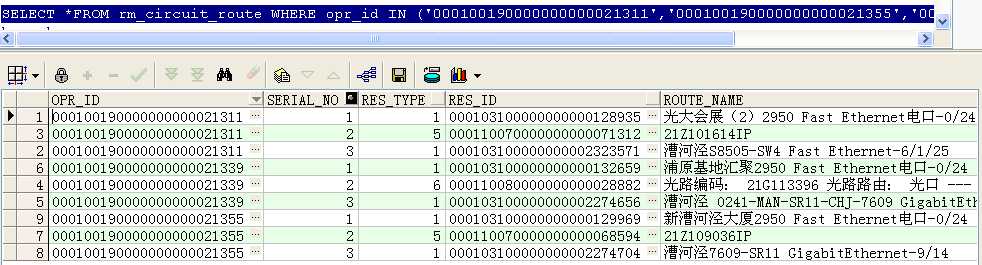
--找出这三条电路每条电路的第一条记录类型和最后一条记录类型
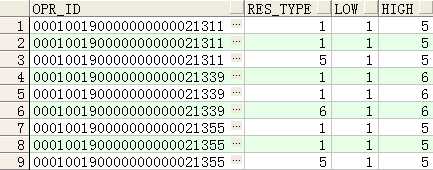
注:rows BETWEEN unbounded preceding AND unbounded following 的使用
--取last_value时不使用rows BETWEEN unbounded preceding AND unbounded following的结果
如下图可以看到,如果不使用
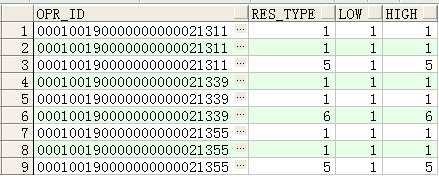
数据如下:

取出该电路的第一条记录,加上ignore nulls后,如果第一条是判断的那个字段是空的,则默认取下一条,结果如下所示:
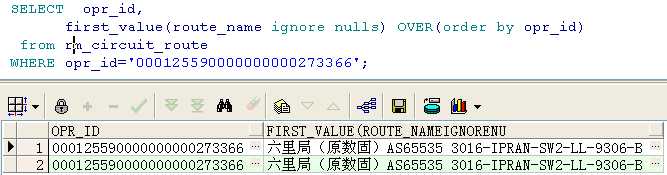
lead(expresstion,<offset>,<default>)
with a as
(select 1 id,‘a‘ name from dual
union
select 2 id,‘b‘ name from dual
union
select 3 id,‘c‘ name from dual
union
select 4 id,‘d‘ name from dual
union
select 5 id,‘e‘ name from dual
)
select id,name,lead(id,1,‘‘)over(order by name) from a;
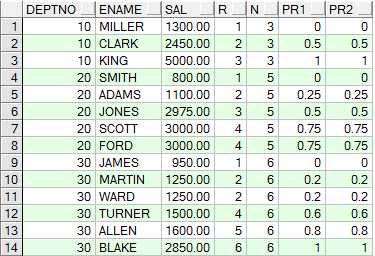
--ratio_to_report(a)函数用法 Ratio_to_report() 括号中就是分子,over() 括号中就是分母
with a as (select 1 a from dual
union all
select 1 a from dual
union all
select 1 a from dual
union all
select 2 a from dual
union all
select 3 a from dual
union all
select 4 a from dual
union all
select 4 a from dual
union all
select 5 a from dual
)
select a, ratio_to_report(a)over(partition by a) b from a
order by a;
with a as (select 1 a from dual
union all
select 1 a from dual
union all
select 1 a from dual
union all
select 2 a from dual
union all
select 3 a from dual
union all
select 4 a from dual
union all
select 4 a from dual
union all
select 5 a from dual
)
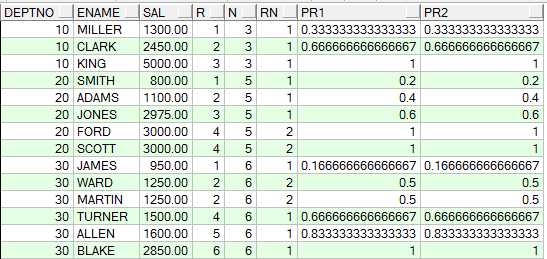
select a, ratio_to_report(a)over() b from a --分母缺省就是整个占比
order by a;
with a as (select 1 a from dual
union all
select 1 a from dual
union all
select 1 a from dual
union all
select 2 a from dual
union all
select 3 a from dual
union all
select 4 a from dual
union all
select 4 a from dual
union all
select 5 a from dual
)
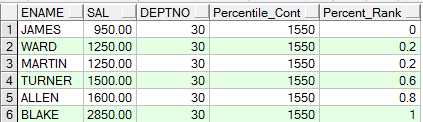
select a, ratio_to_report(a)over() b from a
group by a order by a;--分组后的占比
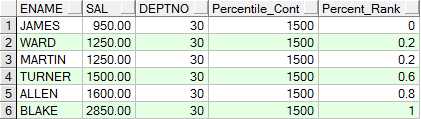
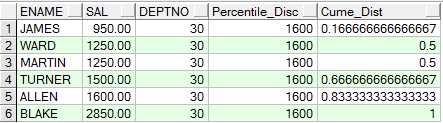
oracle下的OVER(PARTITION BY)函数介绍
标签:
原文地址:http://www.cnblogs.com/chengjun/p/5179860.html